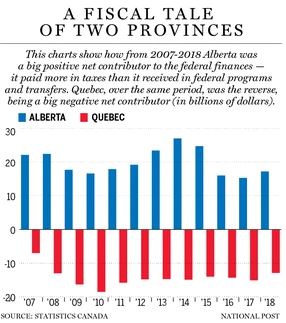
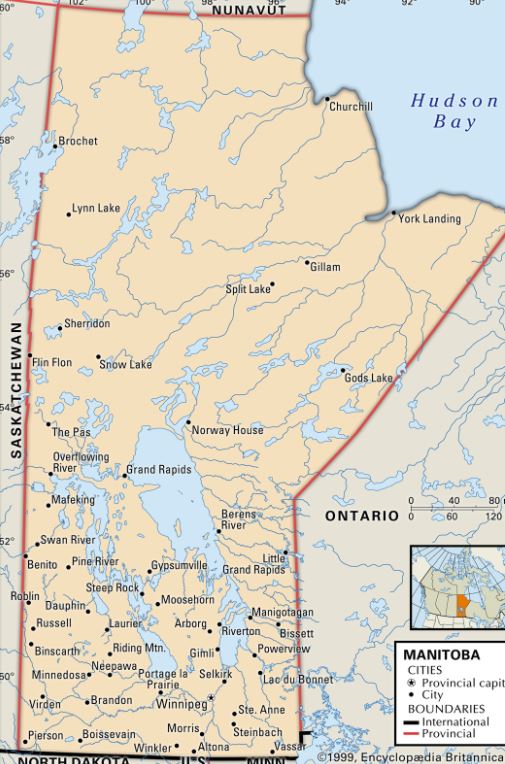
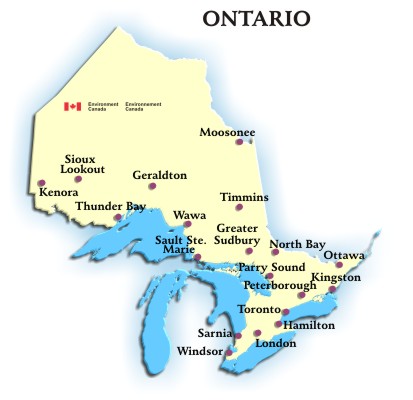
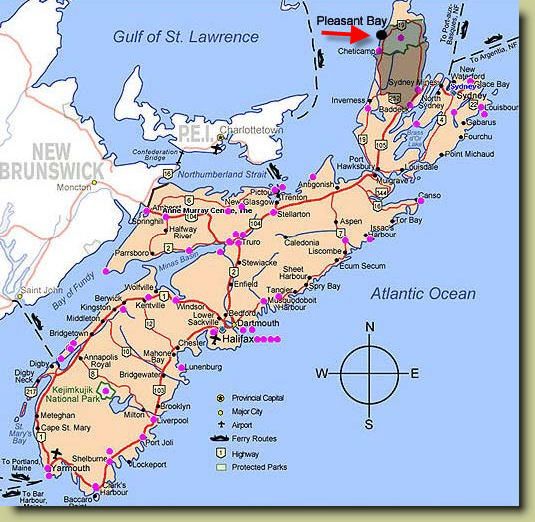
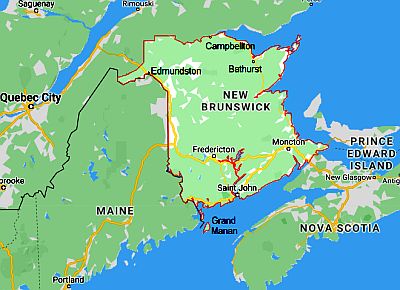
The following is a thought piece based on Mariana Mazzucato’s newest book “Mission Economy: A Moonshot Guide to Changing Capitalism”. I blend her ideas with my own, but give her all the credit for what’s below.
Introduction:
Our world is in need of some serious change.
We’ve spent the past five decades being told that governments should get out of the way, but as a result, we’ve hollowed out the core of the public sector. We’ve stripped bare the entities that serve the public interest over private profit. Our greatest risk is that we will continue to stand by idly while the current trajectories persist: growing financial inequality, more uncapped carbon emissions, systemic and intentional discrimination, widening identity polarization. If we don’t turn these four horses of the apocalypse around, we’re headed for somewhere between Mad Max and The Hunger Games. How did we get here? What can we do? Who should take the lead?
Political Economist Mariana Mazzucato recently released a brilliant book on reshaping capitalism through a more inspirational and empowered public sector. She argues that:
a) There’s a burning platform: Capitalism is in crisis
b) We drank the neoliberal kool-aid: Or, the myth that governments should stay out of markets
c) We can rise above: Governments must be the ones to inspire change through bold and decisive missions (i.e. the Moon Landing)
Below are a blend of ideas and quotes from Dr. Muzzacato mixed in with my own commentary. Please reach out if agree, disagree, or want to dive deeper on any of these ideas.
There has been incisive criticism of Mazzucato which is that she is a) an academic, b) an economist (social science is notoriously complex and counter-arguments are easily found), c) she has never ran a business, started a company or really innovated herself so what does she actually know about it…….but still her message is inspiring and it resonates.
—
A) Four Reasons Why Capitalism is in crisis
“Human activity is eroding the conditions necessary for social and environmental stability.”
1. Finance is only financing FIRE (finance, insurance, real estate).
· Global finance has become a bit of a castles-in-the-sky scheme, according to Mazzucato. 80% of financing goes back into financial firms, while manufacturing, agriculture, technology, and public services suffer. The process of price discovery and allocating scarce capital, has gotten to a point where it is too self-serving. FIRE profits are private, FIRE losses are public (a moral hazard). This destroys the incentive to innovate.
· This current structure fuels a debt-driven system and speculative bubbles that, when they burst, bring banks and others begging for government bailouts.
2. Business is focusing on quarterly returns.
· Over the past decade, 52% of the S&P 500’s net income was handed to shareholders in buybacks, and 39% of net income was handed to shareholders in dividends (that’s 91% of profits!). Rather than investing in Capital Expenditures (i.e., plants, equipment), R&D, worker training, wages, or communities…profits go to capital owners. Only 9% of returns are invested in the future.
· According to legendary GE CEO Jack Welch, “Shareholder value is a result, not a strategy…your main constituencies are your customers, your employees, and your products.” He wouldn’t last a week on present-day Bay Street.
· Most CEOs don’t have the courage to break from their quarterly earnings cycle and dedicate their strategy towards a long-term horizon (>1 year). Their boards don’t have the courage to direct them to do otherwise.
3. The planet is warming.
· If we don’t reverse our industrial policies in the next ten years, our climate breakdown will be irreversible. We’re trending for 3+ degrees Celsius, and the Global North is starting to experience what the Global South has been living with for years (i.e., wildfires and floods).
· Our economic system is set-up to propagate this trend: fossil fuels dominate our energy sources, industries are too carbon-intensive, the financial sector has fed the fossil-fuel driven economy, government is nurturing this dysfunctionality. Wholesale change is needed.
4. Governments are presiding, not leading.
· Governments have bought into the ideology that their role is simply to fix problems (i.e., market failures), not achieve bold objectives. Says who?
· Governments create and shape markets through: investment in areas like education, research, and physical infrastructure; demand generation via procurement; legal codes; and anti-trust policies. They even print the money that flows through markets. There are no markets without governments.
· Governments need to use their central role and resources to rethink corporate governance in order to broaden the range of stakeholders valued by capitalism.
—
B) Five Myths About Governments that we have all decided to believe
“Since the 1980s, a mindset of aversion to risk has filled civil servants with the fear of doing anything more than facilitating the private sector.”
Myth 1: Businesses create value and take risks; governments only de-risk and facilitate.
· It’s governments that actually make the riskiest bets, with the highest uncertainty, at the largest scales. Government bodies created the internet (DARPA, CERN), the GPS (US Navy), Siri (DARPA), and touch-screen display (CIA).
· Public institutions have lost the confidence to act and are failing to invest in their own capabilities: strategic management, decision science, and organizational behaviour.
· Decades of privatization and outsourcing have led to high costs, poor service, and the capture of government contracts by a small number of firms—billions of dollars going to consultants with little skin in the game.
Myth 2: The purpose of government is to fix market failures.
· Market failure theory (MFT), evolved from microeconomics, argues governments should only intervene when markets break down (i.e. positive externalities, negative externalities, information asymmetries). Under this theory, however, markets are in perpetual failure and governments should always be intervening.
· Public choice theory (1960s) pushed this idea further and said that government failures are worse than market failures. They assumed that policymakers and bureaucrats were purely self-interested and prone to corruption and ineptitude. How Hobbesian.
· But government spending doesn’t crowd-out investment, it crowds it in. It creates spaces for innovation and collaboration between parties that would never occur in pure competition. It takes risks that businesses never would, driving the world forward.
Myth 3: Government needs to run like a business.
· New Public Management (NPM) arose in the 1980s in business schools to suggest that there should be a profit-motive involved in government to make it more efficient. It caught on during the Thatcher-Reagan-Mulroney years and spread across the globe in the 1990s.
· NPM led to deregulation (encouraging risky behaviour), shareholder value (enriching executives at the expense of long-term investment); and outsourcing (leading to loss of public control over the quality of services and products). But at least it made some shareholders richer.
· NPM assumed that the public sector suffers from a principal (citizens) – agent (bureaucrats) problem: citizens can’t hold the public sector accountable the way shareholders can a corporation. But besides voting, the public sector is often held to a much higher standard than the private sector.
Myth 4: Outsourcing saves taxpayer money and lowers risk
· The gutting of the public sector over the past five decades has led to management and IT consulting firms taking over increasingly larger roles of developed governments. The problem is, they often suck at it, and they cost 1.83x more than experienced civil servants (in the US).
· In the UK, the National Accounting Office estimates that a typical project with PFI (public-finance, private delivery) is 40% more expensive than if done in house. Consultants suffer from a worse principal-agent problem than civil servants: they serve profit, not citizens, and are incentivized to drag out engagements (see Phoenix Pay System).
· This trend has encouraged developing countries (pushed by the World Bank and IMF) to privatize and outsource key services (i.e., waste collection, school meals, building maintenance, prisons, and even ambulance and probation services). All while economists and political leaders continue to push for smaller governments and balanced budgets.
Myth 5: Governments shouldn’t pick winners.
· A government that lacks imagination will find it more difficult to create public value.
· Industrial policy is the policy of picking winners. Policymakers need to make decisions, and of course, they must pick things. Their choices could include seizing technological lead in a sector, diffusing knowledge, creating jobs, raising productivity and incomes, boosting regional development, and defence.
· The real problem is the practice of socializing risks and privatizing rewards. The same year the US government made the $535M guaranteed loan to Solyndra, it made a similar loan of $465M to Tesla—now a global leader. Somehow the $4.9B in government loans received by Elon Musk’s three companies is left out of his narrative as a daring entrepreneur.
—
C) Governments must take a “missions” approach to solving society’s grand challenges
So what do we do about it? Muzzacato dedicates the second half of her book to this question. First she uses the Moon-landing as an example of an inspiring “mission”, which not only rallied the public and private sectors to achieve a historic feat, but also inspired innovation and invention that spilled over into countless markets, benefiting all of society (i.e. camera phones, athletic shoes, foil blankets, dust busters, baby formula, wireless headsets, artificial limbs, computer mice, portable computers, freeze-dried food, CAT scans, smoke detectors). Second, she asks us to “aim higher” by selecting ambitious and inspiring missions for our society to tackle, led by governments, such as implementing a Green New Deal, innovating for accessible healthcare, and narrowing the digital divide. Finally, she concludes with seven principles for the New Political Economy, summarized below.
Seven Principles for the New Political Economy
“Real progress will only happen when stakeholder governance and ‘purpose’ become central to how organizations are governed and how they interact.”
1. Value: collectively created
· Our dominant economic framework rests on the assumption that people maximize their own preferences. This is not always true (i.e., Prospect Theory). We must believe in the value of public purpose and its ability to serve the public interest. This starts with openly caring about more than our individual interests: the term “idiot” comes from Greek, meaning “someone who does not operate in the public sphere”. Are you an idiot?
· Public goods are worth more than their costs. They have “multiplier effect” impacts that echo through society.
· We need business, government, and civil society to create value together, with none being relegated to cheerleaders of the other.
2. Markets: shaping not fixing
· According to Market Failure Theory, governments should only step in to correct market failures: positive externalites (under-investment by private sector—basic research), negative externalities (pollution—carbon taxes); asymmetric information—(banks’ risk appetite—loans to SMEs). But MFT also operates under the assumption that markets are perfectly competitive. They are not.
· Governments must actively “co-create and co-shape” markets. They must go from market fixing to market shaping; being proactive rather than reactive. Markets are dynamic, even if economists believe they operate in a vacuum.
3. Organizations: dynamic capabilities
· A theory of innovation needs to be nested in a theory of learning, experimentation, and adaptation to uncertainty. Learning by doing is a key element in improving an organization’s fitness and developing “absorptive capacity”. This must be adopted in the public sector. Its okay to take risks.
· Public organizations must find new ways to create and implement strategic actions (i.e., leadership capabilities, engaging with groups), rethink how civil service is developed (i.e. training, performance assessment, promotion), and re-imagine how work in public organization is managed (i.e., cross-sectoral, iterative).
4. Finances: outcomes-based budgeting
· The “urgency to win” means funding is always available for wartime missions and crises. There is no reason why the “whatever it takes” mentality cannot be used for social problems. What if budgets were based on outcomes to be reached instead of haphazard cost-benefit analyses?
· Public sector deficit is private sector surplus. National debt, which so exercises many politicians and citizens, is actually the historical accumulation of money spent by government, not taxed back, and now a privately held asset. Government red ink equals private-sector black ink. Debt is okay.
· Government spending only runs into problems (i.e., inflation) when there’s no growth in the economy. Financial institutions are the last place it should go. Instead, some key factors that increase productivity include education, research, science-industry linkages, worker training, and patient (long-term) financing.
5. Distribution: sharing risks and rewards
· Wealth is created socially: all inventions stand on the shoulders of giants, which likely stood on the backs of public sector investment. We must move from redistribution to predistribution: collective ownership structures, government equity in companies (preferred shares), and stable employment.
· Government loan guarantees and bailouts should have more conditionality. Public risk and private profits erodes faith in government capabilities.
6. Partnership: purpose and stakeholder value
· The notion of “purpose” and stakeholder value is not only about changes to corporate governance but is also about the details of contracts between business and the state.
· Stakeholder value means weighing the importance of workers, communities, and environments alongside shareholders. In Scandinavia, trade union members sit on boards to help steer investments and remuneration. Meanwhile in Canada, nearly all corporate entities have busted up their worker unions. No wonder >50% of jobs are part-time or contract.
7. Participation: open systems to co-design our future
· Mass publics are deserting the old-line, oligarchical political organizations that mobilized them in the modernization era—but they are becoming more active in a wide range of elite-challenging forms of political actions (a renaissance of democratic engagement).
· New decentralized forums are needed that bring together different voices and experiences, such as citizen assemblies.
These are academic notes from my days at McGill University. Enjoy!
Conservative Party of Canada
Discussion: Conservative Party of Canada
aspects of conservative ideology
past
emerge from larger quarrel between landed rural aristocratic vs newly urban mercantile power
traced to the aftermath of english civil war tories supporters of the crown and church of england
Tory used as an isult to those more supportive of the crown than parliament and the anglican church vs other protestants
then put to loyalist in US
french revolution; got a bust from Bruke, reflection on french revolution 1790, if reform in the absract not a bad thing it had to be done in a gradual organic way
argued that a society was the product of a slow and infinite process of historical dvp, the revolution in france were wrong to throw out the old for something new
aftermath of french rev. Cons upheld of the institution of aritotacracy, monarchy and church power, oppose constitution and reps. Gvt (cont europe)
William Pitt premier, revived tory faction dominates parliament. This tory faction was united in its opposition to the French rev and the tinkering with time honored english institutions
split in 1820’s of rights of protestants and christians
tories later accepted the reforms of the whigs,
say taht there tasks was to maintain what remained of the institutions
tory democracy, Disraeli argued that the tory aristocrats and the not liberal plurocrates where the real friends of the workers, and to bridge britains social class differences due to there acceptance of hiearchicahl
moderate vs radicals squable gave the liberals there win, du to claiming the middle ground, ended up being a more moderate vs a more radical version of liberalism
1830’s in the US the american whig party (more cons, than british) aruged that it was natural for a few to have the wealth and power
acused democrates, who advocated more liberal democracy, as putting the poor vs the rich and pandering to the riches
British North American context, 1791 constitional act
british reaction to weak exectuive power in the american colonies, by strenghtening hte aristocrates and the monarchy
realtively weak elected assembly
Horrowitz argues taht there was a tory influence in Canada’s political culture, a tory touch was imported by the loyalistes, tories rejected american liberalism due to its emphasis on democracy and individual
tories had vision of an organic community that required the sacrifice of individuals critisized thtat there is little evidence of tory connection between the tories and the conservatives of the 19th century
Hrrowitz accused of abusing the term of tory, trying to force all political ideas into black white, liberal conservative argument when there was a lots of shade
paints tories and paternalistic aritocrats
Cdn tories were simply a self seeking elite concerned about enriching htemselves and there family, (Smith, Stewart)
not champions for a common good, but of an individual ideology to willing to sacrifice common good for own individual powers,
building personal fortunes at public expenxe
1820s and 1830,s were associated to chateau clique and family compact, leaders of busines elites that were aligned with monarch, hostile to dem, this group was dubbed tories, simply conservative liberals using ties to the crown to promote own interest
there version of liberalism was more conservative that the US version but was still liberal
Patriotes; embraced the american democratic ideals , but rallied agaisnt commercial linked power,civi humanist values, wanted to maintain agricultural community to stop from bads of capitalist industries
The reinvigoration of the catholique church
they had opposed papino du to anti-church, they came and favored a partnership between churhc and state rather than subordinate role
1871 programme catholique, rejectied principle of church and state and to oppose liberalism as a political doctrim, catholiques were ordered to vote for conservative (certain) or abstain
Castors or Programiste advocated a mroe exclusionary approach to politics
rise to present
achievement of resp gvt in 1840’s fundamental change to united provinces, Baldwin and Lafontaine alliance began to fray
out of the ashes of realignement , BNA tories began to moderate and a more central liberal coaltion came to be and included, conservative reforemers known as the bleu and a handfull of tories in the west, the new party liberal conservative party lead by August-Nobert Morin and McNab, they realised that if they wanted to keep power
they need to put french and english interest together succeded by MacDonald and Cartier, leader of the bleu,rep stable majority of french people and english business leaders (wanitng to keep montreal as business centre)
the MacDonald tories had a pro-british anti-us vibe
opted for equal treatement of religions, gained support of catholic church and the main anglican denomination, even the anti-catholic orange
bi-cultural linked together by powers and the spoils of econ force that it would create. Liberals conservative became champions of a united BNA, unstable leg was reason for wanting new politicla order to have more stability to have better econ evolution
using patronage and nationalism claimed to be the natioanlist party and formed gvt in the gvt of the dominion, gained tupper tiley in the Maritimes
years after confederation
Carties dies in 83 but coaltion surives and dominates first 30 years of Dominion they were in power and controled patronage and other therefore able to increase its influence in both western canada and maritimes, closely linked to business community and railroad, became firts national party
earned a reputaion for a party of great enteprise and the interest of the nation at heart
it was these great enteprises and its close link to business interest htat caused the CPR scandal, Sir John A got donations from a company that was bidding to build the CPR,
fell from power but in 1878 elections the conservative regain power by successfully identifying with the cause of nation building through the NP adoption of protectionist tarrifs, rapid construction of national railway to have east west economy and increased immigration in the west
description of liberal conservative party as the canadian party these econ policy mades sense due to recession and please Montreal and Toronto businessmen
Macdonald vision of Canada was focused on created an industrial power, link to industrial power and loyalty to hte flag, the NP was being sold as a benefit to all Canadians but benefits were better for some
1891 elections ultimate example of cons as nation building rampid anti US and a lot of NP, claimed liberals could not be trusted with country and power, they said that there policy would result in the absorption of Canada in the US exemplified in the old flag, old policy the old leader, poster suggest common national purpose, tories won 1891 elections but MacDonald dies, beginning of crisis and downfall of conservative power, crisi for dominion as well
cons and Macdonald identified as nation building
John Abbott was chosen as leader because he was not particularly obnoxious, quickly replaced by Thompson who dies 94, then Bowell replaces then in 96 Tupper takes the healm, conservative fall to the Liberals
victim of its own success, had succesed on one hand but then it could no longer act as a bridge builder between regions and econ interests
cons had emerged as the centralizing power and party now faced liberal provincial rights movement of Mowatt and Mercier and liberals ran 4 major provinces, then loss of quebec meant that the cons lost there base of power loss of power in manitoba and NB due to language questions
with death of Cartier bleu and castor unity was hard to keep castor became a virtualy autonomous party
Chapleau came closest to replace Cartier, believe in econ dvp and benefits for montreal interested in nation building
never succeded in gaining Cartier level of influence and unity (1880’s) controversy over NWR and Riel, increasing tensions between french and english fraction the cons party, church hierarchy starting to oppose them as well due to some moderates,
this moderation of opinions opens door to liberal
Chapleau given minor portfolio in Abbot gvt and took in personaly left Abbot and cons very weak in Quebec
Manitoba school question made Chapleau leave the cons caucus still refused to return due to lack of remedial legislation adn that he could see the writting on the wall
MacDonal was able to keep factions together but no other leader was able to keep the protestant english imperialist vs french catholics business
it did this by focusing on territorial and econ expansion, became more dificult with time
after death reatreated to protestant base and open doors for moderate liberals
mistake to confuse conservative party and toryism
the fundamentally ‘whiggish’ nature of Conservative party consistant with liveral ideology
the conservative party
most succesfull due to attaching itself of national intergration19th century
then when it reached its max they were’nt able to keep power
Ideological Currents (2): Liberalism in Canada
Although liberalism became entrenched as the dominant ideology of the Canadian political order in the 19th century, the Liberal Party was slow in emerging as a potent political organization;
It was only as debates over liberalism in Canada came to be resolved in the latter years of the century that the Liberal Party was able to establish itself as a national political party;
The other crucial element to the rise of the Liberals as a national party was that, consistent with their ideological similarity to the Sonvervative Party, the Liberals adopted their core policies and became identified with the process of national integration. The result was that the Liberals were able to replace the Conservatives as Canada’s dominant national party.
John Locke
Liberalism can be traced to John Locke
an industrial bourgeoise ideology, a bid for a share of the power in British aristocracy
Liberalism varied from country to country
at its core, Liberalism is reflected by the notion that man is able to govern himself and control himself, so it is opposed to absolute monarchy and advocates parliamentary or representative government, bound to the rules of law, subscribed to the notion of natural rights (foremost of which is property that includes life and goods)
tended to advocate laissez-faire (minimal governmental involvement in the economy) including free trade at the international level
Liberalism in Government
until the 1840s it was kind of an insult to be called a Liberal
mid to late 1860s, the British Liberal Party became well-established
ideas carried by the French Revolution
in the United States, liberalism was at the heart of the political culture, e.g. Jacksonian democracy “Equal rights for all, special privilege for none”
don’t equate liberalism with democracy, not all liberals were democratic, e.g. they did not all support universal suffrage, that only is accepted later
Mill
standard manifesto of human rights
The Canadian Case
liberalism influenced the reforms, the reaction against the colonial government
argued that the BNA Act entrenched an oligarchy
American Republican ideology influential
Mackenzie sympathized with Jacksonian ideal, reflected in demands for elected legislative
calls for responsible government
like British liberals, wanted to extend the democratic franchise, wanted to turn appointed positions into elected ones, wanted to inform the constituents and have equal votes
British North America class largely subscribing to liberalism
Ian MacCae
writes of the emergence in BNA of “liberal order” that sought to realize the political and economic principles
argues that liberty, equality, property, became the dominant philosophy
argues that liberalism is a secular religion
the interaction of ideas in liberalism imported from the UK and America
notes that this was a very highly qualified type of liberalism, champions the cause of the individual, but with limits, e.g. who has a stake in society (those with property, only men, no Aboriginals or Japanese or Chinese…and only some Catholics, only some French)
The Rise of the Liberal Party
like the Conservatives, can trace its roots to the Baldwin-Lafontaine union breakdown
Clear Grits based out of southwestern Ontario including Toronto, inspired by American liberalism, championed by MacKenzie, challenges the coalition for being too elitist and conservative
“grits” a Masonic term to build a better society
Clear Grits especially upset by undue French Catholic influence, so advocated “representation by population”, banking on western Canada being able to dominant eastern Canada based on population growth, in contrast to equal representation for eastern and western Canada
Clear Grits protested big business in Montreal
there were also more moderate reformers led by George Brown, editor of the Toronto Globe, drawn from British liberal tradition, representation by population, supported by Toronto business
“the Rouge” were led by Papineau, members of the professional class of the Canadien population, influenced by French liberal tradition, especially 1848 Revolution, were nationalist Canadien, had favoured BNA’s annexation to the US as a means to Canadien self-government, opposed Confederation which they saw as subjugation of the Canadien, strong anti-clerical
mutual excluding agenda of French and English made it difficult for the party emerge against the Conservatives
coalition led by George Brown and Antoine Aime-Dorion: the Reformer Liberals, to bring about the confederation, but it broke down
in the first decade of the Confederation there was no Liberal party, simply a grab-back, united only in their opposition against the MacDonald government which was forced to resign from a scandal
1874 the Liberals led by Mackenzie (not William) argued for a more moral, limited, frugal, government, made up of Ontario liberals (inspired by British liberalism) and the Quebec Rouge, which had moderated themselves to accept federalism and the Canada Firsters, a group of independent nationalists who had criticized Macdonald for the coercive means of consolidating Confederation (including William Blake, former Ontario premier) and the Ministerialists, who supported the government only to be on the government’s side of the house, previously supported Macdonald
the Canada Firsters quickly turned on Mackenzie for not doing enough to strengthen and consolidate the new dominion
this all prevented emergence of a strong party, no strong cabinet, uncharismatic leader
but did enact a number of reforms, e.g. new military college, the Supreme Court of Canada, did away with non-simultaneous elections, the secret ballot
took office in 1874 just as an economic recession began, government took a slower pace in building the railway, BC threatened to separate, by 1878 the coalition is turned out of office
two years later, Edward Blake succeeds Alan Mackenzie as leader
still not a truly national party, still Ontario-oriented, issues still had little attraction outside of Ontario
Blake broke with tradition in a couple key areas: tried to break the anti-Catholic, anti-French sentiment and the support for free trade (went closer to Macdonald)…but still was lacklustre
took the leadership of Laurier to forge the factions into a party
The Laurier Liberal Party
Laurier was a former Rouge but his views on liberalism had evolved to espouse British liberalism over American liberalism of the Clear Grits
reflected in his speech in 1877 that responded that denounced the execution of Louis Riel and came to be seen as a better protector of French Canadiens
continuing tough economic times in 1880s weakened support for Macdonald
Laurier called for the abandonment of the protectionist tariff and called for free trade, result was the liberal defeat in 1891, for leading Canada into the arms of America, adopted to calling for less restricted trade (ambiguous) and won back power
they come to power as economic boom begins, Liberals benefit, emerging trans Canada economy, economic nationalism is the one issue amongst with Canadians will rally around, so the Liberals adopt it as their own, back the construction of two new trans continental railways (in addition to the CN), a liberal business alliance based on urban centres, new immigrants voted for Liberals, the party of state building and national consolidation, also successful because they were increasingly able to count on support from Quebec, shed their anti-French heritage in Ontario, reflected in Mowat’s policies in Ontario to benefits Francos and Catholics in Ontario, also benefited from the decline of the Conservative party’s fortunes, able to attract moderate Quebec Conservatives like Chapleau and Tarte, the party of French-English cooperation
the change of government in 1896 was primarily a change of names rather than of policies or leadership styles, the triumph of liberalism in Canadian political culture, whether liberals associate with either party, all of these individuals espoused classical liberalism from Britain adopted to BNA realities, as long as they continued to represent the rural farmers they were no match for the business-minded Conservatives, Mackenzie had failed because he had not granted enough consessions towards this group, only won with agrarian support, switched their support to the Conservatives and brought them back to power (?)
The Two-Party System
both parties were ideologically similar, convergence to the centre, as party became more national it was less likely to take a position that would offend a side, gaining power was contingent on appeasing all
by dawn of 20th century, a two-party system like America’s, where each party seeks the support of all, a state-building party, a party of national consolidation
Getting the Message Out: Politics in the Early Mass Media
Main Arguments:
The emergence of political parties and the press in Canada were intimately linked. Politicians and parties relied on the partisan press to get their message out, and the partisan press benefited from government and party patronage.
Although close, the party-press relationship was conflict-ridden. (Still is.) While the emerging political parties strove to obtain and maintain newspapers that would be their mouthpieces, this was increasingly problematic as newspapers moved to assert their independence.
Canadian political parties and the press were linked by, and owed their parallel rise to the ideological ascendancy of liberalism, however, the implications of liberalism, especially liberal capitalism (e.g. market forces), contributed to the undoing of the Victorian-era relationship between press and party.
Greavance
Outline:
The Party-Press Relationship up to Confederation
The Party-Press Relationship after Confederation
Evaluating the Party-Press Relationship: The Significance of Patronage
Evaluating the Party-Press Relationship: The role of Party Organs
Conclusion
Up to Confederation
by 1858, the province of Canada was served by 20 daily newspapers, 18 tri-weekly newspapers, 15 semi-weekly newspapers, and 156 weekly newspapers (a lot!)
the sole medium of mass communication
editors frequently found themselves catapulted in political careers
politicians frequently found it necessary to become owners of papers
how many politicians got their start in journalism? included William Lyon Mackenzie and George Brown (founder of the Toronto Globe, which became the voice of the Clear Grits) and Alexander Mackenzie and Wilfrid Laurier
the newspaper provided politicians with political education, organization
growing importance that politicians attached to newspaper support is evident in the increasing funds spent on newspapers and printers, 1/5 of government spending in pre-Confederation Canada, an important source of revenue that encouraged close cooperation between the parties and press
this accomplished 3 important tasks:
created a communication system that could tie together local supporters, keep them informed, essential to party cohesion
propaganda instruments, boosting party leaders and their policies
endless critique of a party’s opposition, a means to build up and a means to put down
After Confederation
partisan papers defined the party line, advertised for the party, and for the emerging party system
an uneasy institutional marriage
in the mid 1880s, 37 weekly and daily papers went to the PMO
schmoozing, flattering, patronage towards the journalists
journalists were power brokers, clients and bosses
Brenton McNabe claimed his active political work on the Conservatives was integral to his journalistic duties, they were one and the same, one fed the other
adopting a party name gave a paper instant readership
partisan politics was just another complication that had to be dealt with
dominance of the partisan press
most centres had both a Liberal and a Conservative paper
only 6 newspapers were allegedly independent
the strength of the partisan press suggests that 19th century newspapers were the handmaidens of political parties
fear and greed
but don’t overstate matters
the partisan stance of many newspapers was often little more than a marketing strategy
there are too many examples of allegedly partisan newspapers of criticizing the parties to whom they were supposedly subordinate to make the claim that they were subordinate
The Significance of Patronage
the political operators?
newspapers continued to receive subsidization after Confederation
parties punished and rewarded their enemies and friends
in 1880, an editorial denied that subsidization meant subservience, because the rising operating costs of an urban daily newspapers far exceeded any patronage obtained from the government
in the years that followed, evolution
papers service a commercial market and cannot survive on patronage alone, e.g. management important
significant patronage only a pipedream
the fact that patronage was declining in the importance in newspapers is seen in the fact that even if the party in power changed, the stripes of the papers didn’t change, they stuck with the original ideology
Toronto Mail, a Conservative newspaper, became increasingly assertive, Sir John A. tried to increase funding towards it and then tried to withdraw it but neither technique prevented it from criticizing the Conservatives
the emerging highly competitive market conditions outweighed the benefits of patronage
checked the practical control that politicians had over papers
disappearance of scores of local papers and increase in urban dailies
The Role of Party Organs
e.g. The Toronto Globe, which had a unique status in the early Liberal Party by serving as the mouthpiece of the Clear Grits
Clear Grits “the party of the newspaper” (shows how great the paper was)
e.g. The Montreal Gazette championed the cause of McDonald’s Conservatives
Edward Blake went to extreme lengths to preserve the Toronto Tribune with the aim of making it court the Catholic vote in Ontario
ensures a party voice during elections
in Saskatchewan, the provincial Liberal government of Thomas Scott established a German language paper, the Saskatchewan Courier, to court to Germans (second-largest immigrant group) to the Liberals
in Quebec in 1880, Wilfred Laurier established L’Electeur (later Le Soleil) and financially backed it, issued almost daily directions, had control over its editorial policy
La Patrie taken over by a Liberal Minister
Le Canada established by the Liberals as a mouthpiece in Quebec
La Press established by the Conservatives
William Lyon McKenzie King tried to establish a paper in Ottawa but failed, showing that the concept of the party organ (which oversimplifies a complex relationship between parties and press) was over
they sponsored newspapers, they gave patronage, they retained control over editorial policies
after 1880, only the Toronto Empire was an organ, no other paper in Ontario that filled the profile:
in the hands of a few politicians
regular and direct intervention in the editorial policy by the party
complete financial dependence on the political party
The Undoing
exercising a more independent role
resisted by the politicians
concept of party organ implies a degree of centralization and resources on the part of the parties that in reality did not exist at this time
difficulties that both parties had in maintaining a party organ in the Toronto market, seen in effort to control the Toronto Mail, the Toronto Empire (in course pack)
growing ideas of professionalism and the dictates of Liberal capitalism were seriously diminishing the scope and value of partisanship
editors came to resent the image that politicians were subservient
result is a deterioration between the Toronto Globe and the Liberal Party
Toronto Evening Star (becomes the Star) was to be the new Liberal Party organ
efforts by political parties to ensure reliable mouthpieces in the media were in fact declining, costs outweighed benefits
the only way that political parties could retain their influence was if that newspaper was not commercially successful (i.e. nobody was reading it and it needed cash)
this ran counter to the principle of a party getting involved in a newspaper, it would be pointless if no one was reading it, even if circulation increased, the importance of the funds they were getting declined in the ratio
also problematic for the continuation of party organs was the evolution of the newspaper business, the number of dailies had peaked, rising costs of running one, intense competition, urban markets could no longer support multiple papers and small communities could not even support one
evolved from being an advantage to a disadvantage
papers needed to be non-partisan, if there’s a limited number of readers, you need to broaden your circulation, to remain partisan denied growth
also related was an increasing professionalization of the newspaper business, a separation between the journalists
as a result, the partisan nature of the Canadian newspaper business began to decline
Canada’s political parties did not have the resources to prevent this
the leadership of the two political parties was isolated, one less means by which to get their message out, they were now denied a primary vehicle of communication
ultimately this disruption of the Victorian era relationship contributed to the organizational weakness of the two national parties
it also undermined electoral support, lost the propaganda machine
“Not Won by Prayers Alone”: The Patronage System
It is impossible to understand the emergence, consolidation, and functioning of Canadian political parties without examining the role of patronage. The two national political parties relied on patronage to expand and strengthen their presence throughout the Dominion. In so doing, patronage became an important vehicle of national integration.
The close ties between political parties and the business sector were reflective of the centrality of patronage in helping spread and establish the liberal project in Canada, but also led to a number of scandals.
While patronage served an integrative function in terms of both political parties and Confederation, it also (paradoxically) reinforced parochialism and led to the neglect of crucial issues about the nature and operation of the Confederation project. Increasingly, the patronage system could not be sustained in the face of Canada’s linguistic and regional cleavages, and the country’s socio-economic evolution.
Background and Patronage in BNA
what is patronage?
e.g. Walpole using appointments to organize core supporters in British parliament
Andrew Jackson did away with permanent positions and introduced the concept of turnover to democratize the civil service and avoid entrenched corruption, known as Jacksonian Democracy, contrasts to the Canadian case, lead to the “spoils system” and the emergence of the phrase “to the victor belong the spoils”, allowed Jackson to organize his supporters and reward them with public office appointments
in BNA at the heart of responsible government debates, who should control patronage, the transfer of patronage from those who wielded it to those who wanted it, gaining access to the spoils of power, encourage participation in emerging party system, if you want something accomplished (political favour) you have to go to the party in power, a sword of revenge against political opponents, a threat to keep supporters in line, the result was that the spoils system was introduced in the BNA civil service, patronage became the guiding principle of civil service appointments, party loyalty, little concern for efficiency
in the 1850s/60s there was no party staying in office long enough to benefit from the potential of patronage
Patronage in the Age of McDonald – National Integration and National Scandals
Confederation created a bonanza of patronage
every province was going to obtain or retain (ON, QC) its own legislature
in addition, a whole new level of government, the national legislation
whole new slew of appointments
additionally vast new public works projects (to purchase the support of voters), e.g. transcontinental railway
Conservative Party was in power first, had access to the spoils of power, could consolidate its position and expand its support, explains why the Conservatives emerged first, Macdonald was a master in the art of patronage
after 1867 election, Nova Scotia sent nearly all anti-Confederation MPs to Ottawa, but Macdonald wooed them all, a cabinet seat for Joseph Howe, converted to the Conservative cause and Confederation
benefits flow exclusively from loyalty to the Conservative Party
people take care of what takes care of them
on the ground, Macdonald’s own riding of Kingston, patronage distributed in bureaucratic fashion, local party workers evaluated and recommended to the MP (Macdonald) for appointment based on service, an employment agency
system deliberately excluded outsiders in terms of geography and partisanship
patronage given only to local figures who could prove their loyalty
operated at all levels: judgeships and other senior appointments
Macdonald thought politically neutral civil service was naïve, outdated
civil service colonized by the political party
Gomery Inquiry: interest of national unity, convergence of interests, scandal and corruption
need for money
kickback: a company or individual who has received a contract will automatically give back a percentage of the earnings to the party
business-political symbiosis, business gain and political profit
at the heart of the emergence and dominance of Liberalism
like the press-party relationship, difficult to say who was the patron (boss) and client in the relationship because each side had power over the other, each side had the ability to punish and reward, each side exploited the other’s needs and abilities to advance their own interests
The Pacific Scandal, 1872-74: two rival business groups made a bid to build the Canadian Pacific Railway, one from Toronto and one from Montreal, enormous project, Macdonald holds off on a decision until after the election so he could hit up both consortiums for a donation, after 1872 he forced them to conglomerate, Americans were forced out, and in anger made public the details of what had gone on, Conservatives forced out of office and Mackenzie came to power
From Mackenzie to Laurier
Mackenzie never understood Macdonald’s patronage
a failure as a politician because he was not a good practitioner of the art of patronage
e.g. Mackenzie refused to purge the civil service of the Conservative’s appointees
as a clear Grit he stood for reform
clash between reality and values
Mackenzie annoyed and alienated his supporters who did not have access to the spoils of power because he was too honest
he occasionally gave into the pressure of party members
the result of his ambivalence was that the Liberals failed to establish themselves with a national presence and they lost the next election
only under Laurier when the Liberals adopted the same principles as the Conservatives in terms of patronage that they emerged as a national party
remarkable similarity between how the system worked under Macdonald and Laurier
under Laurier, patronage minister to Quebec (?) Israel Tarte coined the phrase “Elections are not won by prayers alone”
use of patronage with economic boom in the West established the party in the West
integrate newcomers into the political system, specifically the Liberals, e.g. rural communities in the Prairies
patronage system extended to the provinces, e.g Ontario under Mowat
The Civil Service and Reform
the Canadian case was the worst of all possible outcomes in a sense: in the US, you have at the heart an aversion to government; and in the UK, patronage appointments increasingly passed to a more independent civil services and it is less of an organizing principle in contrast to emerging ideologies like the rise of the Labour Party; but in Canada you have an active government involved in economic development with two parties without ideological differences driving them, all that remains is patronage
the civil service is a stable career, you need ties to a political party to get there
reform was a long time coming
civil service reform became an issue in the US after the assassination of Garfield by a man disappointed by his lack of patronage appointment, list drafted of civil service jobs whose applicants had to be examined, UK did the same thing
Royal Commission investigated civil service three times, drew attention to the evil of patronage and recommended reforms, some were adopted but they were piecemeal and easily bypassed, political parties saw patronage as crucial to their operations and were unwilling to give it up
American criticism of the spoil system influenced Canadian thinkers as did the British example especially by Loyalists to the Empire
growing pressure also result of scandals
in 1907, the Conservative leader Robert Borden presented the Halifax Program which proposed the curtailing and in some cases ending of patronage, he was not a fan of party politics, thought patronage was a distraction, proposed that the civil service be professionalized, examination for civil service posts
Civil Service Amendment Act 1908 adopted by Laurier, more impressive on paper, only a few cosmetic reforms
despite Borden’s misgivings, in 1911, he was elected and did not dispose of the tool because party argued it was essential, led to tension within the party
did not really end until the War, the War Effort called for efficiency, the patronage system was undermined, the formation of the Union Government in 1917 was a coalition of Conservatives and pro-conscription Liberals, aspired to non-partisanship and the effective war effort, patronage under attack
Union created new rules including sharing the spoils, civil service depoliticized by the Civil Service Act of 1918 which cut the legs out from under patronage, this was the beginning, it curtailed the use of patronage in what had been a wide-open area
conversely it helped to increase patronage at the provincial level because there were no reforms made there
Legacy
on the one hand, it helped to create and maintain political stability which was essential for the success of Confederation
for a long time it helped parties to attract and remain supporters, solid base
consistent with Allan Gordon in the course pack
national parties united by patronage used by leaders to run their electoral machines and break down local interests and integrate them into the Canadian system
parties were not representative of a region or religion or creed, they expanded to serve all
this achievement is somewhat deceiving
reciprocal arrangement between politics and business undermines Gordon’s theory
entrenched a political culture which was designed to neglect problems of cleavages, it encouraged the persistence of localism in a way, patronage made every local political organization jealous of its territory and suspicious of outsiders, created hard-working local constituency organizations linked to Ottawa but divided outsiders, more interested in their ridings and the patronage dispensed there
internal domestic peace
avoidance of serious debate on issues that fundamentally divided Canadians like linguistic debates
system of buying off support was convenient for politics but not Canada
as project of national integration continued, the parties that had used the benefits of the patronage system were increasingly unable to use patronage to mend political cleavages
patronage was its greatest strength and its greatest weakness of the post-Confederation party system
women were political actors, activists even before they had the formal right to vote
an action becomes political if the intention is to use any form of power to govern, shape, reform the society in which you live
she studied 12 womyn in Montreal of the upper class (resource-rich)
transition was from a very private, enclosed sphere to a much more public sphere while insisting in the rhetoric of the day
one discourse was the idea of separate spheres (public and private) in parallel with the idea that men and womyn have different natures and so exist in a particular sphere, e.g. womyn are naturally maternal and moral so they raise the family at home
womyn used the maternalist discourse to launch themselves out of the private sphere, said they had talents and natural abilities that men didn’t
at this time Canada had urban slums, rising infant mortality…womyn used this argument to argue that womyn were needed to “mother” society
we think of it as an equal rights campaign but this was not always the argument used
womyn’s involvement in charity in Canada took off in the early to mid 19th century, a religious task, moral, a safe way for womyn to fill their spare time
some people are double-dipping, some people are being missed, some people aren’t being helped by it, talk about how to improve the system
charity was impulsive and unorganized (giving money on the street) whereas philanthropy was well thought out, got to the root of the problem (matching skills to jobs)
1893: World Fair in Chicago, a model of a modern city, industrialization will lead to great things, for the first time there was a womyn’s pavilion, womyn were involved in all kinds of aspects of the Fair, first meeting of the International Council of Womyn, all female visitors were invited to hear its vision of womyn being a powerful force
several Canadians at this meeting went home very fired up
coincides with the arrival of a new Governor General whose wife was very powerful and active, went on a trip across Canada, energetic, was the president of the International Council of Womyn, got the National Council of the Womyn of Canada underway
the Council was an umbrella organization
shows that womyn saw themselves as citizens, as political actors, who wanted to take part in the development of Canadian society
a philanthropic organization that became political
one problem was how womyn were being treated in the factories, brought to the attention of the Council, which set up a committee to study it by going into the factories and speaking with the womyn and the managers and experts, decided womyn should have a minimum wage, limited hours, should have stools to sit on, etc. but the big idea was womyn factory inspectors
can’t have a bill introduced in parliament
strategy: invite MPs to dinner or tea and bring up the issue, organize public events like Harvard experts to speak about the issue, held meetings with premiers, were successful
this is a joint anglo-franco effort before WWI, the elite middle class learned both languages
they’re gaining political experience and support networks
power in numbers
Beginning of the Suffrage Movement
boring relative to the British movement, had a different shape, these womyn considered themselves ladies and used logical arguments, politicking, press coverage
most of the womyn did not use an equality argument, actually used mostly the maternalist argument, womyn bring different qualities to society
the vote was the means to an end, the end being prohibition
1867: property-owning males over the age of 21
Toronto Womyn’s Literary Club, 1876, intentionally misleading name, discussion was of how to get the vote, rename themselves the Womyn’s Suffrage Organization and around the turn of the century make their mission known
originated in large urban centres, e.g. Montreal and Toronto
but the first places to be successful were small towns and rural settings especially in the Prairies where they got the provincial vote early on under Liberal governments
some explanations: the Prairies were a place of significant immigration particularly from Nordic countries where womyn already had the right to vote; the frontier mentality, rough living conditions, womyn were in the field working just as hard as the men, sense of equality
1918: womyn get the right to vote in federal elections
as nurses, civilians, factory workers, womyn proved their worth in WWI, they were fighting on the home front, did they part, gained a lot of respect
PM Borden (the Union government) gave them the vote to pass his conscription policy, starting with expanding the franchise to all those effected by the war, e.g. the wives of men who were fighting or who had fought overseas, female nurses
Quebec
1791: the Constitutional Act stated that all land-owning persons were allowed to vote, did not exclude womyn, first place where womyn could vote, until 1849 when it became exclusive
suffrage movement began in urban centres (Montreal) in contrast to rural Quebec which was more traditional than the rest of Canada, more religious
WWI was a difficult period for anglos and francos
1922: really gets underway, 400 womyn meet with Premiere Tashrow (?), but they were dismissed, he had been presented with a church-organized petition the day before which protested enfranchisement
St-Jean in 1927 transformed it to a working class phenomenon, made progress in the 30s, until DuPlessis (Union Government), very conservative and traditional, has no time for womyn’s suffrage, gets the Liberals warmed up to the idea
1939: womyn invited to the Liberal convention
coincides with start of WWII
argument used held that if womyn’s suffrage was endorsed, conscription would pass, and the governments could work together
when the Liberals were elected, they granted the right to vote
France didn’t grant the right to vote until 1942, after Quebec, French heritage cited as a reason for holding out, in contrast to Britain
January 24, 2007
The ‘National’ Question on the Eve of Crisis
Conference – MacKay article, readings for this week
Main Arguments:
Canada’s two post-Confederation national parties owed their success to bridging the regional and cultural differences between Canadians.
Consistent with the broader international trends of nationalism and imperialism, however, both the Conservatives and the Liberals found it increasingly difficult to bridge Canada’s cleavages.
A series of interrelated disputes throughout the late 19th and early 20th century related to “national integration” and questions regarding Canada’s “national” character undermined the two main political parties and led to the mergence of potential challengers. This was the precursor to the collapse of the post-Confederation party system that would occur during the First World War.
The National Question: Background
local and personal ties were at the heart of traditional, rural, agrarian societies but they began to break down in the context of liberalism, capitalism, industrialization
nationalism replaced it, sense of belonging to a greater collectivity, in a period of profound social upheaval
emerges first culturally: every nation had a distinct language, history, worldview, culture of its own that needed to be preserved
lead to political nationalism: every nation should have a sovereign state, the nation would be governed by members of their own, the cultural expression of a people, the key to survival and success
e.g. unification of Germany, of Italy, the decline of the Austrian Empire and the Ottoman Empire, Irish nationalism, American nationalism and its Civil War in the 19th century
intense territorial competition reflected in colonialism, done on behalf of the nation
Canada desired a separate existence from the States, what was the Canadian nation, two culturally distinct nations living in one state, self determination, nationalism, the concept of a nation-state, how can nations share one state
Lafontaine and Baldwin proposed a biracial nation that overcame cultural differences
Macdonald said no party could endure without being “French-ified”
Chapleau believed that French-Canadien interests would be best served within Confederation, it is necessary to speak with one voice
Laurier made the Liberal Party the dominant party in Quebec
keep economic expansion in the forefront of voters’ minds, the one thing that the French and English could agree on, distract the groups from their linguistic and religious differences
homogenous parties (one religion, one ethnic group) not developed
the political parties bridge the divides, power machines, don’t necessarily stand for anything
The Provincial Rights Question
the relationship between federal and provincial
system meant to provide part of the answer to the National question: two levels of government, provincial government to take care of cultural issues and federal government to address state issues
in practice, questions raised immediately about the power relationship between French and English across the country
Macdonald preferred a strong national authority to consolidate Confederation, saw provinces and their bids for power as rivals, his centralizing efforts provoked reactions at the provincial level, reflected in the growing strength of political parties at the provincial level
e.g. Ontario Liberal Party, led by Mowat, considered the father of the provincial rights movement
in the early years, Conservative Party’s dominance in Quebec kept its national ambitions in check
Canadian Imperialism: centred chiefly in Ontario, advocated reform of Canadian nationalism, goal was independence from the States, best achieved by having strong ties with the British Empire, not in a subordinate status, but as a partnership (equal partners), Canada would be an active contributor to imperial defence and have a saying in the running of the Empire, anglo-centric, Ontario-centric, this ignored French Canada’s desire for autonomy and detest for the Empire
Anti-Imperialism: French and English, said imperialism was at odds with nationalism, couldn’t be reconciled, saw the imperialists as a reactionary remnant of colonial-minded individuals, argue that Canadian imperialism could not be reconciled with independence, largely
Nationalisme: French Canadien nationalists, strong commitment to Canada’s defence, Canada was either independent or part of the Empire but not both, concerned about the status and rights of French Canadiens, some were Quebec-centred and some wanted a French presence everywhere, the awareness of being a minority
result is a series of disputes between these rivalries
The Northwest Rebellion
1885
rhetoric in English Canada, especially from Ontario Imperialists, treated the rebellion as a test of Canada’s nationhood
Metis cast as enemies of Canada and its control over the northwest
Ottawa’s response (execution of Louis Riel) alienated French Canadiens
half of Quebec Conservatives either voted in support of or abstained from a motion put forth that condemned the execution
Trudel: “The nation’s duty compels us to break the tradition of the past 20 years”
Mercier was a member of the Parti Nationale, an effort to bring together Quebec Conservatives and Quebec Liberals, put the French interest ahead of the party interest, Mercier called for a sacred union between French Canadiens
a second Parti Nationale is a provincial party, those who opposed Macdonald’s handling of the Northwest Rebellion, ride a nationalistic wave to victory in the election, in office they were notable because Mercier used it to strongly serve the notion of political autonomy for Quebec, challenge to Ottawa’s authority, but falls from power in 1891 and the Liberals return to power
the French Canadien nationalist cause endured, the Northwest Rebellion was the beginning of the end for Conservatives, Liberals increasingly had to seemingly favour autonomy for Quebec
the rise of the Parti Nationale is indicative of growing nationalist tensions between the English and French, who has power, who will lead
Linguistic and Religious Rights (pre-1900)
Equal Rights Association formed (ironically named)
by the 1890s, movements to extinguish French education and linguistic rights outside of Quebec, e.g. Manitoba, Ontario, and New Brunswick
Manitoba had been founded on an equal basis, equal government funding for French and English, but migration from southwest Ontario (Clear Grit country) upset the balance, the Liberal government halts funding to Catholic schools
Conservative government under pressure to intervene in Manitoba’s government, controversy, accelerated the Conservative Party’s decline in Quebec, helped propel the Liberals into power, able to bridge linguistic/cultural/religious cleavages
Laurier, rather than Ottawa restoring rights, looked at the numbers, pragmatic, provided for instruction and bilingual instruction where the numbers were
Laurier Liberals seized power at the height of these French-English tensions, reinforced by the imperialist world views
The Boer War and Rise of the Nationalism
imperialist war
French Canadiens absolutely opposed
English demanded participation
Laurier’s government at risk of falling, would be replaced by an Imperialist government
how to offend the least amount of people?
sent only 1000 soldiers to South Africa, but Ottawa will only pay for the transport and clothing, after that Britain picks up the tab
upcoming election
trying to preserve national union
of course, both sides too it as either “too little” or “too much”
Henri Bourassa was a predominant Liberal critic, accused him of caving, setting a precedent for participation in Britain’s colonial wars, he resigns in protest, but it immediately reelected as a national Liberal, an advocate of French Canadien nationalism and a critic of imperialism, a French Liberal
Laurier re-elected because they were still a better option than the imperialist Conservatives
Linguistic and Religious Rights (post-1900)
League Nationalist established, for provincial autonomy (Quebec’s) and make sure that Canada was truly a partnership between French and English
a movement, not a party
Bourassa not a big fan of parties (the dictates of party discipline)
the League Nationalist supports independent candidates or party candidates who support their ideals
MacKay
calls for a reconnaissance rather than a synthesis
not just particular events, fragments
sense of general patterns
tracing Liberalism from its inception to Neo-Liberalism
Liberalism the dominant ideology by adopting, morphing
connect the dots to get an idea of what Canadian Liberalism is
the older approach is simplistic, this would be more sophisticated
Gramscian concept of “passive revolution”, e.g. Harper’s announcement of funding for alternative fuels
passive revolution vs. the great Canadian compromise as explanation for Confederation
Liberalism is mostly about individual rights
civic humanism: organic social order, a competing ideology emerging as the ancien regime was collapsing, popular in the UK, US, France, a concept of the relationship between citizen and society recalling ancient approach, e.g. Greece, rather Conservative with Liberal aspects, hierarchical
The Suffrage Movement
the vote not granted out of the goodness of their heart but to preserve the order
Liberal ideology reflected in recognizing women as citizens when they are property owners, originally debated in 1867 or thereabout, but shot down because giving women a voice would undermine married women and possibly prevent marriage altogether
Quebec argued this should be a provincial decision rather than a federally imposed one
motivated by conscription
Arthur Meighen’s quote about giving the vote to women and not alien men show what he judged to be grounds for Canadian civil rights, strategic, strict definition of Liberal individual
the vote a means to an end
political parties as gatekeepers, e.g. Person’s Case
women didn’t rush the gate, act as a united force, little discernible change on the ground
Linguistic and Religious Rights (post-1900)
The Autonomy Bills established Manitoba and Saskatchewan
allowed for separate Catholic schools
but Laurier retreated under pressure, new legislation severely curtailed linguistic and religious schools
Manitoba School Act
Bourassa, etc. fuelled their nationalist fire
pressure that the Western Liberals imposed and that the Nationalists in Quebec imposed shows that the Laurier government had an even more difficult time bridging Canada’s divides
Laurier Liberal’s difficulties only grew with international developments
The Naval Debate
1909: Anglo-German rivalry provoked a naval arms crisis
New Zealand gives UK cash to buy battleships, Australia decides to build its own navy (take care of its own defence in order to relieve pressure on the Brits)
what should Canada do?
debate: assist the British, respond to imperialist sentiment, but now in a way that would anger the Nationalists in Quebec or the imperialists
Borden supported Laurier establishing Canada’s own navy, but leaving the door open to making an emergency cash contribution to the Brits if needed (Australia and New Zealand combined)
but this bipartisan cooperation evaporated…divisions with the parties and country
Borden faced severe criticism from Conservative imperialists in Ontario who said that ‘This is an emergency, they need money, they have the expertise, let them build the ships’ whereas Canada’s own navy would be inferior
Monk saw both options as entangling Canada in the empire
Borden breaks with Laurier, calls for an immediate cash contribution and a Canadian voice in determining imperial defence and as a way to respond to the anti-imperialists says that Canadians should be able to express their voice on the issue, i.e. a referendum before a permanent policy is adopted
Naval Service Bill, 1910, controversial by imperialist and linguistic lines
English Canada: Laurier’s Navy a betrayal of the imperial cause
French Canada: another betrayal of Canada’s self-governance and autonomy, Ottawa doing London’s bidding
Bourassa becomes a rival to Laurier’s leadership in French Canada, the pragmatic Laurier to the more doctrine Bourassa
Bourassa founded Le Devoir in 1910, mouthpiece for the Nationalist cause
The Reciprocity Election
calls for reciprocity and free trade (Laurier has still not delivered)
Liberals go for “restricted reciprocity”: reciprocity in the agriculture sector, but the protectionist tariff to remain in effect for the manufacturing sector, a marrying of the best aspects of the national policy but answering the grievances of rural Canada, America agrees, very popular initially
concerns about the rate of North America continental integration, what does this mean for the future, especially the relationship with London, how close is the US
unrestricted reciprocity means the American takeover of Canada, trade between Canada and the US (north-south rather than east-west) would reign, national sovereignty undermined
“The Toronto 18”: claimed that they previously supported Laurier, had a vested interest in the national policy, declared they were opposed
Clifford Sifton bolted from the Liberals
opponents appealed to a higher principle: imperialism, Laurier was depicted as anti-imperialist and therefore anti-Canadian, that by increasing ties with Americans he was threatening Canada’s independence
Summer 1911: Laurier facing opposition, an obstructionist parliament withholding approval of the legislation, he calls an election
quickly becomes a referendum on the Liberals foreign policy, growing attacks of reciprocity in English Canada
a crucial alliance between the imperialists and the anti-imperialists
Quebec Conservative Party was beginning to detach itself from its federal cousins, tied to a party dominated by imperialists, considered anti French-Canadian
an opportunity created because the Quebec Conservatives began to make common cause with the League Nationalist to gain votes in Quebec
Borden begins to think of Bourassa as a possible solution, to Borden the thought was that maybe a joint effort between the imperialists and anti-imperialists could challenge the Liberals
the Borden Conservatives refused to run candidates again Bourassa’s Nationalists
Liberals vs. Nationalists in Quebec
Bourassa wanted to cooperate to defeat Laurier and his naval policy, but this did not mean that he wanted Borden’s naval policy, he wanted to be the kingmaker, deny both the Liberals and the Conservatives a majority, use this leverage to bring about the changes it wanted
but a Conservative majority is elected, 118 seats, the Nationalists win only 16 seats, far short of the balance of power
looks like the torch was just passed back again
but really marks the end of the post-Confederation system, Borden achieved victory through his alliances, but not a solid foundation for a governing coalition in the long run, base still in Protestant Imperialist Ontario
Conservatives try to pass their emergency cash contribution, 7 Nationalist Conservatives from Quebec saw this as a betrayal of Canadian self-government, Liberals reenergized, block the legislation that the Conservatives try to pass using their majority in the Senate
growing strength of French Canadian nationalism
on the eve of WWI, two national parties responsible for Confederation, increasingly victims of the efforts that their actions for consolidation had provoked, victims of the question of Canada’s national identity and destiny, neither party in the position to claim that it was capable of bridging them, events overseas about to heighten the significance of the nationalist question (Empire, power relations between French and English)
especially aspecially
The Great War and Crisis in Canada’s Political System
Arguments:
Conflict abroad caused conflict at home. The wartime clash between imperialist and anti-imperialist worldviews, and accompanying cultural tensions, had far-reaching consequences for Canada’s political parties.
The Liberal disintegration, the emergence of Union Government, and the results of the 1917 election brought the post-Confederations party system to an end. The relative political stability since 1867, characterized by the lengthy times in power of two inclusive, pragmatic, pan-national parties, disappeared
The triumph of Unionism represented a victory for the imperialist-nationalist vision for Canada; as such, it ultimately contributed to disunity, owing to the marginalization of French Canada, which had long-term implications for Canadian party politics.
Union Sacree? Canadian Politics from War’s Outbreak to 1916
Laurier gives his support to the battle cry
coming from the leader who had consistently preached ‘limited participation’
like the Boer War and the Naval Debate, it appeared Canada would enter the war, even Bourassa gave his qualified support
the fact that the cause was just (Germans had betrayed Belgium’s neutrality, Britain was in danger); participation was voluntary (Borden promised conscription would not be enacted); the assumption that the war would be short (over by Christmas); the fact that the national unity within the House of Commons was stronger than outside the House (masked divides)
“Union Sacree” put to the test, as it became clear that the war would not be over by Christmas, increasing pressure from Britain, massive Canadian casualties, voices of dissent, breaking of bipartisan unity, series of patronage scandals to boot
growing concerns about the Conservative Party’s fortunes, beyond declining support in Quebec, increasingly unpopular across the country, by the end of 1916 only in control in Ontario
this prompted Borden to propose the extending of parliament, Laurier agrees to one more year, neither of them wanted to go to the electorate during the war, partisanship only increased, the façade that existed in 1914 collapsed
The Collapse of the Union
The Battle over Language
renewed questions over the power relationship between French and English over war
1912: Ontario government introduced Regulation 17 which severely curtailed the use of French as the language of instruction within Ontario schools, limited the teaching of French to the first two years of primary school, Franco-Ontarians outraged, violation of the Canadian Constitution, the Nationalists supported the Franco-Ontarians, an attempt of assimilation, marginalization
Borden refused a petition that called on Ottawa to disallow this law, said education is a provincial responsibility, the federal government is not going to interfere
matter brought before the House of Commons, divided along linguistic lines, French Canadians supported the resolution to veto the law
Conscription and the Liberal Collapse
call for 500 000 soldiers from a population of only 8 million
things not looking good for the Allies
Americans introduced a draft, put pressure on Borden to do the same, a vital member of the British Empire, but political difficulties like during the Boer War
needed Liberal support, Laurier’s support, through the formation of a coalition government that could enact conscription
Laurier first rejects the offer on the grounds that by 1917 a Liberal return to power seemed in sight, voters unhappy with the war effort, the one-year extension up, warned that the English population was not fully in favour of conscription anyway, “The voice of Toronto is not the voice of God”
Bourassa’s support for the war effort had eroded after Resolution 17
James Massey criticized Quebec for its low enlistment rates and questioned its commitment to Canada
Laurier does not want to leave the field open to Bourassa, rejects Borden’s offer, asks for the national referendum on the issue, buy him time to build a coalition
during the Regulation 17 debate the Liberal caucus had split, the Western Liberals voted with the Conservatives while the rest voted with Laurier (Ontario only barely)
John Wilson openly supported the Conservatives, wanted them to become the national party of English Canada, only they could be trusted with the future of the country, the British population was the only true Canadian population, an imperialist, Quebec had forfeited their right to the nation
sections of Liberal caucus tired of Laurier’s leadership, argued Canada needed a new liberalism to better respond to industrialization and urbanizaiton, came from Ontario and the West, advocated social programs like old age pensions and employment insurance and womyn’s suffrage and prohibition
Laurier feared these new Liberals were trying to impose a new mode on the Liberal Party, trying to marginalize French Canada, undermine the Liberal claim to being a pan-Canadian national party
Military Service Act split the Liberals on linguistic lines, the anglos sided with the government overwhelmingly, only 7 supported Laurier’s call for a referendum on conscription
result was the Liberals could no longer claim to be a binational party
MPs had more power back then, less whipped
English supported conscription, French opposed it, beginning to see the breakdown of the system, polarization along ethno-linguistic lines
The Rise of “Unionism”
Why did it take so long to form a coalition government?
1. Laurier’s bipartisan pledge, no need for coalition, the parties seemed to agree at the onset of the war
2. Self-interest, the Conservatives are in power for the first time since 1896, don’t want to share the spoils of power, on the other side, Laurier was more charismatic than Borden and believed he would overtake them, the Conservative weakness would allow the Liberals to return to power
3. The scope of the crisis was not large in the early years, the war would be over soon
this had all changed by 1917, concern became how to manage the war effort
the Ontario caucus of the federal caucus begins to pressure Borden to form a coalition with the “patriotic wing” of the Liberal party
John English (historian) describes the establishment of the Union government as the result of the efforts of an English-Canadian nationalizing elite centred from Canada’s urban centres especially Ontario to bind together an increasingly fragmented Canada
mid-October 1917: 12 Conservatives, 9 pro-conscription Liberals form the cabinet
1917 election results: essentially a one-party election, Liberals in Quebec, and the Unionists in the other provinces, but the vote was closer than the seat distribution suggests, Quebec returned anti-conscription Liberals and the rest of Canada returned pro-conscription Unionists
Laurier Liberals were now anti-conscription, largely French-run
neither party could claim to be “national”
Wartime Elections Act disenfranchised thousands of immigrants who would likely have voted Liberal and the enfranchisement of womyn was designed to support conscription
Military Voters Act allowed for soldiers to vote in any riding, encouraged to case their ballot in close ridings
so the victory goes to the imperialist-nationalist vision of Canada and the Unionist cause
it had already come from within, a marriage of convenience
The Disunity of Unity
gradual disintegration
died with Borden’s resignation
new leader tried to keep up the façade by renaming the party the Liberal-Conservatives
the national government that Unionism represented ultimately meant the domination by the arrogant majority for too many Canadians
Laurier dies in 1919, Bourassa increasingly seen as depassé
unity is a pipedream
Nationalists increasingly focus on the Quebec nation
implications for the two mainline parties
Laurier’s anti-conscription meant Quebec would stay Liberal
King was seen as a supporter of Laurier, wins the leadership, but party had been reduced in its seats
by the time the Union government came to an end not one provincial government was controlled by Conservatives
Conservatives identified with the unionist, pro-conscription cause by Quebeckers
Challenging the Establishment? Part 1: A Progressive Response
Main Arguments:
The rise of the Progressives may be understood as the manifestation of a widespread rejection of “politics as usual”, combined with an agrarian reaction, centred especially in (but not limited to) Western Canada, against the national political and economic system build by the Conservatives and Liberals;
The Progressive Party’s greatest strength was in a sense its greatest weakness: its populist, mass-based origins, meant it ultimately failed as a party, due to its divisions among its members over its raison d’etre and its role in the system of Canadian party politics, against which it was reacting;
The legacy of the Progressive Party, however, lived on in terms of encouraging the two traditional parties to be more democratic. Even more significantly, the rejection of “politics as usual” and sectional discontent would re-emerge in the 1930s and beyond in new challengers to the Liberals and Conservatives, confirming the demise of the post-Confederation two-party system.
The “Progressive” Challenge to Party Politics
the League Nationalist is an example of a popular mass-based approached, the emergence of extra-parliamentary parties
the reaction of groups and individuals against the national establishment, e.g. womyn’s attempt to gain power in the political system and the competition between English and French Canadians
understand that this is the product of disillusionment with the existing political order, embodied with the demand for reform
American Progressives strongly opposed corruption, called for political reform, believed that the status quo was corrupting democracy, efforts to reduce the power of political machines and party bosses through innovations of direct democracy, e.g. the recall, the initiative, primary elections
Canadians saw government as advancing the interests of the party and its friends, not the national cause, inspired by Americans, wanted greater control over their representatives and greater input
Canadian Council for Agriculture called for the public ownership of utilities, graduated income taxes, Senate reform, direct democracy, and proportional representation in 1916
movement seen in number of independent candidates in Saskatchewan’s provincial election in 1912 which increased threefold
NPL wanted representatives to be accountable to their constituents
1913: WJ Rutherford called for a new political party that would make politics “a holy thing” in Canada
people disenchanted with the two-party system
Canada becoming more urbanizae
Borden
seen as a bit of an outsider, from Nova Scotia, felt politics as usual was not working, didn’t want to be dominated by the Conservatives
reached out to the progressives to build a new coalition, e.g. the suffragists
pragmatism, compromise, moral order the new way
Union government argued that is embodied all interests, no need for another party
John English (historian) argued that Borden saw unionism as more than a political party, it was a political movement, popularly based, to lead to a non-partisan upheaval of the way politics was done
promised to abolish patronage
The Agrarian Revolt and Western Discontent
the rise of the Progressive Party was also a reaction, a sectional revolt
the other part of the explanation for its rise
American farmers had revolted, felt that the two parties were not responding to their needs, lead to the establishment of the American Populist Party
in the decade after WWI, farmer’s parties established in Scandinavia and Eastern Europe, sense that the rural community was being marginalized in rural life
politicians of Canada envisioned the West as the hinterland of Toronto and the East as the hinterland of Montreal
Western settlers who purchased land from the Canada Northwest Land Company, purchased tools from another company that was also protected by the government, higher costs
National Policy tariff
economically subservient condition combined with the precarious conditions of the wheat economy fuelled resentment, Western Canada’s needs ignored, kept in a state of dependence
democratic wakeup: settlers arriving in Alberta are predominantly Americans who experienced the agrarian revolt there, Jacksonian Democracy; in Saskatchewan the settlers are predominantly Brits who experienced uprisings; in Manitoba they are south-western Ontarians where the notion of agrarian democracy is well advanced through the Clear Grit ideas
this contrasts to the East, which was more Whig-ish
Western discontent growing as debt of farmers increasing, the low international price of wheat not increasing as quickly as manufactured goods, Liberals not moving on reciprocity (which they wanted: free access to the American market and cheaper goods through free trade or freer trade)
farmers began to organize, inspired by the American example
1905: first farmer’s grain market established
1911: Western concerns on the national agenda, seemingly, after Laurier toured and saw how angry farmers were, Liberals finally move on reciprocity, but they were subsequently defeated
farmer’s influence seen as waning, they are marginalized, central big business dominates
this increased during the war, Westerners initially hoped that the Union government would be more national, end patronage, show democracy, the promise that conscription would not be applicable to farmers (food an essential part of the war effort)
couple months after election Germans have a breakthrough on the Western front, crisis, Unionist government revokes the exemptions granted to rural Canadians, 1918
and still no action on the tariff, if anything it was increased to help the war effort
and thousands of farmers had been disenfranchised by the Wartimes Election Act
at the end of the war, drought hits the West, especially southern Alberta and at the same time wheat prices collapse, so they are harvesting less wheat and getting less money for it
rapid post-war inflation, costs of living and doing business increasing
tariff issue takes on even greater resonance
“The New National Policy” – calls for free trade with the UK and US
Union government caught in the middle, opted to delay any action on the tariff
Thomas A. Crearar, Western Liberal, resigned over it
result an emerging third-party challenge
The Farmers United: The Provincial Level
rural Ontario furious at the revocation of the conscription exemption and its seeming declining influence in provincial politics
UFO established, United Farmers of Ontario, with the United Farm Womyn and United Farm Young People
Oct 1919: UFO wins the most seats in Ontario, builds a coalition with labour members, under the leadership of E.C. Drury (from Barrie!?) forms a government
United Farmers of Alberta MP wins in a provincial bi-election
UF of Manitoba allows its members to organize, win a plurality of seats in the next election
Saskatchewan Liberals closely ally with the Sask grain growers association
Henry Wise Wood, UFA leader, feared losing control of it, just wanted it to be a pressure group to lobby the parties not a political party itself, but under pressure agrees to run some candidates, groups to elect representatives rather than individuals, e.g. lawyers and farmers elect representatives, only farmers can be elected by the UFA, they sweep to power, but Wood refuses to lead the party, doesn’t want to be personally involved in politics
success as provincial level followed by success at the national level
The Emergence of the National Progressive Party
Crerar insists it is not a farmer’s party, but for all who desire to see morality, reform, etc.
a distinct agrarianism in their policies, e.g. central demand was tariff reform, and easier access to credit for farmers, provincial control over national resources, more services to rural areas, abolition of party discipline and patronage, direct democracy
did not campaign as a national party in 1921
Liberals and Conservatives in a state of disarray in the West, King tried to pose as a friend of the farmers and accused the Progressives of causing class tension, Conservatives advocated the National Policy
in 1921, voters rejected both of the old parties, Conservatives won 50 seats, Liberals formed a minority, the Progressives won 25% of the popular vote and 64 seats to be the second largest party in government, however it was short-lived due to divisions within the new party and its raison etre, was it a party or a popular movement or…
the Manitoba wing led by Crerar favoured a pragmatic course of action, saw the Progressives as disbanding once the King government granted some concessions
Alberta argued progressivism had to fundamentally challenge the political establishment, break with the past, much more principled/doctrinaire view
serious implications
they seeded their role as Opposition to the third-place Conservatives
did not form a coalition
they lost their two best means to directly influence the political process
King dismisses the farmers, the progressives as “Liberals in a hurry” and only introduced sufficient concessions to keep himself from being defeated, e.g. reduced the tariff on farm machinery
the Conservative Quebec wing totally opposed to forming a coalition with the Progressives, no alliance formed, tricky balance
Progressive Decline
party split in 1924 over the question of supporting the Liberal budget
pragmatism triumphed: Forke voted against an amendment that would have brought established progressive policy into law in order, King government would have dissolved, Conservatives might have come to power
6 left the caucus to sit as independents
no money, no national organization
only 24 Progressives (West of Ontario) elected next election
Liberal-Progressive alliance to keep Liberals in power
1926: only 9 Progressives left, disappear over the following years as the organized farmer’s protests of the 1920s faded, internal divisions, return of prosperity, some drifted to the Liberals, retired, or sat as independence
1923: UFO fell from power in Ontario
UFA out by mid-1930s, the last provincial party
1926 resulted in the return of majority government, marked the completion of the transformation of Canada’s party system that had begun with the Union government
Liberals and Conservatives had rallied support, extra parliamentary support, used conventions to elect leaders (small nod to democratic ideal)
Challenging the Liberal Order, part 2 – The CCF and the Left
Main Arguments:
The rise of the CCF followed a long tradition of diverse, but ultimately ineffectual political activism from Canadian labour. It was only the profound dislocation of the Great Depression that led to the emergence of a viable, national left-wing party;
Beyond its socialist aspects, the CCF was a manifestation of the same agrarian populism and sectional resentment that gave rise to the Progressives;
While the CCF presented a national vision challenging the political establishment, its early record was less spectacular than that which the Progressives, or its Prairie rival, the Social Credit Party experienced. Moreover, there were serious questions about how French Canada fit into the CCF’s alternative “national vision”.
Background – The Rise of Organized Labour and Socialism
the belief was that legal equality espoused by the Liberals was insufficient without social and economic equality
the Communist Manifesto argued that capitalism would collapse
rise of a French socialist party in France
first Labour MP elected in Scotland (Keir Hardie)
1923: British Labour Party formed the government
the rise of socialism and organized labour in Canada resembled the situation in France and Italy: low percentage of organized workers, slow formation of trade unions
movement was divided: in Quebec, competition between the TLC and the Catholic movement; Western labour movement was more radical and resented American influence in the TLC
tried to form One Big Union, idea was that all workers (skilled or unskilled) would be banned together, like International Workers of the World
Trade Unions Congress (TUC)
Trade and Labour Congress (TRC)
Economic Upheaval and Labour Activism in Canada
after WWI, labour unrest is universal, vicious cycle of economic disruption, hit the European and North American economies in particular, unemployment and inflation
e.g. 1918: $1.60 to purchase what $1 purchased in 1913, worker’s wages not keeping pace, standard of living declining
1919: week-long Winnipeg General Strike, set off sympathy strikes, class tension, but some dismissive attitudes
radical social gospellers, e.g. Woodsworth and Irvine, thought that church-based social reform was too conservative, not going far enough
Labour: The Political Reaction, 1890s-1930
an incentive for labour to enter into electoral politics, built on a lengthy but ineffectual history of labour in politics, e.g. Socialist Party of BC held the balance of power in the BC legislature in 1903, the formation of the Socialist Party of Canada, in Ontario in 1919, 11 labour MPs elected
labour unions try to establish party at provincial levels across the country
farmer/labour coalition form the opposition in Nova Scotia
on the federal stage, 22 Labour candidates in 1917 run, but none elected, poor planning, dominance of the Liberals and Conservatives
Canadian Labour Party did not see success, the TLC was accused of being too Conservative by the provinces and in return the TLC thought the provinces were too radical
Communist Party founded by radical members of the socialist party, strong tensions between the Communists and CLP, part ways at the end of the 1920s
Progressives went on the record to say that they opposed militias to break strikes, but did not support an open alliance with Labour, not in farmer’s interest
Woodsworth and Irvine the first labour MPs to not ultimately be absorbed by the Liberals
when the Progressives splits part, 6 of its more radical MPs formed the “Ginger Group” which increasingly cooperated with Woodsworth and Irvine
coalition between the Labour movement and the UFO did not go well, not much progress in the Ontario legislature
a vital, active Canadian left, but ultimately politically impotent because of their divisions, e.g. a dozen labour and socialist parties in Toronto alone
barely survive the 1920s, a blip on the map
what was needed was encouragement for unity…which came with the Great Depression
seems that the capitalist system is indeed collapsing, no country immune
Canada’s radical groups and labour groups worked together to unite the non-Communist left, as already happening in Parliament with Woodsworth, Irvine, and the “Ginger Group”, who became “The Commonwealth Party” in 1922
The Rise of the CCF
Conference of Western Labour Parties held in 1929, when they meet again two years later in the Depression, motivated, agreed to form a national labour party, extended an invitation to various farmer’s organizations to join, recognized that labour and farmers were ultimately facing a similar plight, marginalized by the Liberal capitalist system, their joint action was demanded
important participants: Gardiner (UOA), Coldwell, Williams, and Tommy Douglas, also the League for Social Reconstruction, an intellectual brain trust of the CCF, a group of left-wing intellectuals, writers. etc. with a Christian background
Aug 1932 conference in Calgary brings together the labour movement and the farmer movement, synergy, they agree to federate and form a new movement that will champion the cause of socialism
The Co-operate Commonwealth Federation to be a social movement for change, radically change the way Canadian society functioned, challenge the Liberal establishment
draft a statement of purpose in 1933 at their first official meeting, The Regina Manifesto, advocates the eradication of capitalism, the peoples to control the state, the state to regulate the economy and provide a wide range of social services, public ownership of all financial establishments and public utilities, aimed to ensure that democracy governed the party rather than the party officers who were to be elected annually, policy conventions
hourly pay falling an average of 2/3rds, collapse of international commodity prices, drought in Saskatchewan
within 3 years of its founding, CCF the number 2 party in BC, Alberta, and Saskatchewan, with seats in Manitoba and Ontario as well
no support in Quebec or Maritimes
at the federal level, in 1935 they ran 119 candidates however does not have the same electoral breakthrough as the Progressives or as the provinces, only 9% of the popular vote, elects only 7 MPs in the West
yet the CCF the true opposition to King’s Liberals, they are advocating the most radical changes, the Conservatives had just significantly lost the last election and are in disarray
success: section 98 of the Criminal Code which allowed the government to arrest and deport immigrants that they deemed a threat to national security scratched (reaction to Winnipeg General Strike)
Evaluating the CCF
socialists, as demonstrated in Shawn Mills’ article
but in Alberta and Saskatchewan, Sinclair argues that the CCF party was in the populist Prairie tradition (like the Progressives) and consistent with the dominant presence of the middle class
CCF not interfering with the primary means of production, the family farm in Saskatchewan, not attacking capitalism per se but those aspects of capitalism that were affecting the farm
Dan Horowitz argues that the apparent popularity of socialism in Canada can be contributed to the “Tory touch”, Canada more receptive to the organic view of society, collective aspects
but if Canada is so receptive to a collectivist, socialist approach, why didn’t the CCF make more progress at the federal level?
Challenging the Establishment, part 3: Social Credit and the Union Nationale
Main Arguments:
The rise of Alberta’s Social Credit Party and Quebec’s Union Nationale may both be understood as Depression-era reactions against industrial capitalism and the respective political status quo in each province;
While both parties came to power criticizing industrial capitalism and even demonstrated some left-leaning attributes, fundamentally, their concern was not so much to challenge the established liberal order, but to correct it, ensure it endured, and that more radical solutions were not attempted;
Both parties were successful because they responded to Albertans and Quebecers’ search for scapegoats and solutions. However, neither party delivered on the reforms they had promised, and both were quickly revealed to be fundamentally conservative in their governing style.
Background to the Rise of Social Credit
as the Depression continued, people searched for alternatives
e.g. rise of the right-wing Nazis and Roosevelt’s New Deal
Canada not immune
Social Credit: 1930s Alberta is overwhelmingly rural, most non-farm employment was still linked in some way to the agricultural economy, Big East business the scapegoat
UFA had evolved into a party like any other, increasingly Conservative in its reaction to the Depression, despite being elected on a wave of agrarian discontent a generation earlier
socialist nature of CCF appealing, but ultimately Social Credit
Social Credit theory developed by C.H. Douglas, rejected social collectivism, promised to cure capitalism through reform, answered why the system could be producing so many goods and yet there was poverty, the “A + B” theorem, the real cause of the Depression was that the real wages being paid to produce goods and services was always less than the total costs of production, i.e. it costs more to produce goods than people were earning to produce them, never enough money in the economy to purchase the goods that the economy was producing, solution Douglas proposed was to make up the difference, the government should provide every consumer with a “social credit”, i.e. an amount of money from the government that could theoretically cover the balance between the goods produced and the paid wages, a very rudimentary form of Keynesian economics, in periods of economic downturn governments should spend money, keep enough money in the economy for it to function
Alberta was fertile ground for this theory: UFA personalities had preached Douglas’ theory as part of their larger attack on the economic status quo
Background to the Rise of the Union Nationale
Montreal 1933: 1/3rd of the population on relief
1920: agriculture only 1/3rd of the Quebec economy, declining
increasing industrialization, development of the natural resource sector
increasing foreign capital
culture: the social tensions were as cultural as they were economic, increasing industrialization and urbanization meant the marginalization of Francos, scapegoated the Anglos
French-Canadien nationalists concentrated on intellectuals, e.g. Lionel Groulx, who said the Depression was the result of foreign capital’s dominance, calls for reform, came from the new social thought in the Catholic Church: a Christian humanism
Programme de Restauration Sociale (PRS): Catholic trade unions, farmer’s organizations, credit unions, patriotic and professional societies, universities, called for fundamental reform, including rural reconstruction (strengthen and extend the agrarian sector especially in northern Quebec); the labour question (protect workers, provide greater economic security for the working class); trust and finance (curb the power of private utilities and other large enterprises like the milk industry); political reforms (elimination of patronage politics, return to ethical politics hahaha)
The Rise of Social Credit
delegates urged the UFA government to examine the Social Credit theory as a method to recover, government drags its heals
William Aberhart emerges as the leader of the SC political challenge, called for representatives, had a populist, non-partisan nature
each Albertan to receive a monthly government cheque to spend (like Klein!)
“All you have to know about Social Credit is that if you vote for it the experts will make it work”
effort to correct the weaknesses of liberal capitalism, bring stability
rapid rise
beyond the attraction of the $25, Albertans attracted to abolishing poverty, and it tapped into Western discontent with the East, the soft-totalitarian nature was attractive, call for charismatic leaders like Aberhart, a great communicator
Aberhart drew a large share of religious community (Christian fundamentalism compatible with Social Credit), harped on his credentials like his Queen’s degree, but maintained a folksy, populist appeal, appeared in warn and patch-up coats, used improper grammar
SC’s success attributed to its advanced organizational structure, paralleled the UFA, SC brought together study groups, the “Social Credit League”, makings of a mass political movement, Aberhart and his followers able to convert some UFA organizations to SC, movement becomes a full-fledged party in April 1935
hint that what was billed as a reform movement had some reactionary elements, e.g. Aberhart and his lieutenants controlled the party (drew up the platform, vetted the candidates who were selected, preferred small businessmen, only 9 farmers selected to be SC candidates); opposed by the major corporate interests and some businesses (warned of economic disruption, inflationary pressures that would be inherent, government intervention in setting wages)
Aug 1935 provincial election, 56/63 seats went to the SoCreds
15/17 elected federally
the popular vote disguised divisions within society
opted for the quick-fix, the heir to the populist reform tradition (i.e. tax the rich), Aberhart made clear that his reform was preaching reform not revolution, the CCF had not done itself any favours by aligning itself with unpopular UFA elements, getting the votes of angry people
The Rise of the Union Nationale
divisions among the Quebec Liberals, young nationalist intellectuals who pressured for social services and curb foreign control
Action Liberale Nationale formed (ALN) led by Paul Gouin, the grandson of the Parti Nationale founder, supported the nationalization of Quebec’s private power companies, break the dominance of foreign capital and address the marginalization of French Canadiens
to be addressed by a third way
new, no electoral experience, no party workers to run campaign
open to alliance offers…joined the Quebec Conservative Party, who had been in opposition since 1897, dissociated from the federal party, they too criticized the close ties between the Liberals and Big Business, foreign capital, etc.
Maurice Duplessis becomes leader of the Conservatives, as Taschereau’s Liberals faltering, merges with the ALN and other independent nationalists, a significant powerful nationalist party
Union Nationale meant Quebec voters presented with platform for significant political, economic, social reform
Taschereau’s Liberals recognized the threat too late, got a bare majority in next election, first substantial opposition in years
Public Accounts Committee revived under Duplessis, investigate, reveal patronage, government waste, e.g. more than 40 of Taschereau’s relatives employed by the government, and is forced to resign, Godbout takes his place, promises reform (like Martin coming to power)
new election in 1936, UN wins 76/90 seats
results a protest against an economic system and against political corruption, accompanied by a demand for the reform of Liberal capitalism to allow French Canadiens to regain control over Quebec’s resources
Reactionaries in Reform Clothing: Evaluating the SoCreds and UN
Aberhart realizes that Social Credit is impossible to implement
Social Credit Act passed, with a number of other measures, to implement the program, affects banking which is under the federal jurisdiction so it is ruled unconstitutional, Ottawa vetos other pieces of SoCred legislation
what is the social credit party if there is no social credit?
Conservative: from a protest movement preaching radical reform to a conservative, reactionary group that left behind its populist roots
Manning claims that SoCred provided Alberta with the most Conservative government
similar dynamic in Quebec
Duplessis a nationalist but not radical
his concern was not social and economic reform
but he promises to fight political corruption
does not promise specifics
in power, UN largely ignored its stated goal of reforming capitalism, becomes a right-wing anti-labour nationalist party, spends money to promote agriculture in northern Quebec, but neglects urban workers and poor in Montreal
a good friend of liberal capitalism
ALN disillusioned with the conservatism, withdraw their support, many turn to the Liberal fold
Duplessis has a free hand to run Quebec, few restrictions on foreign capitalists, attacks on left-wing activism (those preaching reform), few social services
once again, a party preaching reform that rose quickly to power on a wave of Depression-era discontent turned out to be a reactionary party that maintains the status quo of the liberal capitalist order
Canadian Politics during the Second World War: From Crisis to Reconstruction
Canada’s party politics leading to and during the Second World War were influenced significantly by the memory of the political crisis that erupted over conscription during the First World War;
Wartime issues, notably conscription, shaped party politics in Quebec, leading to the election of the Liberals in 1939, the advent of the Bloc Populaire in 1942, and ultimately, the return of the Union Nationale;
While the CCF and the Canadian Left appeared poised to make a breakthrough during the war, Canada’s established political parties – notably the Liberals – were able to deflect the challenge by moving to the left, maintaining the dominance of liberalism (and Liberalism) in Canadian party politics.
The Road to War
King’s Liberals followed a policy of appeasement, especially Quebec political opinion, mindful of what the last war had done to Canada and the Liberal Party (split), avoid a war, or limit the scope of Canadian participation
King relied on his lieutenant (French Canadian) for opinion
“Twin mantra”: parliament will decide and no prior commitments
Parliament will decide: the government will actually tell parliament what to decide, a stall tactic
No prior commitments: isolation sentiment
Canada would have to increase its defence spending, this revealed the depth of isolationist sentiment in Quebec, Quebec Liberals broke rank and voted against the party, Western Liberals argued the money should go to social spending
Canadian opinion in flux
King made a very pro-British speech, seemed to be going towards the imperialist-nationalist view of Canada
if the Liberals fall, a Union government likely
two months later, following the German occupation of Czechoslovakia
two speeches: King frustrated that Canada called upon to fight in Europe every 20 years, Lapoint speaks against conscription
“No neutrality, no conscription” pact
Canadian parliament declares war after Britain, only four MPs opposed, one of which was the CCF leader Woodsworth, at odds with the majority of his party, Nazi aggression had to be addressed, CCF previously pacifist, Woodsworth stands alone, a bit of a split, he resigns as leader and Coldwell takes over
the scope of its participation had to be decided, King wanted to avoid an all-out war effort (Borden’s all or nothing approach), preferred a limited liability approach
Conscription Crisis, part 1
French Canadians had accepted entry into the war on the grounds that conscription would not be enacted, but young French Canadians actually flocked to the recruiting offices, motivation of employment after the Depression
Duplessis tries to revive nationalist fears, federal ministers intervene in the Quebec provincial election, promises that so long as the Liberals are in power in Ottawa there will be no conscription, Union Nationale are defeated, Liberals come back to power
King’s luck continues into the new year
Jan 1940 the Ontario legislation passes legislation that criticizes Ottawa’s limited liability
Manion (Conservative leader after Bennett), certain level of non-partisanship, Parliament not sitting as this time, assured by King that there would be no election until after parliament had met in Jan 1940, keeps his word, but calls a snap election after one day
Manion was anti-conscription
Liberals win election, Manion loses his own seat and resigns, by Jun most of Europe has fallen, it appears Britain is on the verge of being invaded, limited liability collapses
a second Canadian division sent oversees
calls for conscriptions begin
National Resources Mobilization Act: introduces conscription but just for domestic service
some Liberal members express misgivings about this trend, but King assures them there will not be oversees conscription, still generally accepted in Quebec, but the role of ministers like Lapointe was crucial
pressure grows, Minister of Defence pushes for it
Meighen returns to leadership of the Conservatives, calls for conscription and a Union government, like WWI
Lapointe dies, King loses this support/opinion
spread of the war to the Pacific, West Coast concerns, increasing pressures all over
1942 culmination: King announces a plebiscite, asking Canadians to release the government from its pledge, Quebec is generally opposed, evidenced by the emergence of the pressure group Ligue pour la defense du Canada, country splits along linguistic lines, profound division, King declares “Conscription if necessary but not necessarily conscription”, NRMA revised to permit overseas conscription but not require it, debate causes serious splits in cabinet and caucus, bill passes, government supplies, Liberals stay united and in power
conscription issue continued to have reverberations in Quebec politics
Rise of the Bloc Populaire Canadien
to defend French Canada’s interests, seen as losing its autonomy, especially given close relationship between federal and provincial Liberals
advocates Canadian neutrality, independence from Britain
led by Maxime Raymond at the federal level and Laurendeau at the provincial level
emerges in the wake of the plebiscite
5 MPs in parliament, but disappears from the federal scene by the end of the 1940s
power struggle between its younger and older members
takes votes away from the Liberals at the provincial level and UN return to power
significance in history lies in fact that it was indicative of the socio-cultural transformation and the evolution of French Canadian nationalism
1944 defeat and the return of Duplessis occurred just before the conscription issue re-erupted as a crisis
Conscription Crisis, part 2
King stated in Fall 1944 that overseas conscription would not be enacted
but Canadian forces facing a reinforcement conscription, not enough volunteers, men being killed
Liberals divided along linguistic lines
King suspects there is a plot against him to get his job, he fires his Minister of Defence to reduce the pressure, brings in McNaughton, but he quickly begins suggesting overseas conscription as well, mentions that if it is not enacted King will be faced with wholesale resignations from the military, a revolt, as threatened the English Canadian MPs
looks like parliament heading towards rupture, division of First War, but does not play out, King able to retain the support of his Quebec MPs due in large measure to the threat of a Union government, King gives a powerful speech in parliament addressed to his own party
Conservatives use this opportunity to demand more conscripts, strategy is that if the Liberals bow to the pressure they will alienate Quebeckers and if they don’t they will alienate the Anglos
unfortunately for the Conservatives the war ends just before the 1945 election and the Conservatives call for conscripts to fight in the planned invasion of Japan, serious mistake, English Canadians not emotionally connected to this war
Liberals share of the popular vote declines 5-10% but still hold on to their majority
Conservatives get less than 30% of popular vote, 66 seats
The Centre Can Hold: The Left Challenge and Establishment Response
Liberal economic strategy after the war influenced by classical liberalism
1930s priority was a balanced budget and resisting federal responsibility for social welfare (that’s provincial jurisdiction)
King refers the Bennett New Deal to the Supreme Court, wants the court to rule the legislation unconstitutional, the JCPC has the final word, obliges him, it infringes on provincial power
King appoints a commission to examine two things: the economic basis of Confederation (financial relationship between the levels) and the power relationship (distribution of powers between the levels)
Relief Act, 1936, cuts the level of grants in aid to the provinces in order to balance the federal government, the relief camps are closed, King Liberals concerned that they were breeding discontent and dependency and radicalism
Liberals create a National Employment Commission to examine the unemployment problem, to King’s horror it recommends a Keynesian response, some deliberate deficit spending in 1938, but really King not breaking with classical liberalism, a result of cabinet pressure, throws a bone, some public works, would take the war to change this
money spent during the war that wasn’t spent during the Depression, a wartime economic boom, seems to support government intervention can ensure prosperity and social security, seems to support Keynesian economics, pressure on King
Ottawa should have constitutional and taxation powers to create a welfare state, King resisted, but did adopt unemployment insurance to prevent agitation
it was the challenge from the left that moved the Liberals away from liberal economics
socialism received its greatest support when prosperity returned, those enjoying prosperity more generous, wanted it to continue
radical movements come when expectations rising
CCF becomes a major political force in the 1940s, e.g. Arthur Meon loses his seat to the CCF candidate, to the West of Ontario for the first time
CCF forms a minority government in Ontario, polls find it the most popular party in the country, under Tommy Douglas elected in Saskatchewan as the first avowedly socialist party in North America
provokes the transformation of Canadian parties
Meon resigns, wants a leader that can sweep the West
discussions in Port Hope in Sept 1942, The Port Hopefulls, Conservative party talks about adopting social welfare legislation like medical insurance, adopt the Port Hope agenda
name changed to Progressive Conservatives under new leader
as for the Liberals, the CCF challenge, shift to the left, espouse reform liberalism: continuation of free market but responds to demands for full employment and social welfare, endorse the report on social security for Canada, want to prevent socialism, different from the CCF agenda, e.g. no endorsement of public ownership or a maximum income, a baby bonus introduced, popular in Quebec where birth rate high and support low, King ensured that the first baby bonus cheques would not arrive until after the next election in 1945, incentive
The Nationalist Impulse in Canadian Party Politics in the 1960s
Main Arguments:
The rise and fall of the Progressive Conservatives led by Diefenbaker may be interpreted as the manifestation of a growing nationalist reaction in Canadian political life of post-1945 international trends and their implications for Canada, notably in terms of relations with the US;
Returned to power in 1963, Liberal Party fortunes were also linked closely to this nationalist reaction playing out in Canadian political life;
The impact of nationalism on Canadian party politics was not limited ot the federal level; in addition to responding to these same post-war international conditions, there was a growing reaction in Quebec to Canada’s internal political dynamic. This response would have a major effect on party politics on both the Quebec and federal political stage.
The Growing Nationalist Concerns about Canada-US Relations
the forces of globalization (economic interdependence, cultural exchanges) undermining state sovereignty and its ability to respond effectively to transnational issues
Canadian policy shaped by this evolution
one of the chief reasons for the post-war economic boom was the strengthening of ties between corporate Canada and corporate America
Ottawa was in debt because of the war years, reliant on American capital
Americans could ensure economic boom continued
the international economic order that fell apart in the war began to be reconstituted under the preponderance of American economic power (multi-lateral trade, communication and transportation advances, economic interdependence)
in the two decades after the war the value of foreign trade grew exponentially, rose largely from the spread of MNCs
Huntington: “ushered in the American Empire”
the older post-Confederation east-west economy (Canada and Europe) was increasingly oriented within North America
the PCs embraced this growing economic integration, the CFF even supportive, a means to fund the welfare state
growing concerns in the 1950s about the implications for Canadian sovereignty, culture
the opposition parties take a closer look at Ottawa’s foreign investment policies, Liberals are compromising the Canadian national interest, trading its long-term economic development for short-term political advantage
Liberals hold a public inquiry on the issue, the Gordon Commission released its report in 1957, foreign investment in and of itself not a good thing, opposition parties put Liberals on the defensive, Gordon Report was a watershed in Canadian life, it legitimated concerns about American influence in the country
new project: construction of a national pipe line, growing American influence in the project, the PCs and CCF criticize the Liberals for selling out to the Americas, this debate combines with the Suez Crisis
Liberals accused of siding with the Americans against Canada’s two mother countries, Britain and France intervene, and Canada seems to side with America by engaging in UN peace talks instead (oh fuck off)
The Rise and Fall of the Diefenbaker Reaction
connection between the fact that Diefenbaker was capitalizing on this sense of marginalization and the larger political sense generally shared by Canadians that Canada as a whole was becoming marginalized, a periphery of the American Empire
Tories call for a reduction in Canadian dependence and a revitalization with the UK and the Commonwealth
Diefenbaker: “Create a new sense of national purpose and national destiny” (challenges the Liberal continentalism)
Canadian electorate agrees, they want a country developed by themselves according to their own destiny, a nationalist reaction to transnationalism
in office, the PCs have a difficult time realizing this vision, stemming the tide of transnationalism and globalization
D’s nationalism was trumped by his anti-Communism (means that Canada-US defence relations are going to continue) and his commitment to private enterprise (liberal capitalism)
in the military sector, the adoption of NORAD and the development of the Development Production and Sharing Program (enables companies within Canada to bid on equal terms with American firms within the military industrial complex)
in the economic sphere, D promises to divert 15% of its American imports to British imports, diversify, but this never happens, Canada committed to multi-lateral trade, government intervention frowned upon, D does not rise to the debate that Britain and Canada should establish a free trade agreement
tension between D nationalist reaction and North American integration demonstrated most dramatically when Ottawa requested to accept American nuclear warheads on Canadian soil, seems to have agreed, but Kennedy and D had a poor relationship, growing pressure to clarify, and ultimately the issue is resolved in 1963 when there is a cabinet revolt (Minister of Defence resigns) and the government falls
the election is about the growing nationalist reaction, Canada’s place in the world
Pearson under fire for flip-flopping on the issue of the nuclear warheads
D tries to portray himself as the defender of Canadian independence
the first election in Canadian political history in which a dramatic appeal to nationalism (anti-Americanism) did not carry the day
Liberals come to power
Grant sees this as the death of Canadian nationalism, an independent Canada (see course reading)
The Nationalist Element in Canadian Party Politics, post-1963
the continentalist version seemed to have carried the day, but nationalist sentiment continued, e.g. new Canadian flag
the dispute over which vision of Canada was going to prevail: Anglo-British (D) or North American
divisions between the Liberals and Conservatives over the flag
Liberals lured Walter Gordon (of the report) into their fold, had him run, Pearson endorsed the economic-nationalism that he supported, Gordon appointed Finance Minister, Liberals appear to be embracing economic-nationalism, but their embrace was not off to a good start when Gordon delivered a budget that reflected the strength of Canadian nationalism, e.g. designed to discourage foreign investment by implementing a “takeover tax” for example which added a charge for foreign firms purchasing Canadian firms and the taxes on dividends, reward for Canadian-owned companies
this economic nationalism provokes a negative response from the business community on both sides of the border
not implemented
Gordon calls for Canada to oppose the escalation of fighting in Vietnam, was not authorized to do so, outrage from Pearson and Paul Martin
Merchant-Heeney Report calls for Canada to work out its differences with America through private diplomacy
Pearson distances himself from this report, acknowledging the strength of Canadian nationalism
nationalist wing led by Gordon; continentalism led by Sharp (Foreign Affairs)
Watkins Task Force, report released in 1968, economic nationalist, shapes the discourse in the 1970s and beyond (implications for the Trudeau era to be discussed), as such Gordon created a new generation of leaders and the nationalist cause, a bridge between imperialist nationalism and the more recent economic nationalism, with an Anti-American threat running through
The Nationalist Response in Quebec Politics (pre-1960)
the elaboration of the Canadian national state provoked a response from Quebec (nationalist) reflected in the evolution of party politics within the province
rising from the wartime experience, moving towards a more technocratic state
at the federal level the Liberals favouring a welfare state from coast to coast to maintain peacetime prosperity, a new federalism, grants to universities, social programs
drew attention to the nature of the BNA and the division of Canada (power relationship, power balance)
an early reaction on the Quebec stage was the Bloc Populaire Canadienne, the Bloc was an attempt to elaborate an alternative to a federally-dominated welfare state, saw this as the thin edge of the wedge, first stage of Canada ultimately moving towards a unitary stage, implying the loss of Quebec’s autonomy
Bloc argued Canada was a political construct, needed a clear division of powers guaranteed
on one hand a more secular, urban, liberal Quebec nationalism and on the other a more Catholic, rural, Conservative Quebec nationalism
they argued that a strong Quebec state was needed to overcome this challenge to French survival, a powerful centralizing Anglophone welfare state administered by Ottawa (boo hoo) that would not take into account the needs and values of French society and therefore undermine it
Quebec should not be forced to choose between these, should be able to have both, in the form of a Quebec welfare state
the Bloc Populaire can be seen as a transitional party between the Union National and the more modern, secular nationalism of the Bloc Quebecois
because of these conflicting currents within it, the Bloc fails
main nationalist response articulated by Maurice Duplessis (Union National)
Note on Bryden Article: Liberal Party Dynamics and the Achievement of Medicare, 1965
These great accomplishments occurred in spite of, not because of, Pearson
As an opposition party, the Liberals were more left-leaning (e.g. progressive social policies) than they were when elected (with Pearson at the helm in 63 and 65)
There were positive federal-provincial health-insurance discussions going on in 1965 that alarmed the Conservatives, with July 1 1967 the “realistic target date” for starting a national health-insurance scheme (oh, and the Centennial)
Alberta represented a problem, Premier Ernest Manning objected to an arbitrarily universal scheme that limits freedom of choice
But social policies (or policy issues of any kind) did not play a major role in the 1965 election, in fact of more significance were scandals that had plagued the Liberals since gaining office, and the outcome was just two more Liberals, two seats shy of a majority government
The party moved to the right, Gordon resigned, and the Toronto Star commented: “The man Pearson chooses to fill the key post of Minister of Finance will largely determine whether the country’s economic resources will continue to be directed towards social reform and economic independence.” Sharp’s appointment caused some serious doubts over the future of medicare.
Hesitation clouded 1966, with fretting about the cost and priority of medicare and a one-year delay was announced, this was okay with the provinces, they were reluctant to commit themselves, costs, and the blame on federal shoulders was to their advantage
Sharp met with the provincial finance ministers, Quebec proposed the implementation of a national health insurance “gradually”, Sharp started to warm to this idea, Ottawa looked unwilling to discuss if it stuck to its own criteria
E.g.: Robarts stated that Ontario would not participate in the national medicare plan because “under present economic conditions Canada cannot afford the ‘universal’ scheme” and because his government was philosophically opposed to the idea of a compulsory plan.
Cabinet decided to go ahead with medicare for July 1, 1968, why it did not delay is unknown, as the PM appeared to have believed that all the provinces should be brought in at once even at the expense of some of the previously stated national criteria (so who was on board!!??)
“Lament for a Nation”
Canada sold out to economics and sacrificed its identity
fighting against globalization, not fighting for Canada
so when was the glory period?
Grant looks at French Canada as the only true culture, an example of nationalism, in contrast to Canada, the traditional nationalist tendencies
use of paternalistic language, the Liberals have taught the masses to accept the inevitability of this wave
we value of standard of living more than our autonomy
narrow definition of nationalism as economic
“Pearson and Health Care”
the Kingston Conference: start of a new direction, party renewal, after defeat
move to the left, reaction against the newly forming NDP, shift towards intervention
reaction from the top was negative, hesitant
the grassroots intelligentsia gaining strength and influence
the ensuing Liberal Rally reinforced the Kingston Conference, showed that the party had in fact lost touch with party members, the new leftist direction was affirmed
Politics in an Age of (Quiet) Revolution
Main Arguments:
The Quiet Revolution – and its implications for party politics on both the Quebec and federal political stages, may be understood as part of the nationalist reaction to post-war international trends that we began exploring last class;
The endurance of the “national question” and the ascendancy of neo-nationalism in Quebec political life led to a fundamental realignment of the party system in Quebec that included the decline of the Union Nationale, the Quebec Liberals taking a more nationalist stance, and the rise of the Parti Quebecois.
The realignment on the Quebec political stage had implications for the federal political parties. The PCs under Diefenbaker were slow to respond to the implications of the QR; the Pearson Liberals were more conciliatory, but limited in their margins of manoeuvre owing to their minority situation. Ultimately, the QR and growing questions over Canada’s future provoked changes in the leadership of both of the main parties.
Background to the QR
stability and stagnancy at the federal level paralleled by stability and stagnancy at the provincial level in Quebec, Union Nationale in power from 44-60, autonomy still a pursuit
traditional nationalists argued that French Canada’s autonomy could be ensured if there was a return to pre-war federalism and provincial jurisdiction was respected
as Duplessis battled the “new federalism” of the 1950s trying to win back the provincial powers that Ottawa had tried to take over (e.g. taxation) there was concern rising among neo-nationalists who felt that Duplessis and the UN only had half the equation: yes, Quebec autonomy had to be protected, but at the same time the UN government was not doing enough to build up Quebec City so that Quebeckers could run the welfare state
neo-nationalists further concerned about foreign economic presence in Quebec
we need a dynamic, interventionist Quebec state, ensure that Francophones will be present in the private sector, the social and cultural institutions to ensure national survival
a homogenizing effect as Quebec increasingly integrated into the global economy… assimilation?
in response, the Tremblant Commission appointed, to examine the nature of Quebec’s relations with the rest of Canada, Commission’s report influenced heavily by the neo-nationalist position
political dominance of the UN at this time meant that the recommendations of the Commission, the appeals of neo-nationalists, increasingly fell on deaf ears, no action
UN able to perfect its formula for political success: it had no official membership, no internal mechanism for consultation or decision-making, consisted of elected members, defeated candidates, and their local organizations (which distributed patronage), so fairly decentralized on one hand, but power was highly concentrated
UN the classic case of a traditional party that became warn out from spending too many years in power, appropriate organization for the first half of the 20th century, but no longer, left vulnerable by neo-nationalist attacks
Paul Sauvé replaced Duplessis when he died, credited with getting the beginnings of the QR underway, but he died too
UN divided, weakened, under the leadership of Antonio Barrette, weakened within
opened an opportunity for the Quebec Liberals, the perennial opposition party, had a hard time staking out a Quebec-centric position, led by Godbout and Lapalme, portrayed as federal vassals, under their control
1955: Quebec Liberal Federation established, the first specifically Quebec-structure that the Liberals had, suggests growing strength of nationalism in politics, the furthest that any Quebec Party had ever gone in terms of internal democracy, this re-organization helped the Liberals build support beyond their traditional ways, able to win an increasing proportion of the working class vote, also able to establish a stronger presence in the rural regions
Laplame eventually forced to resign, becomes House Leader, also given the task of developing a new platform, happens to be inspired by the Tremblay report
Lésage becomes the new leader, a former federal cabinet minister under St-Laurent, goes about building his “team of thunder”, including Rene Lévesque, determined to make the Liberals the rallying point for the anti-UN, the anti-Duplessis
now espousing the neo-nationalist ideal, campaigned on the slogan “It’s time for a change”, they win in 1960, but very narrow majority, efforts of the Quebec Liberals to increase their share of the rural seats to be credited
Quebec government grows exponentially, 6 new ministers, 8 public enterprises, including Hydro-Quebec,
election called, hope to consolidate their position over the UN, “Masters of our own house” slogan, increase their seat count to 63, QR seems to be progressing quite nicely
before 1957, there was no distinct Quebec Liberal Party that was a member of the national Liberal federation, no distinct entity, instead the Quebec lieutenants overlooked affairs in Quebec, as the Lésage Liberals adopt a more federalist position problems were created, Quebec Liberals torn between the federal and provincial level
formal split between the two parties suggested, Lésage wanted to be dissociated from his federal cousins, the feds were concerned about the amount of power Lésage had, ability to dominate both Quebec and Federal Liberal parties
tensions paralleled amongst the Liberal members themselves, e.g. Lévesque, Aquin, and Gérin-Lajoie, who take a more assertive nationalist stance
results of the QR do not seem to be panning out as quickly as voters would like
growing reaction to the QR and to the Liberals was the UN, trying to work out of opposition, they had been significantly discredited by the results of the Salvas Commission (Duplessis and corruption scandal)
The Return and Decline of the UN
Daniel Johnson elected as new UN leader, seen as a triumph of the old party, but some attempts to modernize its structure and policy, e.g. holds first-ever policy convention in 1965, clear that it is shifting towards a more neo-nationalist tradition, rise in the party of younger members to leadership positions
the problems that arise from a first-past-the-post position, loss of Liberal support in 1966 election, partially to new independent nationalist parties, the UN wins a majority government but they do this with less votes than the Liberals had received in the election, the UN able to form the government with less than the share of the popular vote than they had received in 60 or 62, bizarre
UN promised a new relationship between Quebec and the rest of Canada, debate takes on a new intensity following the UN’s election, had divisions between its more federalist wing and its more nationalist wing, like the Liberals, ambiguity in Johnson’s “Equality or Independence”
after Johnson’s death, power struggle between nationalist and federalist wings, new leader is weak, not much confidence from party, party also weakened by student protests, growing labour strikes, increasing violence from the FLQ, controversy over linguistic rights in the late 1960s
the decline of the UN paralleled by the rise of the Parti Quebecois
The Rise of the PQ
RIN founded as a movement in 1960, transformed into a political party in 1963, drew conditions between the Quebecois and the decolonization of the third world countries
Ralliement National, group of dissident Social Credits
Quebec Liberal Party, group of more reform-minded Liberals discussing new direction, “Where do we go from here?”, during this meeting Levesque begins to talk about what will become known as sovereignty-association, nationalist pride, also holds that it would be more effective to end the federal-provincial fighting
Oct 1967: Levesque’s resolution defeated, walks out of party’s policy convention with a few supporters, a month later form the Movement Soverginete Association, a more independence-minded association, early fight over the language question (Levesque was moderate, conciliatory, anglo rights had to be protected and guaranteed, reflected pragmatism, a mainstream alternative)
some talks of a formal merger between the RIN and MSA but not fruitful, a coalition, individual members join the new Parti Quebecois
ambiguity of sovereignty-association vs. new party’s diverse, intellectual membership led by the charismatic Levesque, able to front an early challenge to the two major parties
four major parties contesting election for first time: Liberals shied away from any aura of separatism, Bourassa proposes profitable federalism (economic development and jobs), UN had not really redefined itself but pushing for special constitutional status, the Ralliement Creditiste a right-wing social credit party
electorate divided, number of contenders, first-past-the-post produces interesting result, Liberals win a comfortable majority, the Creditiste have regionally concentrated supported and win 12 seats with 11% of the vote, the UN formed the official opposition but support declining, relative success of the PQ, Levesque is defeated in this election, PQ only win 7 seats, but 23% of the popular vote, more than the UN or the Ralliement Creditiste
a polarization of Quebec politics over the issue of sovereignty
outcome interpreted as a triumph of federalism in English Canada, but they were a source of bitter resentment, the October Crisis occurs only a few months later, even though there is a strong, popular party advocating separatism the system is stacked against it, sense that democracy is not working, it is preventing the Quebecois from practicing their right to self-determination
Federal Repercussions:
The Diefenbaker-Pearson Era
“Win Without Quebec” strategy adopted by the PCs
PCs rely on the UN to organize on the ground
Diefenbaker willing to offer only symbolic gestures, e.g. adopting federal bilingual checks
PCs could not consolidate, their support in Quebec in 1962 collapses
reflecting the alienation of Quebec voters from both parties, Caouette and the Ralliement Creditiste comes out of nowhere to win 1/3 of the federal seats, a reflection of the nationalist response to globalization, a right-wing protest, Cauoette an evangelical nationalist, appealed to the little guy in the rural region
Tories only able to retain office in 1962 because the Credistic success was so large that it reduced potential for Liberal gains
three consecutive minority governments at the federal level
Pearson not regarded as strong enough
New Realities, New Leaders
Politics in an Age of ‘Liberation’
Main Arguments:
It was only in the 1960s and the advent of second wave feminism that women began to win a more prominent place in political parties and in Canadian political life;
A theme running through the various manifestations of the feminist movement in Canada has been ambivalence toward party politics. This has arisen from the dilemma over whether it makes more strategic sense in pursuing the feminist agenda to engage in partisan politics or to maintain a distance from the established political order.
In general terms, the pattern that prevailed from the feminist mobilization of the 1970s onwards was one of accommodation. The three parties vary somewhat in their commitment to the numeric and substantive representation of women, but all three actively tried to accommodate (up to a point) the feminist movement.
Women and Political Parties, 1917-1960s
The Rise of Second Wave Feminism
The Feminist Challenge and the Parties Respond
“The Liberal Order Framework” – the notion that the established socio-economic order will adapt in order to retain its grip on power.
Canadian Feminism
has always had an ambivalent relationship with political parties
called for an opening, for a response
on the other hand, feminists have mistrusted parties, elitist organizations, at their most extreme are antithetical to women’s interests and responding to the feminist agenda
early Canadian suffragism was part of a broader progressive challenge to the traditional party system, politics as usual, and this immediately gave rise to a fundamental dilemma
early feminist groups attracted to a position separate from the parties, guarantee autonomy, not be co-opted, maintain idealism and ideological purity
on the other hand, also drawn to more active participation in party politics, by engaging in the established order, perhaps the feminist agenda could be achieved more effectively
tension between independence and partisanship, principle and pragmatism, within or outside the system
this dilemma has shaped the relationship between women and political parties ever since
initially, the extension of the franchise to women has little impact, especially within party ranks, feminists and enfranchised women split along the same political and class lines as men
an attempt to establish a National Women’s Party but it failed, derided, too elitist, urban, Conservative, pro-war, anti-labour
an exception to the “limited gains” rule was the New Era League (NEL) which had close ties to the BC-Liberals, Mary Ellen Smith appointed to the cabinet, first woman in the entire British Empire to occupy a cabinet position
another important achievement was the Persons Case, led by Judge Emily Murphy, two-year legal challenge to have women recognized as “persons” and enable them to sit in the Senate
also significant is the fact that Quebec feminists won the provincial vote
but the experiences of, for example, Agnes Macphail, was limited, like the suffrage movement itself she rejected conventional partisanship, established her political career outside of the party system, on the margins, was a member of the Progressives then the CCF, this limits her impact, not in the ranks
level of female participation limited by the same socio-economic conditions that marginalized women in society at large (economic independence, relatively low level of higher education, social pressures regarding marriage and childbearing, and traditional norms that dictate females were unfit for political office)
none of the “Famous Five” appointed to the Senate, seen as feminists, King Liberals appoint Cairine Wilson who was seen as more moderate
those females elected to the Senate at this time were largely replacing male family members, name recognition, keeping the seat warm for a husband or father, nearly half of the 17 women elected were in this position between 1921 and…?
women clustered at the municipal level, attributed to costs (less costly election campaign), manageable travel (close to home), and weaker power (political parties don’t wield the same influence)
attempts to remedy the situation at the federal level, e.g. establishment of the Women’s Joint Committee, women to obtain more power within the parties, but weakened because of perception that it leaned too far left, strongly pushed for accessible birth control and for equal pay, and female leadership
women’s auxiliaries, e.g. National Federation of Liberal Women, first assembly in 1928
Women’s Committee within the PC under the leadership of Hilda Hesson later on
activities undertaken like a “ladies aid”, raising money through teas, luncheons, cookbook sales, members performed clerical work, social entertaining, fundraising, explicitly mirrored the gender division of labour in society, not influencing fundamental decision-making
observers describe this as “the auxiliary trap”, a ghetto within the established political order, limited participation
the egalitarian ideology of the CCF combined with the challenges it was having establishing itself ironically impeded the establishment of a formal auxiliary within its ranks, but large portion involved in the same sorts of activities as the Liberals and PC counterparts
CCF claimed to be the best representative of women’s rights in Canada
WWII tended to stifle limited success
The Rise of Second Wave Feminism
growing sense that more was required, greater opportunity for women within the parties
easier said than done
1942: Ontario CCF established Women’s Committee to recruit more voters, but what is the level of influence, how much power, a lot of CCF activists feared that a separate committee would threaten CCF unity, ends up performing the same sorts of “auxiliary” functions
NFLW has expanded by the end of the war, more than 100 clubs, extensive membership, a growing number of women being mobilized and integrated into the progress, but the NFLW’s activities to the extent that they dealt with policy were limited to points on welfare
PCs formally committed themselves to women’s policy, but they were marginalized, generally speaking they were ignored between elections although called upon to work during the elections
ultimately the rise of second wave feminism provoked significant change
after the gains of the suffrage movement the Person’s Case, women largely went back to their domestic roles
female employment in the industrial sector increased during the war, but then policies deliberately designed to re-establish the “spheres of activity” after the war
growing segment of the female population, especially amongst the middle classes, obtaining formal education, encouraged to pursue a career (until marriage)
increasing number of women, like Doris Anderson, refused to be forced between the choice of career or family, through her editorship at Chatelaine she promoted this idea, an appeal for more women to run for public office
Voice of Women (VOW) a grassroots organization formed to oppose nuclear proliferation and nuclear testing, claimed to be non-partisan, but because of the crisis over the Bomark Missile Crisis, faced with dilemma, same as the first wave feminists, how best to achieve goals: engage or reject
1965: Conference marking the 25th anniversary of women having the provincial vote in Quebec, representative of the Liberal mainstream movement (Federation des Femmes du Quebec (FFQ), more radical ones also existed, e.g. Front de Liberation des Femmes du Quebec (FLFQ)
two women in parliament at this time: Grace McKennis (CCF) and Judy LeMarch (Liberals)
Pearson government responds by appointing a commission on the Status of Women, in 1970 the report, Committee for the Equality of the Status of Women, goes national, National Action Committee on the Status of Women, goal to enact the recommendations, pressure on government, NAC bridged one of the divide within the women’s movement between the more conservative older generation and the more radical younger generation
The Feminist Challenge and the Parties Respond
led to a re-examination of the role of women within Canadian life
Liberals advocated a moderate involvement, made sense at the time, the Keynesian era party system, when the state could effect change and best way to ensure it was to influence the parties that were in control, women’s movement call for more women within parties
this effort was multi-partisan, strongest with the NDP, but also strong with the Liberal party
less visible but equally important was radical feminism, rejected engagement, to sanction a patriarchal position, FLFQ rejects forming a strictly women’s party because it viewed even that as being co-opted
major re-thinking of their goals in late 60s and early 70s, women were remaining marginalized, recommended that auxiliaries be integrated within the parties, acting on the recommendations of the Bird Commission the NFLW (31 000 members) replaced by the National Liberal Women’s Commission (NLWC), as opposed to being an auxiliary (separate) it is formally integrated, main tasks are changed moreover, as opposed to “tea-pouring” the new commission was supposed to promote the advancement of women at all levels in the party and in parliament
the PCs also moved in this direction, although more slowly, occurs in 1981
NDP most immediately effected by second-wave feminism, not surprising, it arose from the left because of the left’s claim of greater equality, reality not matching rhetoric, Women’s Committee in 1961 accompanied the establishment of the NDP, relationships between the established party and the feminists was initially conflictual but they moved towards the centre, e.g. the POW Committee designed to advance the representation of women in mid-70s
1977: PQ established commission for the women
more problematic than transforming the auxiliaries was increasing the number of women sitting in the H of C and in the party organization…even today, the higher the fewer!
Doris Anderson: the established political order not for her, forced to run against another Liberal candidate for the nomination in a riding even after she had well established herself
initial enthusiasm DIES
might think that the NDP is more advanced, has had two female leaders, had nominated more women, but mostly done in un-winnable ridings, number in the House no greater than the Liberals or PCs until the 1970s
parties shy away from a quota approach of candidates in elections
but from the mid-80s and into the 90s, number of women in the house grew significantly, move towards a moderate position, no party sought to become the party of feminism but no party sought to become its antithesis, either
the Liberal Order!!!!
since the 1990s, the growth in the number of female proletarians has stopped, the number of female candidates being fielded had declined
the first-past-the-post system may be serving as a barrier…
Doris Anderson became a strong supporter of the PR system in the last years of her life after having studied the European system
appears to be more than just a question of numbers, e.g. in 1993 two female party leaders in election, however feminist issues were marginalized, parties seem to be moving towards a symbolic approach, increase the numbers, but when it comes to substantive advancements little progress is made
in conclusion, this brings us back to the question of participation vs. opposition: the Persons Case, the Bird Commission, the feminists agenda within parties, the entrenchment of gender equality in 1982…really, we should cease viewing participation and opposition as mutually exclusive, political parties exist to win elections, feminists must mobilize support and then engage with those parties, make it self-interest, complimentary
What’s ‘Left’ To Do?
ARRIVED LATE
(look up arguments and first few minutes of material)
From the CCF to the NDP
CCF had developed its program during the depths of the Great Depression, did not have the same resonance after WWII, economy booming, unemployment low, under these conditions voters were satisfied with the Liberal’s piecemeal approach to social welfare, living standards seemed to be improving without the election of the socialists
degree of “red scare”
CCF of decreasing relevance
each election after 1945, CCF lost progressively more support, peaked in 1944, and then dropped in four subsequent elections
leader MJ Coldwell defeated and deputy leader Stanley Knowles defeated
seems headed for the same fate as American Socialist Party (oblivion)
party morale and membership falling
ability to find funding (to mount election campaign) restricted
as a desperate holding action, issued the Winnipeg Declaration at the height of the Cold War, reflected a worldwide defeat on the best means to achieve socialism and what kind of socialism it should be (more communist or more liberal), reflected a shift away from the radical Regina Manifesto, moderation, e.g. dropped the promise to eradicate capitalism, endorsed the mixed economy, government intervention but private sector endorsed, shift from government ownership (nationalization) to the promotion of social welfare (low-cost housing, post-secondary education funding)
this was a tacit acknowledgement of the strength of the post-war consensus on reform liberalism
hope that a more moderate image would attract voters, shift towards the centre
sought to forge ties with the expanded industrial force, shifting from its Western rural roots, attempt to seduce industrial workers, encourage the more Conservative union leaders to support the CCF, reflects the fact that the relationship between the CCF and organized labour had been problematic, e.g. in Ontario there was joint action between them but it was limited to the electoral period, rarely any substantive cooperation, union support for the CCF at the level of individual membership was lacklustre
because significant portion of the CCF feared a close relationship because they thought the unions would come to dominate the party and members usually voted Liberal or Conservative
begin to shift towards greater cooperation in the postwar period, especially in light of electoral setbacks, encouraged CCF to seek out the support of organized labour
1940: merger of more radical unions to form the Canadian Congress of Labour, a rival federation, could challenge the Trades and Labour Congress which was more Conservative
TLC: growing number of CCF supporters, including Claude Jodoin, president of the TLC, discreet CCF supporter, important because his presidency paved the way for the unification of the more radical CCL and the more conservative TLC into a new broad union federation, the Canadian Labour Congress, 1956
shock of the CCF’s electoral defeat in 1958, push for cooperation, proposal for creation of a new party, vehicle for a new broad based political movement that would incorporate in a significant way the labour movement
The Founding of the NDP
took 3 years to bring about a formal alliance between the CLC and CCF
2000 candidates descend on Ottawa, from the CCF and unions and new party clubs, lobbying for a new alliance, this convention succeeds in establishing the NDP
Premier Tommy Douglas drafted as the first leader
the impact of the alliance was limited by the fact that in 1961 less than one-third of the non-agricultural workforce was unionized, 75% of union members continued to vote for the Libs or Cons, never really produced poll results, most significant contribution was financial, NDP could rely on organized labour for funding, but trade unions banned about three years ago from making contributions
movement towards the centre appeared to make a difference
Douglas defeated in the election, but share of popular vote increased, 13.4% of the votes and 19 seats, best result since 1949
won power in MB, SK, BC before the end of the decade
The Movement vs. Party Dilemma
“movement to Party” thesis or “protest movement be calmed”: two conflicted antagonist elements in the CCF and NDP, the first being a social movement favouring a more principled, doctrinaire approach, shaping policy and the public discourse; the second is the party element, pragmatic, willing to compromise to obtain power
this thesis articulated by Walter Young, “Anatomy of a Party”, argues that the establishment of the NDP reflects the pragmatic element increasing, says ultimately the NDP has evolved into a party like its competitors, want power, willing to compromise
this is consistent with a broader element in political party, as left-wing parties mature, especially the leaders, they are increasingly driven by a ruthless desire for electoral success
Antonia Maioni argues that in comparing America and Canada in health care reform, presence of the CCF/NDP led to a much more comprehensive system of health care in Canada than in the US, it makes a difference
McKay is more cynical, decries the fact that the new democracy has been contained and ultimately defeated through the conciliatory approach of the established liberal order, compromise to form a limited social safety net, deflected the challenge from the left
symptomatic of this movement was a disruption in the NDP caused by the challenge from the party’s left wing in late 60s/early 70s
The Waffle Movement
consistent with the shift towards the centre, the references to socialism in the New Party Declaration were downplayed, also differs in another way, a lot more references to nationalism, concern about independence and autonomy of Canada, consistent with the rise of Diefenbaker and the Liberal’s response, rise of the Parti Quebecois, playing a greater role all over, NDP had to react to the advancement of globalization
nationalist reaction was a major cause of the radical leftist movement “the Waffle Movement”, strongly ideological
name: a meeting of radical leftist members of NDP, in the course of their discussions, debate over a specific issue, “waffle to the left”
definitely symptomatic of the movement element of the NDP, argued that the NDP needed to adopt a much more radical program to respond to the growing presence of America in the economy, a threat to Canadian independence, inspired by the significant popular demonstrations in Paris in 1968 and new left movements
foremost spokesmen were Laxer and Watkins, argued that nationalism and socialism were inextricably linked, if an independent socialist Canada was to be achieved, NDP had to be an agent of both, Canada owned by Canadians, advocated nationalism of all major industry, fundamental redistribution of all decision-making powers
much more assertive socialism of the CCF in 1930
provokes a reaction from the NDP establishment, the mainstream, deputy leader Lewis and Ed Broadbent, criticized the Waffle Manifesto for its strongly anti-American tone, emphasising public ownership, a question of political pragmatism, what would happen in terms of public support if the Waffle gained ascendance in the NDP
“Marshmellow Resolution”: it is soft and mushy response, the most advanced economical position, but rejected as too moderate by the Waffles, provincial Waffles emerging in ON, BC, SK
David Lewis especially concerned about the Waffle implications, feared the radicalism would undue all post-1930 efforts to become a mainstream social democratic party, alienate organized labour, keep the NDP from winning elected office
1971 leadership convention: Lewis replaces Douglas, determined not only to win the leadership but to discredit and marginalize the Waffle, reassert the influence of the mainstream leadership of the NDP, but unable to do so, a lot stronger than anticipated, James Laxer (also leadership candidate) comes in second place, real grassroots challenge going on within the NDP
leadership losing control over party
members of Waffle having increasingly tense relationship with organized labour
unions threatening to withdraw their financial support (one of the very reasons for the NDP’s formation)
1972: Waffle is effectively purged from the ranks of the NDP, “waffle was toast”
years following the disruption a period when pursuing the pragmatic course appeared to pay dividends for the NDP
1972 federal election: Libs fall to a minority position mainly because voters attracted to the economic nationalism of the NDP, Lewis conducted effective campaign against corporate welfare funds, and NDP holds the balance of power in parliament until 1974 until Trudeau Liberals engineer their own defeat, the alliance resulted in a number of measures like the establishment of the Foreign Investment Review Agency (FIRA) mandated to review and with the power to reject any potential foreign takeover of a Canadian form, also established the Canadian Development Corporation, tasked with buying back Canadian companies, also Liberals began indexing pensions to reflect inflation, also take the first steps in establishing Petro-Canada
this seems to have been the high point, NDP more successful than the CCF, average of 17% of the popular vote between 62-88, above the CCF’s average of 11.1%, it has undergone considerable existential angst
mid-1980s: under Broadbent, the party witnessed a new high, by 1987 Broadbent was the most popular leader in Canadian politics, predictions that they would form the official opposition, attracting left-leaning Liberals and the working class, speculation that the Liberals would be marginalized, battle between left and right eventually
Free Trade election of 1988: NDP won all-time high of 43 seats, but all of these seats West of Quebec, failed to achieve Official Opposition status
resurgence of the “principle vs. pragmatism” debate
Broadbent blamed for taking a pragmatist approach that allowed Liberals to take an anti-free trade vote
Steven Lewis (David’s son) argued that the NDP had to return to its traditional role as the “conscience of the nation”, change public policy, not obtain power
following the upset in ON, 74 seats in 1990, first time an NDP government formed east of MB, Rae was a pragmatist, wanted to make the NDP a more centrist/left of centre political vehicle, transform the NDP from a permanent party in opposition, subsequent difficulties of the ON and federal party reflects the fact that the NDP has been unable…
throughout its history, the CCF/NDP has moved towards the centre, reflects the strength of liberalism in Canadian politics, in trying to reconcile its rival vocations as a movement and political party, the NDP could end up being neither
The Medium is the Message: Politics in the Television Age
Main Arguments:Television had a fundamental impact on party politics in Canada, leading to the ascendancy of image over content; this trend was most dramatically manifest in the 1968 phenomenon known as “Trudeaumania”;
Television had a centralizing effect on party politics in that it provoked a greater attention being paid to the leaders – as evidenced by the media event that is the leader’s tour during election campaigns – to the increasing exclusion of regional lieutenants and local candidates;
Paradoxically, while television had a centralizing effect through its encouraging greater attention to the leader, it also provoked attempts to ensure (at least the appearance of) more transparency, accountability, and grassroots participation.
Television on the Rise: The Diefenbaker-Pearson Era
Politics as Spectacle: The Trudeau Era
Television’s Impact (1) Follow the Leader (2) Democratizing the Parties
Recent Example
Harper’s pre-emptive attack ads on Dion
Television on the Rise
1951: only 1% of Canadian households had a TV set, a decade later it was 83%, more people than had flushing toilets
the pipeline debate played out on the new TV sets, contributed to a growing impression among voters that the Liberals had become too comfortable in office and too complacent in power
to the advantage of the PCs, Diefenbaker’s rise, took advantage of the medium
federal campaigns of 57 and 58 were in the first in which TV was extensively used, Diefenbaker delivered his populist message, evangelical sincerity, came across as genuine on TV
sound clips, abbreviated, nightly news, Diefenbaker speaking, anti-Liberal anti-establishment populist message, just the right length, message delivered but without logic behind it, more convincing than seeing him in person
new dynamic in the relationship between the parties and the press, turned journalists into media celebrities
DePoe become the first of the CBC celebrities, first who could compete intellectually with print media, well versed
rival between print and electronic media, more demanding press gallery, confrontation, pressure on print media to become more critical
also brought about Diefenbaker’s downfall, as time went on the image that he projected was increasingly negative, had a tremble in his hand, Parkinson’s speculation, a man in decay, became synonymous with the image of his government, both in decay, loses the support of the electronic and the print media, days numbered after that, loses the 63 election
symptomatic of “image politics”
Canadian parties turn to private polling and advertisements in the form of Kennedy
Pearson surrounded himself with younger generation media-savvy strategists, notably O’Hagan and Davey
Liberals hire Kennedy’s pollster, Harris, indicated that Pearson perceived as an academic smart-alleck, had a high-pitched voice, noticeable lisp
a bit of a dumbing down of political discourse, look for material about the candidate’s family for image
1965 federal election the last one not totally dominated by TV, but still 91% of households owned one, so Pearson spends a good deal of time in training, but he did not exude the charisma, increasingly the media was hostile to the Liberals and their attempts to mimic an American-style campaign, Pearson no Kennedy
this is the context in which Trudeaumania is possible
Politics as Spectacle: The Trudeau Era
style, showmanship
first PM able to manipulate the power of TV to his own advantage
path to power paved with iconic TV moments, e.g. the constitutional dual between Johnson and Trudeau and Trudeau standing up to demonstrators throwing rocks
shown being mobbed by crowds, adored by women, created by both the Liberals and the media, images
most of the media swept away by the image they were helping to create, “too good to be true”, sparkling, like a new car
in contrast to Stanfield, eating a banana and fumbling a football, Trudeau was kissed by women and slid down a banister and dressed like a pimp
TV demands something more exciting than a person behind a podium
Stanfield and Douglas may have been correct in their assessment of Trudeau: all image no substance, but they underestimated the power of the image, the TV audience saw a dynamic leader
Follow the Leader
Liberals began to select their leaders by convention in 1919; Conservatives in 1927
relatively pre-ordained, sure of results, a foregone conclusion, not a big media event
with the advent of TV, Libs and Cons begin holding larger conventions to bring the party’s grassroots into the process, power of mass movement, showcase the political parties and their policies
1967 convention that saw the ousting of Diefenbaker for Stanfield and the election of Trudeau on the fourth ballot
focus the voter’s attention on the leader, public persona, image, elections became contests between packaged party leaders, e.g. who won the debate
1968: first televised leader’s debate
Turner and Trudeau’s face-off, “I did not have a choice / “You had a choice, sir”
relationship between political parties and newspapers: the electronic media made this manipulation easier, communications strategists, advertising firms, pollsters, ads, catchy slogans, staged photo-ops, much more of a professional activity
TV offered the illusion of personal contact, but in fact less face-to-face contact, decline in the emphasis on policy positions
at the heart was the leader’s tour
emphasis on ability to capture the day
symbolic cues, language, visual images to convey messages subtly and less subtly, e.g. Harper at a hockey tournament, the leader you identify with
Maggie Trudeau campaigns alongside her husband, Trudeau is a gentle father
the only time local candidates received attention was when the leader visited the riding
the mass media may be inadvertently hastening the end of political parties
alerted the nature of political parties and the landscape of politics
mass media replaced mass mobilization
parties once relied on hierarchical system of inter-personal links (partisan campaign and organization to spread propaganda and collect political intelligence, grassroots the eyes and ears, as were the MPs)
with the advent of TV, professional polling, party elites can communicate directly and collect information without party organization or MPs, a bunch of nobodies
Democratizing the Parties
paradoxically, another outcome
extra parliamentary organizations that the Libs and Cons employed
if only to increase the appearance of legitimacy
e.g. televised leadership conventions
membership of the Con party hold accountable and review their leader (Diefenbaker)
contributed to the first electoral financial reform, previously minimum regulation, limited to a ban on individual candidates receiving direct donations from trade unions and corporations, parties themselves getting 90% of funding from these sources
combined with the high cost of media, controversial style of journalism, need for electoral expense reform
Election Expenses Act, 1974, to increase transparency and accountability, tight limits on election expenses, limit the potential influence of money, create greater opportunity for individuals to run for office, reduce corporate influence, get individuals to contribute, encourage individual participation, for the first time public funds used to finance political parties in addition to subsidizing part of the election costs, establishment of a tax credit to encourage people to donate, all this represented a shift, increasingly political parties were becoming less vibrant organizations, operating within the public sphere, increasing ties
Haunting Us Still? The Legacy of Trudeau Liberalism
Trudeau-era Liberalism, with its efforts to assert the power of the central government, assert Canadian independence, and contain the centrifugal forces (e.g. Quebec nationalism) that were leading toward greater regionalization, was consistent with the nationalist response to globalization’s impact on Canada – and as such, maybe seen as the last concerted attempt (to date) at a comprehensive pan-Canadian nationalism;
Trudeau’s electoral success almost came in spite of himself – his position as an outside to the Liberal Party, and his disdain for campaigning led to an often tense relationship between Trudeau and the Liberal Party establishment;
The Trudeau Liberal answer to the “national question” ultimately could not overcome the challenges to it from within and without, so that its main aspects ultimately went unfulfilled (or were undermined), and the Liberal Party was soundly repudiated in the 1984 election.
Background: ‘National’ Crisis and the Rise of Trudeau
The First Trudeau Mandate
Trudeau Liberalism after Trudeaumania
The Clark Interregnum and Trudeau’s Return
Haunting Us Still?
Quiet Revolution
Quiet Revolution
development of a new Canadian flag
Diefenbaker increasingly a liability and embarrassment to the PCs, trailing in the polls behind the NDP, nasty internal battle, replaced by the more Quebec-friendly Stanfield
Pearson Liberals took a more conciliatory approach, e.g. Commission on Bilingualism, attempts to enhance the francophone presence in government administration, pursuing a policy known as “co-operative federalism”
Trudeau made clear his opposition to according Quebec a special constitutional status, much less independence (negative half of the equation)
Trudeau also made demands on English Canada, he wanted to make Canada broad enough to accommodate francophone ambitions within and outside Quebec, imposes official bilingualism, the Bill of Rights (to protect minority and linguistic rights)
somehow there would be a sense of nation, all Canadians would hold in common certain rights, Liberal idea of nationalism, Canadians would not define themselves by race or religion but by shared rights
“just society” – reform liberalism, increased social and economic justice for all Canadians
the old Liberal establishment had been usurped
Trudeau’s idea of participatory democracy: vague, but idea that Liberal Party activists were going to have a more active and direct say in the goings on in governance
Trudeau seen as the ideal male to champion federalism, new man, new idea, to safeguard Canada’s future
Liberal Party reinvigorated, people had thought it would disappear, left-right struggle
Trudeaumania linked very closely to the crisis, helped to sweep them back to power, majority government, first time for the Liberals since 1953
Trudeau in Office
Official Languages Act, 1959, enacted bilingualism at the federal level, institutions more open to francophones, increase influence, more opportunities
dubbed “French power”
but at the same time, breaks with the more accommodating approach of Pearson and fights fiercely against any measure perceived as an attempt by Quebec nationalists to erode federal power
as for Constitutional reform, 1971 negotiation led to the Victoria Charter, looked like Canada was going to patriate its constitution from Britain with a limited entrenched Bill of Rights, but it falls through, Quebec premiere rejects it, Trudeau puts the Constitution on the backburner, did not want to open it up and deal with calls for more power from premieres
the promise of a “just society” is relatively unfulfilled
main task seems to be lowering the expectations of Canadians as to what should be expected from the welfare state, e.g. Canada pension plan, discussed in readings
by 1972, growing disillusionment, mixed record, not much delivered, the PM increasingly criticized for his arrogance
more broadly, concern about the centralization of power in the PMO, which is gaining influence over Cabinet
federal bureaucracy increases three times faster than the rate of population growth, government expanding, yet nothing much getting done
electorate increasingly of the view that Trudeau not really offering a fresh approach nor accomplishing much, social policy, fiscal policy, foreign policy, examined but hardly altered
Trudeau’s ability to alienate virtually every major group, e.g. War Measures Act infuriated Quebeckers, the West is furious over official bilingualism
this is the context for the next election
rough ride made even worse because the centralization of power came at the expense of the extraparliamentary wing of the party, Trudeau had neglected it as an organization, he assumed that everyone would come out at election time because they were Liberals, but volunteers stayed home, staff in the PMO vetos and overrules the Liberal Party brass, but they had little campaign experience, result was a disastrous campaign, Trudeau himself is a poor campaigner, sees it as beneath him
Trudeau Liberalism after Trudeaumania
Liberals have 109 seats, only two more than the PCs
nearly half of Quebec voters had voted Liberals, had half of Quebec’s 75 seats, needs English support, appoints John Turner (right-wing) as the Finance Minister to appease the business community, enters into alliance with the NDP because a lot of traditional Liberal voters had moved to the NDP, this alliance produces more progressive legislation in 18 months than in the previous 4 years, Trudeau also gets rid of the technocratic intellectuals and brings back professional politicians, the backroom boys, especially a group of Toronto Liberals charged with rebuilding the organization and teaching Trudeau how to be a politician
Liberals the underdogs in 1974, unlike the “intellectual conversation with Canadians” of 1972, he applies the lessons, he campaigns in a highly effective strategy, focuses on the trust that Canadians have in him as a leader as opposed to Stanfield (football-fumbler)
Liberals win 141 seats, majority, victory comes at the expense of the NDP who lose half their seats, won back their supporters, a second chance
in terms of the challenges of the day, inflation at 14% annually, rising unemployment, fiscal situation out of control, government not taking in enough money
Trudeau flip-flops on the issue of wage and price controls, imposes them in 1975, casualty is the Liberal Party’s credibility and John Turner’s, first in the series of high-profile departures
for the first time in 50 years (Depression), Liberal times are bad times, Liberals had secured a reputation as the party of good economic times and opportunities, social legislation, but things falling apart by the end of the 1970s, they could not cope with the challenges, at their lowest popularity since the Depression, matters furthered aggravated by the fact that the Liberals drifting from their reformist approach
Nov 1976 election of the PQ temporarily reversed falling fortunes, Trudeau able to assert himself again as the champion of national unity
plan to call an early election to capitalize on this
but Trudeau said no, his marriage had fallen apart, he did not have the energy or the stomach, lost opportunity
instead another attempt at Constitutional reform…that falls through
1979 the Liberals go to the polls, climate of rising crisis
Trudeau perceived as overly pre-occupied with the Constitution, not the solver of the problem, but the problem itself
The Clark Interregnum
PCs make the economic situation the primary campaign issue and win
Liberals take 67 of Quebec’s 75 seats but only win 114 seats across Canada
Trudeau leads the opposition
lacklustre effort, infrequent appearances in the House, Trudeau finally resigns, he had failed to realize Constitutional reform, his bilingualism policy was unpopular, the “just society” seemed more distant than ever, economy in ruins, Trudeau was a failure
the fact that the Liberals did not have a leader encourages the PCs to govern like they have a majority, 7 months in release budget, “short term pain to achieve long-term gain”, a 4-cents a litre tax on gas
Liberals emboldened, combine with the opposition, go into an election
a leadership campaign underway to replace Trudeau
Trudeau’s Reform
Clark government so unpopular that Trudeau the most electable leader again, Liberals ahead in the polls, after a week of suspense, Liberal Party establishment agrees that he will return as leader, a carefully managed campaign, Trudeau kept under wraps, didn’t want voters to remember why they had voted him out
Liberals win every seat but one in Quebec
a rare third chance
it is perhaps this last Trudeau government that is most prominent in historical memory, everything that it had promised to be
three months after election victory, makes crucial intervention in 1980 referendum, instrumental in defeating Levezque’s “Oui” side, promises that a vote for the no is not a vote for the status quo, promises that a vote for federalism is a vote for substantial constitutional reform
Trudeau engages in a bitter battle with the provinces for the patriation of the Constitution and the Charter, appears to have succeeded in realizing a national vision for Canada, redeem himself
but economic problems: onset of a serious recession in the 1980s, double-digit unemployment and interest rates
PCs dump Clark, replace him with Mulroney
Trudeau Liberals sinking in popularity, he announces his resignation, Liberal party members were wanting a more active role in the party, happy to see him go, especially as party fortunes declining, turn to John Turner, who re-enters politics, a symbolic break with the heritage of the Trudeau era
party gets a post-convention bounce but Turner makes the mistake of going to the polls quickly, not having established his own track record in office, the Turner Liberals painted with the Trudeau brush in voters’ minds, plus confirms Trudeau’s patronage appointments, a disastrous campaign, e.g. slaps women on the bottom and refuses to apologize, Liberals suffer greatest defeat in history, elect only 40 members (ten more than the NDP)
Mulroney Tories win 211 seats, greatest majority government in history
the verdict of an electorate exhausted by Canada’s existential crisis and the tough economic times, more broadly it draws attention to the legacy of the Trudeau Liberals: achievements made without Quebec signing the Constitution, this will come back to haunt Canadian politics, in a perverse way, measure that was supposed to strengthen unity in fact alienated Quebec
as for the “just society”, the 9-fold increase in spending racked up debt, successors undermined the welfare state that had been built up
record of the Trudeau Liberals is paradoxical, haunts us
The Rise of Neo-Conservatism: From Trudeau to Harper
Main Arguments:
GET THESE
The Origins of Neo-Conservatism
economic breakdown in the 1970s
Western economies faced to respond to something that economic theory had not predicted, rising prices at a time when the economy was staging and unemployment was high, Keynsian theory had these as mutually exclusive
buying power and savings reduced
in response, neo-conservatism preached a renewed faith in the classical laissez-faire system and the free market, e.g. Milton Friedman argued that the role of the state should be curtailed, return to a situation more akin to the system prior to the Depression, the state should only safeguard the currency, keep inflation low, proposes a monetarist policy that involves high interest rates, reduced government spending, privatization of state assets, deregulation of the private sector, rejects concern with full employment
provides a response for the political class that did not know how to respond to the crisis
corporate interests stood to benefit greatly from it
by the 1970s, breakdown of the reform coalitions, e.g. the New Deal in the US, disaffected Liberals turning towards right-wing parties, occurs in the UK, in Canada
neo-conservatives able to construct new coalitions with voters disenchanted with the political and economic consensus that had been working since 1940s
general right-wing shift to a position that shared more in common with classical liberalism
Conservative Party in UK led by Thatcher, Republican Party led by Reagan, both able to gain legitimacy among non-elite voters by constructing a new narrative about who the people’s enemies really were, a redefinition of social interests, corporate interests had been vilified, neo-conservatives saw enemies as those who supported the welfare state, proposed tax cuts, and the non-market distribution of social welfare
they successfully linked the malaise of the 1970s and the misguided attempts to engineer social and economic equality through the welfare state
Neo-Conservatism in the Trudeau Era
corporate profits skyrocket in the early 1970s, profits soar more quickly than wages, this provokes a series of labour disputes
forced with having to pay out so much in wages at a time when there seemed to be an economic downturn, major corporations began laying off workers
Trudeau government injects money into the economy in response, kick-start the economy, but rising unemployment and the increased money in the private and public sector makes inflation rise at the same time as rising unemployment, stagflation takes told
deteriorating situation prompts the Liberals to adopt neo-conservative measures, e.g. Turner’s appointment as Finance Minister reduced corporate taxes, denied government the money to fund the welfare state, put an end to rising expectations
early 1978: Canadian dollar lost 15% of its value against the US dollar, unemployment up, double-digit inflation, deficit approaching a record level
Trudeau returns from the G7 conference in July 1978, during this conference he had discussed the need for left-wing governments to be more fiscally responsible, introduces a mini-budget that cuts spending
what was billed as a bold program to turn around the economy was largely cosmetic, symbolic, ultimately alienated the left in Canada, fighting the situation on the backs of the poor, the more right-wingers not impressed by the failings
after Trudeau’s return in power in 1980, government had a change of heart, bucking the neo-conservative trend, tried to reduce the US presence in Canada’s economy, combined with the recession of the 1980s, ever-increasing deficits, debt
growing momentum of compound interests
Progressive Conservatives and Neo-Conservatism (or Red v. Blue Tories)
in the context of high unemployment, double-digit inflation rates, voters turned away, embraced the neo-conservative agenda, in an era of accelerating globalization, the Liberal nationalist appeal no longer evoked the same kind of response, shift in public opinion
explains why Turner elected after Trudeau, more of a blue grit
like their Conservative counterparts throughout the West after WWII, Tories had difficult coming to terms with the reform liberal consensus, red Tories, by no means anti-capitalists, were supportive of the free market, but more willing to accept an activist interventionist state to preserve social order and strengthen community
Stanfield was the classic red Tory, argued that any civilized society was concerned with the well-being of the less fortunate
Clark argued that the modern world needed both an active government and strong communities, however he was more willing to champion the market liberal position, more right-wing than Stanfield, called for the privatization of Petro Canada in the 1979 election, budget inspired by N-C economic theory, balancing the books the goal, opposed to nationalist interventionism of the Trudeau Liberal
Red Tories increasingly under siege in their party, election of Mulroney a sign of ascending neo-conservatism in the party and an increased openness of the voters to the agenda
Michael Wilson, finance minister: deficit reduction, privatization, deregulation, get the government out, let the market operate as freely as possible
Mulroney: “Canada is open for business again”
limits to the N-C trend: Mulroney Tories did not go as far as Britain or America, part of this the fragility of the coalition that had brought them to power, Quebec not as N-C, result was the cuts to social programs were nowhere near the levels encouraged by some lobby groups and think tanks
high interest policy meant the cost of servicing the national debt increased, what ends up happening is the structure of government spending begins to change, the money being spent had more to do with servicing the debt than with maintaining the welfare state, programs decline significantly
tax reform in the second mandate, reduced the progressive nature of income taxes, implement the GST, both of these tending to benefit the upper-income strata at the expense of the lower-income strata
free trade most significant
MacDonald Commission: because of the failure of the attempt to diversify trade and increase ties, Canada’s economic prospects revisited, 1985 report to the Mulroney government argues that Canada should pursue a comprehensive free-trade agreement with the US, trend towards continentalism, Tories embraced it, agreement reached in January 1988
the election that year incredibly emotional, Liberals opposed it, championed the Canadian nationalist cause, argued that free trade would led to the dissemination of the east-west economy and the very basis of Canadian sovereignty
they won the battle but they lost the war, Liberal and NDPs won 52% of the vote, but Tories win another majority with 43% of the popular vote, free trade enacted
passage of the FTA created an impotence for pursuing the neo-conservative agenda, greater concern about ensuring Canada’s economic competitiveness, Conservatives terminated mother’s allowances, the universality of old-age security, the amount of money transferred to the provinces for social spending is capped, by 1989 corporate taxes only 9% of government’s revenues
Impact at the Provincial Level
Alberta
PCs in power since 1971 under Peter Lougheed until 1985
ran activist governments, interventionist, in support of the AB business community, undertaken to diversity the resource-based economy, facilitate economic development
AB Tories preside over the collapse of several firms that had received significant government support, suggestion of corruption, fuels an anti-government feeling in AB, leads to calls for the AB government to remove itself from economic affairs
reinforced by the late 1980s deterioration of AB’s finances
a gradualist approach taken, hope that the government will ride it out, but cannot, amid tax increases and growing debts, cuts to public services, Gerry resigns, succeeded by Ralph Klein
Klein distanced himself from his predecessor, more avowedly conservative, argued AB weight down by an oppressive public sector, did not jive with the global economy
low taxes would attract businesses to AB, apparent success of Klein, balances books within three years, contribute rise in ON
Ontario
NDP won a majority under Rae just as a recession began, initially they bucked the N-C trend, first budget by Floyd Loughren provided no spending cuts, argued that the recession would not be fought on the backs of the poor
however, the economy did not turn around quickly and so the Rae government’s room for manover was immediately and severely restrained, as the recession deepened, switches to a deficit-reduction policy, consistent with N-C principles
e.g. new labour code, introduces the social contract, meant to reign in government spending, imposed salary cuts on civil servants, forced them to take up to 12 unpaid days of leave per year, Rae Days, public sector balks
the NDP’s alienation of its main support wing paved the way for Mike Harris
the PCs were a centrist party, they were in the red Tory tradition, but Harris shifts it right in the example of Ralph Klein, campaigned on a N-C platform, “Common Sense Revolution”
cut income taxes by 30% over three years, to pay for this closed hospitals, cut education spending, shitfed welfare spending to local governments, repealed labour laws
The Federal Level: From Blue Grits, to Reform, to the Conservative Party
Liberals sign a FTA with Chile, make progress on the unrealized FT with the Americas
inclined Canadians more to the view that Canada needed to be more business-friendly, less distributive, more dramatic spending cuts as Martin promised to eliminate the deficit, accomplished by the late 1990s
political factor that contributed was the rise of the Reform Party, in its short lifetime managed to win only one seat east of Manitoba and the majority of its seats in two metro areas, had a huge impact, reduction of the welfare state a reform policy before taken up by the Liberals
without achieving federal power, it contributed to its retrenchment in the 1990s
Reform: tougher line on law and order, government spending, welfare state, argued for emphasis on individual rights as opposed to group or collective rates, called for an end of government support for multiculturalism, pay equity programs, and bilingualism
also increasingly reflected a social conservative view, opposed gay rights
“Fresh Start for Canadians”: traditional family values, tougher law and order
attempts to unite the right in the late 1990s, it appeared increasingly that Reform would have to moderate its N-C image, what remained of the PCs after the 1993 election had appeared marginalized for once and for all its red Tory elements
under Jean Charest, a much more emphatically N-C agenda, growing under Mulroney, but reached new heights under Charest, except for certain social issues and the Quebec issue, they were the mirror image of the Reform Party
Joe Clark returned as PC leader, tries to return party to its more traditional roots, spurned the overtures from the Reform Party and the Alliance, too ideologically right of centre, however this apparent revival of red Toryism was fleeting, under pressure to co-operate
eventually Clark forced to come to terms that he was out of touch with the party he was leading, resigned leadership in 2003, succeeded by MacKay in 2003, merger, the Conservative Party of Canada
represented a victory of the N-C position…until this week’s budget
Trudeau Article
legacies of Trudeau in English and French Canada
credit and blame to a single politician, the role of the media
Neo-Conservativism Article
response to globalization
marrying of social and fiscal conservatism
are they not mutually exclusive?
Harper’s budget suggests that either you must make sacrifices in a minority government OR the resurgence in Canada is minimal and we will always value social programs
who benefits from globalization?
reform liberal consensus at the end of the Depression…now political parties championing shades of neo-conservativism…survival instinct (pragmatism)
The Quebec Question and the Canadian Crisis
Main Arguments
Quebec party politics from the 1970s onward was polarized over the “national question” regarding Quebec’s political future;
The “beau risqué” attempt to achieve an enduring constitutional settlement in the 1980s failed, resulting in the resurgence of the Quebec separatist movement, and the appearance of new political parties, the most significant being the Bloc Quebecois and Action Democratique de Quebec.
Outline:
November 16, 1976: The Road to PQ Victory
The Not so Beautiful Result of the ‘Beau Risque’
The Quebec Question and the Canadian Crisis: Party Politics, 1990-5
The Road to PQ Victory
Liberals launched large-scale public works problems including superhighways and the James Bay hydroelectric project and the facilities for the 1976 Olympics
also some nods from Bourassa to social democracy, e.g. medicare
but rapid and intense struggles with labour, notably the strike in 1972, following the incarceration of three leaders more labour unrest, social agitation
as the October Crisis demonstrated, the question of Quebec’s political future could not be avoided
Bourassa Liberals determined to defend their own and Quebec’s autonomy from the Trudeau Liberals, refused to abandon the nationalist field to the PQ, positioned themselves as defenders of Quebec’s constitutional powers and its cultural sovereignty within Canada, e.g. rejected the 1971 Constitutional Charter and infringement on its culture
the UN leader Bertrand replaced by Loubier who tried to revive UN fortunes, changed name to Unite Quebec, brought in a new slate of candidates, but failed to get any elected, squeezed between the Liberals and the PQ, UQ did not have a clear reason for existence, lost supporters to one or the other
PQ trying to achieve greater success, translate popular support to seats in the National Assembly, after 1970 emphasized its social reform and social democratic aspirations over sovereignty, Bourgault said that PQ was to be the liberation front (cultural, political), a population to undergo national liberation, but also had Levesque who was less radical, growing pains, internal tension
Leveque has to separate PQ from the violent labour movements in order to see success, in 1973 brings in 33% of the vote, a significant political force, the Official Opposition, although actually down from 7 to 6 seats because of the first-past-the-post system
Bourassa Liberals benefited, won 102/110 seats in the NA, with such a massive majority they could only go down, they staggered from crisis to crisis, did not respond effectively to the labour movement, did not control spending on James Bay and the Olympics, growing charges of patronage, Bourassa “the most hated man in Quebec”
one of the most contentious issues: Bill 22 making French an official language of Quebec, this united Quebec against the Bourassa Liberals, the anglo- and allo- phones were opposed to restricted English school access and the required French proficiency in professions, but Quebec nationalists thought the law did not go far enough
Bourassa called an election just 3 years into the mandate, 1976, figured the situation was bad but could only get worse, the campaign was a Liberal disaster, had to contend with a resurgent UQ (back to UN), the UN benefited from the opposition to Bill 22 and split the federalist vote to their benefit, just what the PQ needed to overcome its internal divisions, PQ promised to hold a referendum before any action was taken, that was a victory for the pragmatic wing, permitted those Quebec voters who were not necessarily in favour of sovereignty-association to nevertheless vote PQ, “etapiste” approach, step-by-step, promise to stand up to the Liberals, expand social services
the results come in, PQ majority, to Levesque’s surprise, 71 seats and 41% of the vote
one of the PQ’s most important bills was 101 that made French the sole official language, no opportunity for English to be used
The Not so Beautiful Result
had to contend with a re-invigorated Liberal party under Claude Ryan, but not especially effective in mounting an opposition to the PQ’s referendum in 1978 (?)
at the federal level, Trudeau Liberals had fallen from party, Clark in a minority position, but falls in 1979, ironically, he comes back to power and the referendum fails
the unilateral actions by Trudeau contributed to the PQ being re-elected in 1980
PQ came close to launching a federal wing but wary of a Quebec nationalist party participating in the federal arena, would suggest compliance, not what Levesque wanted to do, knew how nationalist blocs had fared in federal parliament, did not want a repeat, so PQ members were advised to either vote for the Creditists or abstain from voting, one of the reasons why Trudeau swept Quebec in the 1970s, the opposition stayed home
PQ registers itself as a federal party in Sept 1982, Levesque this time supports it, but highly contested among some elements, and reverses it soon after
new leader of the PCs changes the notion that Quebec is a political wasteland for the Tories, Mulroney’s arrival changed the PQ equation regarding the federal level
PQ government increasingly unpopular, leadership reverses its decision to run federal candidates, instead the pragmatic Levesque took “the beautiful risk” of support Mulroney
PQ was respond to Mulroney’s promise to rectify the bad Constitutional deal and his promise to amend it in a matter that would satisfy its aspirations and sign it with “honour and enthusiasm”
result in 1984 was a historic shift in Quebec voting patterns, the Mulroney Tories won 58 of Quebec’s 75 seats, from 13 to 50% of the popular vote, not just the death of a regime but the first of a new pan-Canadian coalition, seen in the Diefenbaker Tories and Macdonald
hastened the demise of the PQ government, serious labour unrest, government had forced civil servants back to work with pay cuts, alienated, forgot its social-democratic roots, as well the “Risk” strategy involved more than supporting Mulroney, it involved the decision to shelve article one of the PQ program, which was referendum, this dropped the question, starved out the more doctrinaire elements of the party, e.g. Parizeau and Laurin
notwithstanding the decision not to run a federal wing, the Parti Nationaliste formed, performs abysmally in 1984 and disappears by 1988
Levesque resigns in 1985, succeeded by Johnson (conservative nationalist), the PQ fell to 23 seats nonetheless
The Canadian Crisis
set the stage for constitutional reconciliation, May 1986 Quebec Liberals listed their conditions for formally signing on, Meech Lake Accord 1987, appeared possibly to offer Canada Constitutional peace, impact more important than details
1988 federal election unfolded with the belief that Meech was a done deal, permitted the Tories to increase their seat count, 63 seats, best showing ever of the Tories in Quebec, solidified their electoral coalition, but then a renewed dispute over Quebec’s language laws when Bourassa uses the Notwithstanding Clause after the Supreme Court rules some parts of 101 unconstitutional
Equality Party calls for official equality of French and English, just a flash
language controversy touched off the unravelling of Meech, absolute melodrama, return of Trudeau decrying the deal, deepening unity crisis, Manitoba and Newfoundland fail to ratify it and it dies, number of effects:
the NDP moves to expel its Quebec section from the party when it moves to endorse Quebec separation
for the federal Liberals, Meech was disruptive, Turner had supported it when announced, after Trudeau intervention he switches, but switches back and says he will support it with some changes, resigns in 1989, leadership convention unfolded, Chretien elected leader the day that Meech died, had served as Minister of Justice, very much a part of the struggle, initially Chretien was critical but he warmed up to Meech, his election led to two Quebec MPs leaving the party on account of his harsh approach to Quebec’s nationalist aspirations, these MPs left for the Bloc
the disintegration of the alliance was a result of the Bloc, Bouchard had been a close friend and supporter of Mulroney, but Quebec Tories left the party after Meech failed, they formed the PQ, July 1990, nationalists opting for a nationalist party, Bouchard emerges as leader, charisma, closer to the traditional nationalist elements in Quebec, call for greater devolution of powers to the parties
Bouchard elected to the Belanger-Campeau Commission to buy time, his participation afforded him further public exposure, sounding out the population on Quebec’s future, sovereignty running at an all-time high, the Meech failure and the rise of the BQ put pressure on Constitutional reconciliation
the Charlottetown Accord, 1992, more ambitious, to settle all Canadians’ constitutional demands, endorsed by Cons, Libs, and NDP, also had the support of the Quebec Liberals, submitted to a nationwide referendum, but rejected in certain regions, fell short of meeting Quebec’s demands
Bourassa Liberals had also shelved a more autonomist approach being promoted by Jean Allaire, Allaire walks out, takes with him Mario Dumont (leader of the YLCQ), together they form the ADQ, Dumont takes over at age 23
1993 election, BQ won nearly 50% of the popular vote, called into question the pan-Canadian claims of the federal Liberals (19 seats) and the PCs (1 seat, Charest)
a year later, the PQ return to power in Quebec, takes 77 seats to the 47 of the Liberals
1995 referendum produced a virtual tie, 94% voter turnout, federalist won by less than 55 000 votes
the national question goes into overtime…
The West Wants In
Main Arguments:
The Reform Party’s emergence in the late 1980s is consistent with a larger history of Western alienation that reflects an enduring suspicion of external control, a rejection of the status quo of Canada’s parliamentary system, and a thirst for a fundamental solution to redress the power imbalance between Central and Western Canada;
The emergence of the Reform Party in the late 1980s arose from the failure of the two traditional parties to sufficiently respond to the specific concerns of Western Canada;
The history of the Reform Party (and indeed its successors, the Canadian Alliance and the Conservative Party) reflects a tension between being a Western regional party, and the realities of obtaining the power to implement those measures meant to address Western concerns.
Western Alienation and Canadian Political Parties, Post 1945 to the 1970s
The Liberals and the West, or, “Let the Eastern Bastards Freeze in the Dark”
The PCs and the West
From Reform to the Conservative Party of Canada: Is the West In?
Western Alienation
Manning dropped the “social credit” dimension of the party and it became a rural-based conservative party
absolutely dominanted Alberta politics until the 1970s
concerned with the leftward drift at the federal level in the 1960s, Manning’s So-Creds took note
Social Credit Party won power in BC under Bennett, “Wacky Bennett”, he did not believe in social credit theory but used it to form a very conservative coalition to stave off the rise of the NDP
like its Alberta counterpart, the BC So-Creds asserted the provincial interest in its dealings with Ottawa, engaged in province-building, expansion of BC’s economic infrastructure
at the federal level, the national Social Credit party captured most of AB’s and some of BC’s seats, first under Blackmore, then under Low
it appeared at that point that Social Credit had what it took to become a major federal party, centred out of the West, championing Western interests, arguing that MPs being marginalized, excessive concentration of power in cabinet, party discipline
Diefenbaker election in 1957 changes everything, up until this point the PCs had been confined to the anglo-Ontarian business community, able to successfully harness discontent, he gave PCs a major Western rural base that he was able to combine with the central Canadian party
Diefenbaker’s success came at the expense of the So-Creds, lost all its federal seats
in its wake Manning recruited Thompson to take over leadership of the party, difficult task of reviving it at the federal level, had some success in 1962, wins seats
however 26 of the 30 came from Quebec, the Creditistes, only four were Western seats, questioned identity as a Western party
Quebec wing and Western wing had a fallout, rise of two distinct regional movements at this time, strengthening Quebec nationalism vs. growing Western nationalism, an irreparable split
Social Credit never recovers at the federal level, Thompson resigns in 1967, leaderless, the following year they were seatless
Prairie provinces had obtained control of their resources, royalty cheques come in, Manitoba gains from mining, hyrdo-electric and forestry; Alberta gains from oil; Sask from uranium and potash
in Alberta’s case, the political figure most identified with the economic rise was Peter Lougheed, enters politics in 1962 as a PC, goes on to lead the Alberta Tories, able to enunciate an effective criticism of Soc-Cred that remained safely right of centre, argued that AB far too dependent on oil and gas and agriculture, concern at the time was oil running out, he criticized Manning’s So-Creds for failing to recognize oil’s potential for massive economic development, manufacturing sector, could rival central Canada, establish itself
by 1970s, majority of Albertans living in the cities, Pratt/Richards have interpreted the Lougheed Tories as the manifestation of a new rise of businesspeople in AB
parallels between QC and AB: using the state to further the social and economic interests of the middle class, moreover AB’s Quiet Revolution began in 1971 when the Tories win 2/3rd of the seats, still there now
growing expertise in bureaucracy, expansion, part of the challenge to Central Canada
beginning to draw in rural Albertans as well, Lougheed argues he needs a strong mandate from Albertans in order to challenge Ottawa, an uncaring domineering federal government led by Trudeau
The Liberals and the West
Liberal Party in decline throughout the St-Laurent era in the West
culminated with the Diefenbaker election with the Libs did not win a seat west of ON
Liberals centered chiefly out of Central’s cities
the most longstanding and significant dispute arose out of the question of oil, an oil crisis erupts in the 1970s, gas prices skyrocketing, Trudeau’s Liberals wanted to use AB’s oil to provide a steady supply and price to Canada by expanding the pipelines eastward to Central Canada, new incentives to explore the development and discovery of oil, establishment of Petro Canada
“Pierre E. Trudeau Rips Off Canada”
just another example of CC arrogance, the forced sale of AB’s non-renewable resources at prices well below the global market prices, AB government doubles its royalty rate to make up for the fact that Ottawa keeping the resource at a lower price, increased tax helped to get the money back
Heritage Trust Fund: 1/3rd of all of AB’s oil resource funds to fund development, diversification, long-term way by which AB could achieve greater economic power within Canada
recently used this to pay off its provincial debt
Liberals induced Jack Horner, a Tory backbencher, to cross the floor, parachuted into the cabinet, a desperate attempt to establish a toe-hole in AB, but it was self-defeating, Horner loses the 1979 election, crass political opportunism, only win 3/77 Western seats
1980 Trudeau denounces “the Clark government’s rather cowardly, soft approach to dealing with the West” and argues that the Libs would provide cheaper gasoline (to CC), i.e. would continue the 1973 policy, popular in CC, unpopular in WC, and fall to 2 seats (and even those were in Manitoba)
notwithstanding, Trudeau’s win a majority government (ON and QC), increases the sense of Western Canada, voting en bloc, still faced with a majority Liberal government, the system is not responding to the West, it is a tool of CC
Oct 1980: after oil prices again spike, Libs move unilaterally in enacting the NEP (National Energy Policy) meant to achieve self-sufficiency in Canadian petroleum, grants to encourage oil drilling in the Arctic, new taxes, expansion of Petro Canada, Western oil maintained at a price far below international prices
this does reduce dependency, foreign influence, but it strengthens Western alientaiton, stifles foreign investment in AB, especially when in 1982 oil prices begin to collapse, the moment when the NEP is coming into its own, AB’s best opportunity for economic development had passed, they had missed the boat
more broadly, NEP viewed by the West as an attempt to take control of provincial resources, the product of a political system designed to serve CS and marginalize WS
The PCs
Mulroney’s victory seemed to vindicate the strategy of working with one of the established parties
West seemed to have gained influence in Ottawa, held key cabinet positions, the NEP repealed
but the vindication of this co-operation strategy was short-lived, West had high expectations, Mulroney did not deliver
new protest movement
the fighter jet contract, Bristol Aerospace of Winnipeg lost despite being cheaper and superior to a Montreal company, CC interests trump WC interests, the CF18 scandal
Reform
roots in Western Canadian business elite
talk in Calgary and Edmonton of the need for a new party, especially among business executives, upset that the Mulroney government had not moved fast enough to repeal the oil and gas tax
attracted to Ernest Manning’s son Preston, who argued that the time was right to launch a new protest party
Van, Cal, Ed host the Western Assembly on Canada’s Economic and Political Future which lays the groundwork for a new protest party
Reform Party: “The West Wants In!” 1987
in addition to its neo-conservative policies and its populist tendencies it proposed a Triple E (equal, effective, elected) Senate, all of these aimed to reduce the power of the PM and lessen CC’s political influence, more ambitiously, to rebalance the division of power in the federation
no Reform candidates elected in 1988, but that had more to do with the strong support for Free Trade, to prevent Ottawa from imposing a new National Energy Program
in the wake of 88, Western alienation grew, along with the popularity of the Reform Party, it wins a bi-election and a Senate election in AB (Senator Stan the People’s Man)
GST enacted, first sales tax in AB, fury
Reform opposed Meech, an elite-driven CC process, called for equality between the provinces, no special status, gave the Reform a national pulpit, support increased when it opposed Charlottetown, going to result in a constitution that enshired CC domination
the Alberta Tories led by Getty
Kim Campbell elected Tory leader, part of growing concern to their declining popularity in the West, but too little too late
52/87 seats go Reform in 1993, Manning hoped that Reform would become national anchored out of the West, internal party referendum endorsed idea of running national, changed its slogan, but still its fundamental aim
influenced Liberal Party, Chrétien shifted rightward
but Eastern voters were alienated, perceived it as a Western party, extremist, only one seat elected east of Manitoba (Barrie!)
1997 election: Reform won 1/5th of Ontario votes, widespread, this support did not translate into any seats; but won 8 more seats in the West and became the Official Opposition
trend was to see it as a Western party
Manning initiated the “United Alternative Movement” to unite the right, another bid of the West to obtain power, the attempt to break free of the Western confines of the Reform Party, downplay the exclusively Western agenda stigma
e.g. dropped demands for a Triple-E Senate and requested an elected Senate; toned down the references to Western alienation, on the backburner
¼ of the Reform Party caucus opposed the UAM for fear that Western interests would become submerged like in all national parties and the West would not be “in”
a majority of the Western delegates to the UA Convention in 1999 endorsed and founded the party actually opposed the new party, but Ontario delegates swung it, result was the Alliance
most visible sign that the Canadian Alliance was moving away from the Western alienation stance was that Manning lost the leadership, he was identified with the idea, not popular amongst the corporate Canadian elite in central Canadian, felt uneasy about him, Alliance elected someone who was (initially) much more popular in the centre – Stockwell Day
2000 election: Alliance gets 4.5% more of the popular vote more than the Reform ever had, and 66 seats
still a Western party in practice: only won 2 seats east of Manitoba, these were in Ontario
most of the committed party activists were Western Canadians
only with the 2003 merge with the PCs, the election of Stephen Harper (transplanted from ON to AB) that the West was able to bring itself to the Government side of the House
return to the Lougheed strategy, the idea that the West would see its interests realized and defended by participating in a pan-Canadian party as opposed to a regional protest party
since the 2006 election, AB has been hard-hit: the phasing out of capital cost allowance, the inclusion of resource revenues in the equalization process, etc.
people have begun talking about a new Western regional protest party, West remains out
the combined population of AB, BC now has surpassed that of QC, the rate of population growth (fuelled by the tar sands) is outpacing that of growth in the rest of Canada, growing economic clout, Canada’s political and economic centre of gravity may be gravitating Westward to Calgary and Edmonton
suggests that the West is going to have more seats in the House, the West in the future may go with the protest party or the pan-Canadian party, but it is going to be “in”, seeing its agenda realized
One Party Rule or Perpetual Instability?
Main Arguments:
The 1993 federal election constituted a political earthquake in Canadian party politics. The effects of globalization, combined with Canada’s cleavages, resulted in a regionalization and breakdown of the mid-20th century party system;
The federal politics of the 1990s were an exaggerated version of earlier examples in which Ontario political forces fought off challenges from Quebec and/or the West;
The regionalization of Canadian party politics and decline of pan-Canadian parties led initially to a situation in which one party was dominant, but since 2004 has resulted in a situation of perpetual instability in the form of minority governments.
1993: Political Earthquake
Overtime: The Quebec Question and Party Politics
Uniting the Right
Decline of the Liberals?
Political Earthquake
a breakdown, a watershed, reflecting Canada’s internal divisions, each region relating to national politics in its own way, a five-way split
set the pattern for Canadian politics to the millennium
1992: Charlottetown Accord rejected despite being endorsed by the three main parties, a victory for the Bloc and Reform
Canadian electorate angry and cynical in 1993
unpopular NDP governments in ON, SK, saw its national seat count drop, and lost their claims to Official Party Status, yet not the biggest losers
Tories ruling coalition had collapsed, rise of Reform and Bloc reflect this
massive recession, global in scope, had hit the manufacturing sector in ON especially hard
by the time Mulroney resigned, the PCs had an approval rating in the low teens
Campbell’s replacement was to remove the stigma, the thought that they would be able to hang onto power, Tories build on the image of Campbell, don’t try to run on their record or a new platform, focus on the party leader as the result of politics in the television age, but Campbell turned out to have a rather disastrous campaign, the first day she was a little too honest and said that really, Canadians were going to have to make do with high unemployment until the end of the century, and said that the campaign was not the time to discuss social security reform, and the TV ads of Chrétien’s lip paralysis were very unpopular, reduced to two seats, caucus able to meet in a phone booth
Reform and Bloc were big winners, had harnessed the regional anger of their areas
Bloc had only run candidates in Quebec and yet won the second largest number of seats, forced to serve as the Official Opposition
Liberals were the biggest winners, after a decade in the political wilderness, after the 1984 defeat there had been an internal battle between Turner and Chrétien, in 1986 the Chrétien camp spearheaded an effort to oust Turner, unsuccessful
Turner redeemed himself somewhat in 1988, from 40 to 83 seats, but this achievement was deceptive, still the second-lowest result after the very lowest result in 1984, seals Turner’s fate, he had lost Quebec, failed to restore Liberal fortunes in the West, his anti-Free Trade stance had alienated corporate Canada from the party, further divisions between the left and right within the party, demoralized party, Chrétien wins the leadership in 1990
Chrétien is spooked by the Constitutional crisis, not very effective in responding to the Oca Crisis, did not have a coherent stance on the Gulf Crisis in 1990-1, shaky years, but he does succeed in reorganizing the party
a policy conference, thinker’s conference, 1991, Aylmer Conference, new platform for the Liberals, later showcased in the Red Book, moves the Liberals a fraction to the right of the centre, embraced globalization, argued that an activist government was still necessary, but ultimately reject the welfare statism and economic nationalism
1993: get seats in every region of the country, but due less to the platform, leadership, more to the fact that their opponents were weak, division of the right, permitted the Liberals to come up through the middle, Liberals had a majority, confident that their opponents had been dealt crippling blows, confident that the regional parties would not make bids for office, set for a long run in power
bulk of Bloc’s attention went to Quebec’s interests, Reform party in growing pains, a power struggle within between Manning and rising star Harper who leaves in 1997 to head up the National Citizen’s Coalition, a special interest group
Overtime
1995 Quebec Referendum
sense of crisis over Canada’s future
McKay’s article deals with the kind of literature being produced at the time, sense of pessimism, look at the footnotes, scathing
disarray in the ranks of the Quebec nationalist movement, Parizeau blaming the defeat of the “yes” side on the ethnic vote and lack of money, resigns PQ leadership, sets up a game of political musical chairs
Bouchard to take over leadership of the PQ (from Ottawa to Quebec City), charismatic, he was brought in to take over leadership of the “yes” campaign, principal spokesperson, took over even before Parizeau resigned
prompts the Quebec Liberals to draft Jean Charest, star federalist campaigner, from Ottawa Tories to replace Daniel Johnson in Quebec City
1998: Charest Liberals won the greatest share of the popular vote, but trailed the PQ considerably in terms of seats, Libs had 48 while PQ had 76, popular vote count reflected that Quebec was seriously divided over the question of its future and the ADQ double its share of the popular vote
in Ottawa, Bouchard’s departure seemed to indicate a decline in Bloc fortunes, Gauthier succeeds him, followed a year later by Duceppe, who wins the leadership after a very acrimonious convention, divided by left and right wings, contributed to the impression that Duceppe was a weak leader without a hold on his party
declining popularity of the Bouchard government, neo-conservative, affects the Bloc
encourages the Chrétien government to call an early election, make gains in Quebec, only 3 ½ years into its mandate, Liberals pick up 7 seats, the PCs had the best relative gains moving from 1 to 5
Uniting the Right
another factor in the early election was the fact that the right was till divided, the Manning father/son had proposed a merger between the right-wingers, the So-Creds, and blue Liberals, a re-alignment, written in 1967
took a long time to be realized: PCs not willing to give up the ghost, anointed Charest as their leader, wanted to revive party fortunes, whipped out party debt, they were much better at tapping into corporate Canada resources than the Reform, but awkwardly ideological, between the Reform and Liberals, did not have a distinctive support base, no electoral machine to deliver support (had collapsed in the 1993 campaign)
1997: Tories regain official party status, however they continue to trail Reform in popular support, PC support too thinly distributed, a few pockets of PCs in each constituency
Tories obliterated in Western Canada, barely holding on in Central Canada, most support in Atlantic Canada
Reform a party of the West
both parties take about 20% of the popular vote, allows Liberals to come up the middle, sweep ON in 1997, conditions for perpetual dominance
to form a moderate right of centre party
Manning has party endorse its own demise in early 1999, UA Convention, idea endorsed, in 2000, new party officially founded with the name Canadian Conservative Reform Alliance(Party) CRAP, becomes the Canadian Alliance
although Reform joined the Alliance, Clark’s Tories refused, ran a full slate of candidates
enabled Liberals a third majority
Day’s disastrous leadership, members leave, form new party with a loose coalition with the Tories
looks like the Tories will unite the right, pick up the pieces
2001 Convention: Harper elected leader, this changes the political equation, he revives Alliance fortunes, Democratic Representatives rejoin party, Clark resigns in 2003, succeeded by McKay
McKay had, in the course of the spring 2003 convention, promised that he would not pursue a merger, in the fall he reversed his decision and the merger happened by the end of 2003
March 2004: Harper elected leader of the CP
emergence of the CP as the pan-Canada party
Decline of the Liberals?
Liberals have been in decline in the West since the St-Laurent period, especially following the Diefenbaker victories, in the subsequent Trudeau years the Conservatives were getting a relative majority outside of Quebec in the 1970s and 80s, support for the Liberals in Quebec began to disintegrate after the 1982 Constitution, the rise of the Bloc, Liberals unable to recover, in 1988, Liberals lost seats and their share of the popular vote in Quebec, more than half of its caucus coming from ON, in 1993 Liberals won only 18 seats in QC, Chretien forms a majority government without a majority of Quebec seats, 55% of the caucus from ON, having won 101 of 103 seats, in 1997 the regional decline is confirmed, although they had seats in all provinces except NS, only had a majority in NF, PEI, and ON, an Ontario party
revived a bit in 2000 election, but deceiving results, swept because of divided right
won 36 seats in Quebec, just a couple shy of the Bloc, and they outpolled the Bloc by 5% in the popular vote for the first time
appeared to vindicate the harder line the Chretien Liberals were taking after the 1995 referendum, were pushed by the Reform Party, which advocated a more assertive approach towards Quebec
a reference to the Supreme Court regarding the potential succession of Quebec, what law would rule, what would be the procedure, culminated in the 2000 Clarity Act sponsored by Dion, stated that Ottawa would not negotiate separation unless the referendum question was clear and had received a clear majority
speculation that the Clarity Act would wipe out Liberal support in Quebec, but by 2000, already problems within the party, namely the Sponsorship Scandal, Gomery revealed that Liberal strategy was designed to annihilate the Conservatives and unite federalists under the Liberal banner, make the Liberals synonymous with Canada
a blurring of the lines between what constituted a national interest and what constituted a Liberal interest, increasingly perceived as one and the same within the party and the bureaucracy
when the Sponsorship Scandal blew up, it was a divide between Chretien and Martin
Martin supporters increasingly annoyed by Chretien’s dominance, three elections, after the third majority the Martin Liberals began to act, moved to take over the Liberal party from the grassroots up, quite successful, by 2002 a power struggle in the open, Martin fired/resigned from Minister of Finance
Chretien feels the party being taken over, announces resignation
despite being initially seen as a break from the past, Auditor General releases report on the Sponsorship Scandal, Martin’s Liberals seize the opportunity to bury Chretien with it, but voters don’t distinguish, the same party regardless of leadership
in 2004 election, reduced to a minority government against the newly united right
in 2006, Conservatives come to office
a revival of the Bloc’s fortunes in the wake of “dirty politics” in referendum and AdScam, support rises back to Bloc’s 1993 levels, win 54 seats in 2004, but down a bit in 2006, result is parliamentary instability
no one party has been capable of achieving a majority, as in the 1960s
remains to be seen if Conservatives can win a majority or whether the regionalized politics and the instability of minority governments will continue
Voter Alienation and Alternatives to Parties
Declining voter participation
Question of government legitimacy arises
Reaction is adaptation to voter alienation
Despite some predictions to the contrary, the death of Canadian political parties has been greatly exaggerated
Growth of Cynicism
e.g. failure of Charlottetown
understood as a rejection by voters of the elite-dominated political brokerage politics
the alienation manifested in two huge specs: the decline in the number of Canadians turning out to vote (highest in Diefenbaker era, rate has been on a downward trend since, from 75% to 70% in 1993 to 60% in 2004 and the accentuation of voter volatility, seen in Mulroney’s landslide and the Chretien landslide, breakdown of party loyalties
reflected in the growing number of new parties
has created a vicious cycle, increased prominence of short-term policy making, parties have to capture disloyal voters
has led to scapegoating, criticizing, attacking opponents
has only further fuelled alienation
the changing electorate, the Baby Boomers, anti-establishment atmosphere, led to a decline in voter attachment to the political status quo, the traditional parties
growing disdain against patronage, the more they practice it the less esteem they are held in, yet it’s a traditional function
television clips, House of Commons, emphasis on the leader, popularity quickly gives rise to familiarity and then contempt, increasing cynicism about television politics, contempt of photo-ops, e.g. Stockwell Day and the jet ski
has led to parties relying less on the grassroots, turn to professionals who strategize, no longer community organizations
television has multiplied the impact of scandal, makes for great news, but government is remote, impregnable in perception, party not an intermediary to the system, out of touch with constituents
the acceleration of globalization, voting rates highest in 1950s when Canada’s project of national rule was at its height, the Keynesian era, government intervention, economic and environmental problems are international in scope, no one government dominates, the neo-conservative approach to government that reduces the scope of the welfare state, they themselves don’t seem to have the answer, aren’t taking part, people themselves are increasingly mobile, less tied to the community or the party
the impact of Canada’s electoral system, the first-past-the-post system works best in a two party situation because the winning party is guaranteed at least 50% of the vote, but in a multi-party democracy they only need a plurality, e.g. Rae’s government with 38% of votes got a majority, votes not translating, fewer voters, fewer votes counting… question of legitimacy!
Party Responses
one response was the release of campaign books, Chretien’s Red Book, Harris’ Common Sense Revolution
to appear more accountable, tangible
another one is the growth of populist discourse, around free trade, constitutional reform, evidence of a rejection of brokerage politics, increasingly in the early 1990s voters were demanding to be consulted directed, rejecting parties as a gateway, e.g. Charlottetown
after their 1993 wipeout, the Tories adopted a new party constitution in 1995, founded upon the pre-eminence of the membership and the local offices, pushing power down, e.g. one member one vote system for electing leader
Reform Party able to generate and ride the populist wave, portrayed itself as a genuine grassroots party championing grassroots democracy, direct democratic measures, referendums, recalls, proportional representation, reduction in party discipline called for, they don’t have a party whip in their caucus and instead adopt a caucus co-ordinator, vow that they will be dignified in parliament, Manning sits in the middle not in the front, spend money on television town hall meetings to sound out Canadians, a symbolic message that Parliament isn’t the most important locus
not without repercussions: NDP government of Clark subjected to repeated attempts to be recalled, towards the late 1990s the “Total Recall Campaign” which targeted every member of the BC legislature to oust Clark government
in Ottawa, Reform soon changes, moves towards opposition party tactics, Manning moves to the front bench, adversarial logic, cat-calling, desk-banging, Manning has dental surgery and laser eye surgery, from a folksy image to a leader, maintaining as strict a party discipline as anyone
Mercer’s move to change Stockwell’s first name to Doris
Chretien Liberals introduced wide-ranging changes on elections, the limit on how much parties and candidates could receive was reduced, contributions from unions and corporations were banned, the new law provided for taxpayer funding of the parties (had to get it from somewhere and couldn’t count on voluntary contributions!), this suggests that political parties which really emerged as private organizations are shirting further into the public sphere, increasingly intertwined with the state apparatus, a measure meant to reduce voter alienation has the affect of increasing the state’s role in the process
alienation doesn’t necessary mean a decline in participation, proliferation of special interest groups, promoted by the funding of the Trudeau Liberals to promote participatory democracy, allegiance not to parties but to interest groups, even the corporate sector began spending more money on trade groups and lobbying than on contributing to the parties
e.g. successful effort of Doris Anderson “Canadian Advisory Council on the Status of Women” and the “National Action Committee on the Status of Women” to ensure that gender equality entrenched in the Charter
NAC’s relations with the three main parties began to erode, adopted an apartisan approach, an extra parliamentary opposition, consistent with the membership’s disdain for political parties, easier to attack it than work within it
the challenges of reconcile, especially NDP, e.g. unionized loggers and environmentalists
Smith’s article: the Courts have been used, even before the Charter, as a means of advancing claims, Liberals able to use Court for gay rights
voter alienation has led paradoxically to the proliferation of parties, from just four in 1972 to 14 in 1983 (some just mockeries)
individual citizens turning to social movements, governments turning to non-party organizations like think tanks and interest groups for input
an eventual death?
parties transforming themselves to guarantee their continued relevance, how they adopt and respond to regionalism and globalization, linguistic and cultural cleavages, the social and economic challenges of an increasingly aging population, alienation
Notes are from a combination of Matt A, Alex H and others at McGill in 2006.
• Compact theory of Canadian confederation
Compact theory is the view that the constitution is a political agreement (or compact) between the country’s 4 colonies entities (Upper and Lower Canada + New Brunswick and Nova Scotia). And as such, Nova Scotia and New Brunswick should have massive influence today regardless of the demographic, economic influence of those two provinces today. “It was what was negotiated to even create the country, so we need to continue upholding what created the country in the negotiation.”
o a pact between provinces to respect the provincial jurisdictions o an agreement between the British and French people in Canada
• George Stanley’s 1956 paper o compact of cultures rather than of provinces o Quebec represented French/Catholic culture and Ontario represents the English/Protestant culture o this compact of cultures evolved into a compact of provinces as time passed, but this wasn’t the original intention of confederation o distinction between founding provinces and those that were born out of the federation (Alberta and Saskatchewan) o Stanley argues that Quebec continued to subscribe to the idea of a cultural compact
• FACTORS THAT LED TO CONFEDERATION
o American Imperialism o Fear of westward expansion of United States o Need to improved railway communications o Political impasse in Canada this was due to demographic changes • Gradually, Canada West (Upper Canada) began growing very quickly • when Upper Canada realized the demographic situation they were in (they were in the numeric majority) they wanted representation by population • English speaking Protestant part of Canada wanted a more centralized union
George Etienne Cartier, George Brown and John A MacDonald
o this was the view of Sir John A and George Brown the French wanted to ensure that they kept what they were keeping what they were already given by the British government “only federalism would permit the two distinct cultures to coexist side-by-side within a single state…but not a fuzzy one, but rather one that is more clearly stated” a new Union would be federal in character…that the power of the federal government would be national and the power of the provincial would be local • education is split between the federal and provincial government the residual powers would be given to the central government • ROC = Rest of Canada • the constitution lets the federal Parliament and Senate to legislate for the “peace, order, and good government” of the nation • Section 91 of BNA Act gives federal powers • Section 92 gives provincial powers o there has been a shift towards more powers for Section 92 • Quebec would argue that here HAS NOT been more powers shifted towards the provinces, and would argue for MORE provincial powers
• Siegan report deals with the ideal of “Fiscal Imbalance” o argues the federal government assumed a large burden in 1867 o because of the powers that it assumed, it required heavier financial “passing” o constitution of 1867 empowered the fed government to levy taxes by any means while it attributed to the province’s field of direct taxation, …, …, … o the fed government was allowed to levy excise tax and custom’s duties
o DIRECT TAX VS INDIRECT TAX
direct: like the GST indirect: more of a hidden tax (tobacco) • giving the provinces the power of indirect taxation was NOT a large gift because they hare HEAVILY unpopular with the public and could result in being held politically accountable (during a provincial election) o by giving up the indirect tax (excise tax), they gained in exchange a per capita subsidy
-asymmetry lets some provinces have more powers than others
Twentieth Century Debates in Federal-Provincial Relations
-1884 J G Robins (treasurer of Quebec) pressed for four demands 1) Compensation paid to Quebec by federal government for the expenses associated with railway construction 2) Increase on per capita subsidy, above what was provided in the BNA Act -provided based upon the 1861 census -increase in subsidy would change the amount that was being given in 1861 3) The interest of Quebec’s share of the surplus debt -by joining confederation, Quebec began with an economic clean slate 4) Relieved of the cost of the administration of justice -cost increased annually as the population increased
-188* Ontario treasurer (S C William) -since Ontarians were responsible for half of the federal income, the potential buyout of the Montreal buyout would cost Ontarians millions. Therefore, Quebec had to find its own way to resolve its financial plight. This is because he blamed their issues on bad spending habits.
Quebec was in financial straits early on in Confederation
Quebec believed that confederation was the cause for this economic trouble Ontario believed that it is not a problem based on the rise of confederation; it is Quebec’s own making that caused the problem
1930 study by James Maxwell -argues that the growing difficulty that Quebec encountered in meeting its debt payments was the principle reason for the reevaluation for the 1867 confederation settlement -when the debt settlement in 1873, the general settlement (t granting of one favor) simply led to the wanting of another
Political reasons for this disagreement:
-Liberals were in power in Ontario between 1872 till -Conservative government in Quebec -Ontario’s lack of sympathy isn’t for no reason…they were conflicting governments in power
Cultural reasons for this disagreement:
-the cultural and religious differences were seen to be significant
Claude Ryan talks about the idea of “concerted action by the provinces” -the father of inter-provincial relations was Honore Mercier
Ontario 1887, Honore Mercier convened the first inter-provincial minister conference -premier of NB, NS, and BC didn’t join -discussed issues relating to federal government subsidies -discussed outstanding issues between Quebec and Ontario -Treasurer of Ontario decided to also take extra subsidy if Quebec gets more….if Quebec gets more, then Ontario will too….but Ontario doesn’t want anyone to get more “-if Quebec gets relied from its financial embarrassment, Ontario should receive the same”
-the proponents of subsidy increase argued that the federal excise and customs duties (which the provinces gave up to the federal government, rose significantly since 1867), therefore the provinces deserved more
Provincial and Regional Identities
Brownsey & Howlett, “The Provincial State in Canada” in PROVINCIAL STATE
-cultures as equated to ideology -philosophy of liberal/conservative thought
-political economy standpoint: -these (cultural) ideologies interact with economic forces
-formative events or founding moments in provincial history -e.g. founding -Seymour Lipsan: provinces are the products of a single, formative event -the American Revolution is that event formative events are subject to four subjects (events along the way that might change a culture): 1) Stress 2) Periodic assault 3) Possible modification 4) Cracking
-Newfoundland could not be forced to adopt responsible government or confederation -this formative event is significant to Newfoundland’s political culture
Jedwab’s 5 Points:
1) Geography 2) Economy 3) Demographic pattern -who settles there, what customs did they bring with them? 4) Perceived distance from the center -distance from decision making area 5) Perceived or real dependence on the state
Inducement for the Maritimes to join Confederation:
-the promise of railways to capture the Canadian market, that induced that area to join confederation -the expulsion of the Acadians was the founding/formative event for the Maritimes (Weisman) because it ensured that there would not be a dual future for both languages in NS and PEI -NB was an exception, because the Acadians escaped to New England -outside NB, there was a more “elite”, “conservative” culture -the American Revolution helped populate the Maritimes -and the region was more liberal than Newfoundland, but the Maritimes did not have the other formative event that took place in upper and lower Canada (rebellions in late 1830s)
-Newfoundland was rattled by political scandals -they couldn’t turn to Ottawa, so they turned towards the British government -1949 was Newfoundland’s founding event
Louis Hart’s Fragment Theory
-Hart’s idea that the politics of new societies are shaped by the older societies from which they originated
-the 19th century belonged to the Conservatives -Laurier proclaimed that the 20th century would belong to Canada (not the case…but he probably meant the Liberal Party)
Manitoba’s Fragments
-Manitoba’s founding moments were the Riel rebellion and the completion of the CPR -Winnipeg General Strike
Saskatchewan’s Fragments
-Saskatchewan’s formative event was both the CPR and the squashing of the rebellion and hanging of Riel -Saskatchewan’s boom/bust cycle, in addition to its one crop dependency (wheat) -this led to more cooperatives in the province (and the founding of CCF)
Alberta’s Fragments
-Alberta’s formative event is the “last best west”…end of the new frontier -Alberta found itself with a lot of Nebraskans, Dakotans, etc -this led to the UFA (united farmers of Alberta) -the importation of ideas from the USA (monetary reform, and issues of direct democracy) -emergence of oil wealth in the late 1940s
BC’s Fragments
-British Columbia’s formative event has to do with it’s distance from the center -the founding event is the “last spike” for the CPR
Hartz:
-Gad Horowitz elaborated Hartz’ theory into a Canadian model -Canada’s relative flirtation with social democracy and America’s fanatical rejection of it, was connected to Canada’s ideological diversity, tolerance, and toryism -from a Hartz’ian perspective, Canada had dual cultural fragments -the older society is rooted in pre-revolutionary, pre-liberal France -the second, and newer, English Canadian fragment rejected and fled the American Revolution but was infected with a rationalist, egalitarian ideology -contradictions: -social democracy has been strongest where toryism is the weakest -the inverse is true as well -the Hartz/Horowitz theory is the truest in Alberta
-in 1995, Ontario, BC, Saskatchewan, and Quebec…there were provincial governments that called themselves Social Democrat
-Canadian provincial culture has been affected by waves of immigration -eastern Europe (working class) -they shared the more social democratic expression
How strong is the sense of attachment to a Province vs. Canada? -PEI has the strongest sense of attachment to Canada -NS is second -Quebec has 35% support for attachment to Canada
-Newfoundland has the strongest attachment to their province -then comes Quebec and Alberta
-the sense of belonging to Canada, by age group -15-35yrs, 45% feel attached to Canada -35-64yrs, 53% feel attached to Canada -65+yrs had almost 70% attachment to Canada
Culture of Democracy:
-sum total of political values, beliefs, attitudes, orientations, and opinions of people of a given province
-how do we measure changes in political culture? -historical evolution -founding events -democracy -voter turnout -other forms of political participation
-1963 study by Eomen and Verba -3 types of political culture 1) A parochial political culture -citizens are unaware of the political system which they are part of 2) Subject political culture -citizens are aware of the political system -they inform themselves about its operations -they realize that it has an impact on their lives, but they do little to influence it 3) Participant political culture -citizens are aware of the political system -actively attempt to influence it -generally, Canadians are “participant” political culture, although the argument for both parochial and subject political culture can be true -to what extent is low voter turnout compared to what is known
-Nowell (clientelism) -practice of patronage 1) (Associated with pre-confederation period) local official and his clients offer political support in return for individual favors (such as government jobs) 2) (Post-confederation to WWII) emergence of political parties -relationships between the elected official and the client, becomes less personal because of the involvement of political brokers or intermediaries -with the emergence of the parties, government jobs and contract were awarded on a partisan basis -the party emerges as the patron 3) (Post WWII, expanding government activity) -patronage could no longer be relied upon as a basis for staffing the public service -the patron-client relationship became bureaucratized -the bureaucracy emerged as the patron, at the expense of the political official or party because the bureaucracy had the discretion to license, regulate, and distribute massive amounts of public funds through grants, concessions, and incentives -there is a struggle between the bureaucracy and the elected officials
Political Parties
-how many, and what type of parties make up the system? -2, 3, or multi-party system -One party dominance occurs when parts are NOT evenly matched, and do not alternate frequently in power -Two party system occurs when two parties capture the bulk of the vote between them -three party system occurs when three parties capture 20-25% of the vote -two plus system is where the third party results in 10-15% of the vote -concentrate on the origins of the party
John Wilson
-influence of social class to the evolution of the party system -after 1900, the Liberals and Conservatives were the two main parties, but they had to contend with the newly franchised working class
-agricultureism, anti-stateism, and clericalism were the three modes of thinking during the pre-1960s Quebec
-in political systems where the emerging working class had a greater impact, one of two party systems emerged 1) CCF (cooperative commonwealth federation) 2) The modification of the established parties, to respond to the newly established working class
-in related class ideology to party support, there are two thoughts in political science -looks at the extent to which ideology motivates political activity -the degree of ideological difference between parties -once in power, all parties are reasonable similar and are influenced by the corporate elites -the system’s structure is such that the party has to have a broker to respond to the diverse Canadian constituencies -another school finds a slight difference of approach at the federal level, but a significant variation at the provincial level -e.g. unlike the federal level, there are NDP govs at the provincial level -the Liberal party has two main factions (business and reform group) -traditionally the Conservatives are composed of a higher share of Business Liberals, they are generally more to the right of Liberals of individualism and inequality…but it is the progressive wing of the party that has moved it away from the right
-are ideological differences reflected in provincial government policies?
Province by Province
Newfoundland
-1974-1975 voter turnout was 57% for federal election and 73% provincially -1993 voter turnouts was 55% federally, and provincial turnout was 86% -from 1949-72, Joey Smallwood (Liberal)…1972-1989 the Conservatives dominated Newfoundland politics
PEI
-1972 turnout was 80% in both federal and provincial -1993 turnout in federal was
Nova Scotia
-greater provincial participation in the early 1970s -1980s it reverted to be more federally -recently, provincial participation is greater
New Brunswick
-consistent of 10% difference between provincial and federal turnout, in favor of the province
Quebec
-15% gap between federal and provincial participation….in favor of the province -Quebecers believe that 51% of issues of greatest importance are provincial, but only 25% say that federal government
Ontario
-participate in federal more than provincial elections
Manitoba
-55% of Manitobans argue that the federal government represents the issues of greatest importance -1970s, greater participation in provincial rather than federal -now, participation in each is equal
Saskatchewan
-participation provincially is greater than federal (10-15% gap)
Alberta
-higher participation federally rather than provincially, but they view the greatest issues of importance to be in the province
British Columbia
-70s larger participation in federal -recently, greater participation in provincial rather than federal -1975-91 Social Credit -1991- NDP -Liberals elected in
The Fiscal Imbalance
Fiscal Imbalance in Canada (Seguin Report) http://www.desequilibrefiscal.gouv.qc.ca/en/pdf/historique_en.pdf Department of Finance, Government of Canada ‘The Fiscal Balance in Canada’, October 2004 www.fin.gc.ca/facts/fbcfacts9_e.html
Fiscal Imbalance:
-vertical and horizontal fiscal imbalance -vertical -flows top down -most FI deals with vertical FI -horizontal -between the provinces themselves -Alberta vs. NS -fiscal imbalance arises out of the following 1) If the fiscal gap between provinces own source revenue and their direct spending is too great -because such a differences threatens to subordinate the provinces in relation to the federal government -traditionally, this has been solved through transfers from the federal to provincial government -when the transfers are insufficient to offset the own source revenue of the province to meet its responsibilities, then there is an imbalance 2) Even if the final balance is zero (the transfers offset the gap), an imbalance can still exist if the economy of the province is impaired 3) Can exist when the federal government evokes a spending power to intervene within the province’s field of jurisdiction -insodoing, it has a direct influence on the level of provincial government spending
how to satisfy these problems to create a fiscal balance
1) sources of own source revenue are allocated to each government that allow an equitable division of tax deals committing sufficient financing and accountability in the respective field of jurisdiction within each province -money provided for certain tasks or department -Tremblay Commissions under Duplessi -began based on transfers to universities -in a federal state, the constituent parties must obtain through taxation the needed financial resources to exercise their respective powers 2) Total revenue plus own source revenue plus transfers must enable each order of government to effectively cover its expenditures…but without conditions that may impair its economy 3) Transfers from the fed government to the provinces should not limit the decision making and budgetary decision of the provinces UNLESS the members of the federation have validly agreed to conditional transfers
Regionalism and Asymmetry in the Canadian Federalism
Robin Boadway, ‘Should the Canadian Federation be Rebalanced?’ 2004 http://www.iigr.ca/pdf/publications/343_Should_the_Canadian_Fede.pdf
Kathy L. Brock ‘Accords and Disdord: The Politics of Asymmetrical Federalism and Intergovernmental Relations’ http://www.iigr.ca/__site/iigr/__files/gogoPage/brock%20working%20paper.pdf
Guest lecture from Marc-Andre Bachard active in the Quebec Liberal party (President)
-after the 1995 referendum, he became interested in active politics -Harper may have a tough time delivering his asymmetrical federalism because Ottawa’s civil servants wont tend towards decentralization
Liberal Party of Quebec:
-has the best electoral machine in the country -the party started before confederation -the conservative party disappeared in 1936 and became the Union Nationale until 1960 (in power), but maintained influence until 1970 -1970, the PQ received its first members elected to the NA -it has always been Liberals leaving their party and creating something else (both Union Nationale and the PQ and the ADQ) -there are two forms of political allegiance – the coulonde rouge and the coulone bleau -the values of the Liberal party are based on the idea of “the power of the individual” -the progress of the individual and of society -in the PQ, you will not find anything about the notion of the individual -since the 1960s, the Quebec Liberal party has become socially just
-the relation between the notion of the fiscal imbalance and that of asymmetry -one view is that asymmetrical federalism is a good way to keep the federation together -Cathy Brock – too much asymmetry will not be good -where is the accountability if the federal government is distributing the funds -once you begin to enter into asymmetrical arrangements, this leads to other provinces wanting the same thing -is there a relationship between fiscal imbalance and asymmetry? -there is an imbalance in the federal-provincial transfer, therefore it can be helped/fixed through asymmetry -asymmetry is the unequal treatment of unequals -fiscal imbalance is the equal treatment of unequals
-principle of equality is a continued feature of our federation remaining unified -on the other hand, some provisions of the constitution apply only to one or two provinces -certainly the provinces are NOT equal because they are not equally represented in national government institutions -does it matter that the jurisdictional equality that supports the equal provinces idea is more formal than real? -a few other questions are raised -does it matter with the assistance of resources being generated outside provincial boundaries, that some provinces will find it difficult to exercise the legislative responsibility in a manner similar to that of the other provinces -another important questions -is the economic inequality that coincides with the jurisdictional equality a serious threat to the equal provinces idea/doctrine
-jurisdictional equality -flexible federalism (asymmetry in different terms) -trying to figure out how to represent or empower local government within the institution of the federation -is there a definable limit to asymmetry?
Part II: Provincial Political Profiles
Benoit Pelletier Quebec’s Place in Canada of the Future
Luc Bernier, “Quebec at the end of the 1990s” [BROWNSEY & HOWLETT]
Fiscal Imbalance
-there is some sort of fiscal imbalance, but what is it attributed to? -is it built into the system? exam question-how does asymmetrical federalism play into the fiscal imbalance?
-parting thoughts: -Harvey Lazar (former head of the Institute of Intergovernmental Affairs) -Canadians are not fully aware of the natural of sparing between fed government and provinces -we need to educate Canadians about asymmetrical federalism and the fiscal imbalance -provincial governments and local governments have raised about 55% of total government revenues for the last 25 years -they account for 67% of total government spending -today there appears to be more support for a vertical fiscal imbalance, where the federal government has an easier time meeting its financial requirements than the provinces -almost all federations have some sort of fiscal gap -if the fed government decided the threats to Canadian security requires greater amounts for defense, security, and aid, and these amounts were added to federal expenditures, than the debate about the vertical nature of the fiscal imbalance would shift as federal surpluses would likely erode -Canadians need to be persuaded where their priorities should be -as Ottawa tends to consider further transfers for healthcare or childcare to the provinces, it reinforces the notion that the priorities are at the provincial level and it indirectly lends support to the idea that the imbalance is the fault of the federal government (self-fulfilling prophecy) -Jennifer Smith argues: to compensate for provincial imbalances, the fed government tries to maintain a balance between the constituent partners
Benoit Pelletier Quebec’s Place in Canada of the Future
Luc Bernier, “Quebec at the end of the 1990s” [BROWNSEY & HOWLETT]
Quebec
-there are many different expressions of nationalism within Quebec -three dominate forms of Quebec nationalism: 1) anti-stateism 2) agriculturalism 3) religious/clerical attachment -three periods of this nationalism: 1) Anti-government nationalism of Maurice Duplessis and his Union Nationale -a union of the conservatives and action nationale 2) The state based nationalism of “the province building era” of 1960-1980 3) A market based nationalism 1980s-today
Duplessis
-known as “Le Chef” -Charismatic leadership led to a conservative ideology of the time -the state revolved around Duplessis -Conrad Black wrote a biography of Duplessis and almost “rehabilitated” the tarnished image of Duplessis -it is argued that from 1897-1936, under Liberal premiership, the reign of Duplessis was not that different -ruled with support from rural Quebec -1897, 77% of Quebec’s population was rural -by 1951, only 33% of population was rural -the electoral map was largely in a rural context -with the demographic shift, the electoral map didn’t change much -during the Duplessis period, there was an anti-communist and anti-labour feeling in the province -economy was very prosperous -Duplessis tried to support conditions for substantial investment in foreign capital in Quebec -he did this by establishing close ties with the business community -he had support from mainstream media -both French and English media -also had close ties with the Catholic Church -he relied on the relationship with the church to preach class harmony over militants -he quashed labour unrest during 3 occasions -1949 aspects strike (Trudeau was a lawyer involved) -1952 in Louisville -1957 Murdochville -to maintain low taxes, he resisted demands for increased expenditures on health, education and social services -the clergy was heavily involved in the distribution of these services -this contributed to the Quiet Revolution when these expenditures were increased -roads and highways were the largest expenditures in Quebec (attributed to the transformation between rural to urban) -contracts were awarded in highly partisan ways
Jean Lesage
-Jean Lesage became PM in 1960 -Rene Levesque was part of this -this is the beginning of what is looked back on as the “Quiet Revolution” -he wanted a “catching up of priorities” for Quebec -a cultural affairs ministry was created -the civil service was expanded -a report was created to determine if there should be a ministry of education (it was subsequently created in 1964) -a federal/provincial relations department was created in 1961 -the SGF was created (aimed at supporting entrepreneurial initiatives) -the caisee du depot was created in 1965, looking to support the francophone entrepreneurial class -hoping to decrease the inequity between English and French Quebeckers -the 1962 provincial election was based on nationalizing the Hydro industry -prior to this, the Montreal Lighting and Power owned all this -Rene Levesque was responsible for the nationalization
-the concept of modernization, and improving the inequality within the province (modernization and “catching up”/raportage)
-the election of Lesage was largely Montréal (English speaking) supported -on one hand, for the liberals, the minority vote is a secure base of support (from WWII tiill today…with one exception…1989) -this vote has been taken for granted by the liberals
-1962, the Liberals go to the electorate around Hydro issue, and they win -majority diminished slightly -at this time, the federal government is beginning to look at the condition of the French-Canadian position and its demographic position within Canada -the declining birthrate of the population -the economic gaps and inequities -overall, there is a Canadian concern for the diminishing role of French Canadians -a transfer of responsibility between the clergy and the middle class elite of Quebec -this is a willing transfer, because the clergy does not have the ability to support the needs of the residents of Quebec -the federal government feels a need to step into this debate -they create the Royal Commission on Bilingualism and Biculturalism -this commission (proposed by Pearson)…the RCBB’s purpose was to develop an “equal partnership” between the two founding peoples -this didn’t take into account the various other ethnic groups -as this commission was taking place, the government addressed the problem of the inequity between the English and the French
-3 approaches that arose from the RCBB 1) Inclusion -bringing more French speakers into the decision making apparatus federally -this apparatus was under a time of expansion anyways 2) Recognition -recognizing the distinctive features and characteristics of Quebec -this was the initial recognition of the recognition of a French Canada (not necessarily French Quebec, but French Canada) 3) Devolution of Powers -transfer of greater power or responsibility onto Quebec
-the flip side from a Quebec point of view (of the three points) -the issue of affirmation -independent of the fed government’s strategies that it adopts for the issue, Quebec will develop strategies of affirmation on its own -this affirmation will range from things that occurred during the Quiet Revolution, to outright sovereignty
-Quebec is still torn between the fast movement of reform and change from the 1960s, and the continued sense that it is moving too far and too fast
-in 1966 there was a provincial election, and Lesage campaigned on continued reform -communications ministry was created in the 2yrs previous to the election to deal with the French language issue -a department of immigration also began to be created -there was new electoral boundaries drawn up for the ’66 election (11 new seats were created in Montreal) -the public service grew by 42% between 1960-1966 -in the mid-sixties, two small parties emerged advocating for the breakup of Canada -RIN (more socially left) -RN (more right wing)
-1966 the Liberals lost the election -Daniel Johnson Sr. won for the Union Nationale -56 seats for Union, and 50 seats for Liberals (Liberals had 48% of the vote, and the Union had 41%) -Johnson understood the nationalist sentiment
-Johnson had to deal with the issue of language
McGill University – Provincial Politics class these notes are from in 2006 | Guest Lecture: Stephane Dion
1) Canada’s provinces have a lot of power 2) The number of “provinces” in relation to other federal states, is relatively low 3) The provinces are weak within Ottawa. Canada does not have a Senate (in terms of a Chamber of provinces) 4) Strong executives 5) Existence of a minority that is a majority in one province
McGill University – Provincial Politics class these notes are from in 2006 | Guest Lecture: Boisclair
-Boisclair guest lecture
-Québec does politics democratically -the referendum was lost by 50,000 votes, but not a single drop of blood was shed
-sovereignty must come from a referendum, not an election -Boisclair is a democrat before being a sovereigntist
-what is sovereignty? -a protection of culture -identity 1) Capacity of Québec government to vote for its own laws 2) Québec should receive all taxes 3) Québec has an international existence
-why does Québec feel like it should separate but this feeling is not the same in other provinces? -because Québec is a nation -National Assembly -National… -the Canadian constitution states the two founding nations -Québec is already a nation
-when Charest asks Harper for more control for the “nation of Québec”
-why does Québec want to be its own separate nation? -the quiet revolution provided things for Québec that weren’t available before -because they want to continue to exist as a francophone in the context of North America
-the reasons for sovereignty today are not the same as they used to be -Boisclair’s father was not treated well/properly because he was a francophone -this is not the case anymore
Provincial Profiles: British Columbia and Alberta
Michael Howlett and Keith Brownsey, “Politics in a Post-Staples Political Economy” [BROWNSEY & HOWLETT] Peter J. Smith, “From Social Credit to the Klein Revolution” [BROWNSEY & HOWLETT]
Phil Resnick. The Two British Columbias www.iigr.ca/pdf/publications/136_the_two_British_Columbia.pdf
Peter Stotland
-he began in Medicine hat -covered the Loughheed government in the late ‘80s -then covered Western issues from Ottawa -came back to Alberta for the “Kleinilution” -will give his position as an observer, standing outside the political process
-Alberta was governed by social credit from 1935-197? -then PC under lougheed from 197? Until present day
Social credit
-Manning -Harry strong -Lougheed
PC
-Lougheed -Ghetty -Ralph
-with the three leaders of the PC, you have three very different leadership styles -almost different parties, except by name -within the one party, there are different differentiations -Alberta’s provincial politics are the least ideological than anything else in Canada -it’s more about brand loyalty -when Lougheed was putting the conservative party back together, he was looking for a brand that meant credibility -he didn’t care what they called it ideologically, but it was important to know what it meant -what matters in Alberta, is what works….pragmatic management -the only government that began to dabble in ideological thoughts, it was a disaster -the “kleinilution” is nothing like a neo-con agenda…it was a new brand that was needed that was pragmatic and worked -in 1995, Klein was on a trade mission in the middle east, and Preston Manning had mentioned that he was interested in creating a provincial wing in Alberta to challenge Ralph’s lack of ideological thought -Ralph never countered this ideologicalness
-Albertans are not interested in political parties, they want pragmatism that works
-in Alberta politics, you give the people back what they will believe is there’s -do what people want from you
-politics is divided into three regions -rural -pragmatic ideas -we need roads, hospitals, necessities of life -Calgary -a force for political homogenization -a suburb city -there is a force that makes people accept and get along by going along -Edmonton -far more of a “folksy”, “artsy” type of city -the UofA is a more dominant force than UofC is in Calgary -the UofA is part of the metro-Edmonton area -Calgary is the city of money -the city of head offices -Edmonton is the city of workers (blue collar)
-4 leaders since 75 -William Aberhart -Ernest manning -Peter Lougheed -Ralph Klein
-quasi-party system, due to the near one party dominance -the liberals were strongly associated with immigration, so liberals often received the immigrant vote -Alberta in 1905 was liberal, because of the immigrants
-the emergence of social credit -because the UFA were ineffective in combating the effects of the depression -the “show me the money” party -1941 the industrial workers outnumbered the farmers -the overthrow of SC was due to the urbanization, secularization, and geographic mobility -changes in Alberta coincided with changes elsewhere -under the Mulroney regime, we saw the elimination of the NEP (National Energy Program) -there was more attention paid to agriculture -pursuit of free trade -Don Ghetty pressed for the elected senate -Ralph Klein took power of the Alberta PCs, but federally, the PCs lost power
-on federal-provincial relations, Alberta has been relatively calm
-sources of division -Medicare -cutback in shared cost programs
-more recent federal Alberta issues: -reforming fiscal arrangements -the desire for greater flexibility for personal income tax -reducing overlap and duplication -notably in energy, agriculture, economic development, labour market policy, and the environment -minority language education, petroleum industry, grain transportation,
-the three dominate issues between Alberta and federal government: -health care -environment -oil wealth / equalization
-positive net migration -endless opportunities, but these opportunities are limited by the federal government
McGill University – Provincial Politics class these notes are from in 2006 | Guest Lecturer – John Parizella
John Parizella speaking -director of Quebec Liberal Party (20yrs ago) -chief of staff to Robert Bourassa -talking on federal-provincial relations theme -he’s worked 18 provincial campaigns -2 federal elections -ran in 1985 in Mercier and lost by 1100 votes -worked with Bourassa for 9yrs…lived through Meech, Charlottetown, Bourassa’s cancer -he is a practician
-why don’t we hear of “American federalism”? -Canadian characterize our country as federal vs. provincial governments -federalism won as a concession to Quebec to allow each province the ability to handle their own issues -BNA Act -Article 91 -powers of federal government -peace, order, and good government (residual clause) -Article 92 -powers of provincial government Article 93 -education in Quebec -two kinds of periods of federal-provincial relations -periods of centralization -periods of decentralization -this has mostly come from the courts
-are we in a period of centralization or decentralization? -for the last 4 yrs, we have been in a decentralization period -the administrative powers of jurisdiction have often favored the provinces (especially Quebec) -the BNA Act looks like a centralizing constitution, but in practice, it has worked towards the provinces
-administrative arrangements -Health Care deal 2004 -Day Care deal -federal-provincial relations cannot just be looked at constitutionally, it has to be looked at from an administrative viewpoint -this is done with by the premiers or the civil service -there is a lot going on between federal and provincial government on a daily occurrence
-the process of the relationship is looked at in two ways -informal -deals with chief of staff to Mulroney on a daily basis during Meech Lake -formal -the last meeting to try and kickstart the accord…the meeting was supposed to last 3 days, but lasted a week
-diplomacy -usually associated with IR -an emerging term, because we cannot wait for a meeting with cameras, the relationship occurs everyday -domestic diplomacy -the premiers have to talk to each other, and to the fed government, and vice-versa -this has to occur with respect and with the notion of dialogue
-institutions that govern federal-provincial relations -conferences -dinners at 24 Sussex with all the premiers -or they have a formal meeting with each premier having their staff with them -they used to meet every year -but they now meet based on issues as they need it -Council of the Federation -Charest’s initiative -all 10 premiers meet and hammer out an agenda that works to build a consensus to defend the province’s jurisdiction -this can lead to a formal federal-provincial conference -gives the provinces the ability to get their act together and speak with a united voice
-what are the subject matters that dominate federal-provincial relations? -economic union -although we have free trade, there is little free trade between the provinces (it is often north-south free trade rather than east-west) -how can we ensure the economic sustainability of the federation -social union -healthcare -the provinces are responsible for deliver of service -41% of Quebec’s budget is spent on health care -education -the feds have a role in research -but managing education (building, programs, professors, K-12) all managed by provincial governments -fiscal -all premiers agree that there is more cash in Ottawa than in the provinces -political union -often constitutional -the appetite isn’t big for this type of discussion because it usually ends in failure (Meech and Charlottetown) -equalization -British Columbia, Alberta, Saskatchewan, Ontario give into equalization – Atlantic, Quebec, Manitoba receive
-the question of Quebec -perspectives -the West -always felt alienated and never quite felt comfortable in the federation (NEP) -Reform came about to advocate the West’s interests (couldn’t become a national party because of its strong western views) -Ontario -seen as the fat cat in Canada -Maritimes -receives a lot of equalization -Quebec -the tail that wags the dog -why is Quebec so complicated? -book by Andre Pratt that shows the myths around the relationship between the fed and provincial governments (he is federalist)
-three thoughts in Quebec -Trudeau vision of federalism -he came to power saying that Quebec had to play a role by expanding the presence of French beyond the borders of Quebec and to become involved in power -more centralized -renewed federalism -believed that we can change the federation to work better and respect the differences in the country -make the west feel welcome -and make Quebec feel involved -sovereignty -hard liners -Jacques Parizeau -Quebec must become a country -soft liners -Rene Levesque -need an association -sovereignty (hyphen) -the sovereigntists argue, but they do it internally, and at the right times
-governing with Quebec is tough -Quebec will work for a deal, and if they get it, they want more -Trudeau federalists don’t have a bright future (dying breed) -Quebec fed Trudeau, and Trudeau fed Quebec (they needed each other) -Trudeau’s vision needed to continue with Trudeau, because he was one of their own -he was SO unique, and one of a kind
BC
-1867 there wasn’t much discussion of British Columbia joining confederation -in 1871, a number of factors led BC to join Canada (a means of debt relief) -25 member assembly in BC -government was administered by a shifting combination of factions, and patronage oriented politics -1871-1875 the national railroad dominated the political discussions -in the 1870s, the country was hit with a depression/recession -the railway was not completed on schedule -1876 a petition was circulated which raised the idea of BC seceding from Canada because there was no railway completion -progress with railway construction in the coming years -lots of Chinese labour brought in to work on the railways -November 1885 was the last spike for building the railway -the CPR completion was a major boost to the economy and created a political environment dominated by merchants, lawyers, industrialists, and landowners -timber and mining rights were widely distributed -immigration was relatively high for that period -Vancouver developed as an important port for Canada (especially in the lumber export area) -the employment of Chinese labour was a contentious issue -this led to the establishment of labour representatives -by the turn of the century, marked by social tension and unrest as labour became increasingly organized -fishing and mining sectors had considerable strike activity -substantial anti-oriental sentiment among the workers -the province became a “hotbed” of militant unionism -laws were passed prohibiting Orientals from working in the mining area, denying them franchise, and federal action was demanded to restrict Chinese/Japanese immigration -this 20th century period, (of political instability), set the stage for the emergence of party politics in the province -factors contributing to this development -the need for political cohesion -the growing isolation of communities -the business community wanting a stable investment climate -the federal parties wanted to have solid provincial branches of their parties -as party lines solidified, Conservative leader was called upon to form the government in 1903 (Richard McBride) -this began a 12 year rule under McBride during a period of strong economic growth
-3 general platform ideas: 1) Railway development 2) Better terms from Ottawa 3) Exclusion of Asians -McBride’s government was persistent in passing anti-Oriental legislation, which was either disallowed by Ottawa or overturned by the Lieutenant Governor -although McBride encouraged a fast expansion of the provinces resources, there was legislation brought in to protect timber and water resources -there were also some measures to improve the condition of the working class, and to protect public health -new schools were built, and provincial archives, and the university of British Columbia -so by the 1912 election, the socialist party (opposition) elected 2 candidates and the Conservatives won 40
-the economy began to boom by the late 1920s -several pieces of social legislation was introduced 1) Extending minimum wage laws 2) Workman’s compensation 3) Industrial disputes Act -Premier John Oliver had through the 1920s successfully challenged the federal government over railway freight rates and liquor legislation -a plebiscite determined that the people preferred government regulation than prohibition -1920s also a period of significant construction -roads and bridges being built -all good things must come to an end
-with the depression of 1929, most provincial industries collapsed -the Conservative Premier Simon Tolmy??? Had difficulty rebuilding the economy -because of BC’s mild climate, it attracted immigration from other provinces, and had to establish relief camps to alleviate the large influx of people -the government was charged with corruption -under great stress, the Conservatives approached the Liberals (lef by Duff Petulow?) with the offer of a coalition government -but the Liberals were on track electorally, and refused the offer and waited for the 1933 election -the Liberals improved their lot and came to power with 34/47 seats -this election also marked the appearance of the CCF which attempted to unite the divided factions on the left -Petulow was running a centrist party and ran on the slogan of “Work and Wages” and presented what some referred to as the “Little New Deal” -described his approach as “practical idealism” compared to the “visionary socialism of the CFF” -the first of the radical premiers of the 1930s with a focus on progressive liberalism -rather than cut public expenditures during the depression, Petulow had the government increase purchasing power through job creation and private sector subsidies -but as federal finaicinial support for this approach didn’t materialize (even though there was a Liberal in Ottawa, PM King, and in BC) in the mid-1930s, and Petulow began advocating provincial rights -in the face of widespread strikes, high unemployment, and growing debts, Petulow increased relief efforts, raised minimum wage, limited work hours, and offered financial aid to the troubled fishing and mining industries -by the late 1930s, the economic situation began to improve -Petulow then focused on northern development in the search for oil -he also looked at annexing the Yukon
-1937-1941 Petulow embarked on “socialized capitalism” -centered on government regulation -also became obsessed with the idea of provincial rights -in response to the improved economy, the federal government closed relief camps in 1938 and the province then decided to cut off relief to the unemployed people from the Prairies (those who migrated into BC) -this resulted in demonstrations in Vancouver -property damage and injury occurred as people were aksed to evacuate -some criticized Petulow for his quarrel with Ottawa going too far -in reaction, Petulow join William Aberhart and Mitch Hepburn (Ontario) in opposing federal review of the provincial-federal distribution of powers under the Robert *** Commission -but the provincial right strategy lost favor with British Columbians after the outbreak of WWII -Petulow’s party and the electoral became dissatisfied with his leadership -he also began losing support from both the left and right as his middle ground became untenable -by Oct 1941, the Liberals were reduced to 21 seats, CCF 14 seats, and the Conservatives 12 seats -the CCF has the largest plurality of the popular vote -there was a strong sentiment for a coalition government -Petulow rejected the idea of a coalition government, because the ideological differences between them all were too important, therefore no basis for inter-party cooperation -but there was pressure from business class, and Liberal/Conservative politicians -so in December of 1941, a Liberal resolution endorsed the idea of a coalition government which forced Petulow out -John Hart became the new leader of the Liberals, and also the leader of the Liberal/Conservative coalition government
1941-1945 was dominated by national and international events and decision making -the domestic (provincial) scene was reduced in importance -the most controversial issue was the uprooting and interment of the Japanese community -the federal government removed 20,000 Japanese Canadians from the West Coast -confiscated the property of many of them -and dispersed them across the country, or deported them -this was all occurring during periods of economic prosperity
-1944 BC Federation of Labour formed -this benefited the CCF to some extent (with the growth of labour), but the presence of the communist leadership in the CCF provided political ammunition to the coalition government against the CCF -the Liberals/Conservatives were forming together in the election of 1945 to fight the CCF
-the post-war period economy was prosperous, and the CCF continued to encounter some difficulties -some was connected to international cold war tension -late 1940s, the Social Credit party was building support -in the 1949 election, the Liberal/Conservative coalition was returned with 39 seats, and the CCF reduced to 7 seats -the early 1950s, witnessed the disintegration of the Liberal/Conservative coalition and the growth of Social Credit -the catalyst for the demise, was the new hospital insurance scheme that went into effect in 1949 -the Conservatives insisted on high premiums and daily user fees -the Liberals wanted to operate the plan out of general revenue -the Liberals in the midst of all this called an election in 1952, and anticipating the breakup of the coalition, introduced a new electoral system (the preferential system) -ranking the candidates in order or preference -instead of voting with a single x, you rank your numerical preferences -the logic is…even though the Liberal and Conservatives were no longer partners, they preferred each other than the CCF, so the Libs could rank Conservatives second and vise versa -a mistaken assumption, as the supporters of each coalition party, opted for Social Credit as their second choice -a fresh, but safe private enterprise alternative to block the CCF -even the CCF supporters ranked the Social Credit second -the results were19 seats for Social Credit, 18 seats for CCF, 8 for Liberals, 4 for Conservatives -the leader of the Social Credit (W A C Bennett) formed the government -an honest man -he disavowed the original Social Credit idea (money printing) and operated with a modern Conservative approach -obsessed with the growth and development of the provinces abundant natural resources -especially sensitive to the needs of Interior communities -he used the natural wealth of the province, and his own dominate leadership style, and a good read of public opinion to provide stability for government in British Columbia -this resulted in a string of Social Credit majorities -3yr intervals (one 4yr interval) from 1953-1969 -strong share of popular vote in each instance -“progress, not politics” was the Social Credit slogan in the 19** election -the electoral system also returned to the original system -the Social Credits being approved by all classes of society, especially the middle class
-the mid 1960s saw considerable economic growth (continued growth) in the province -notably in the pulp and paper industry -the government abolished bridge and road tolls -introduced a partial medicare plan -fought with Ottawa over the reluctance to establish the Bank of British Columbia -all good parties must suffer at some point, and in the late 1960s, economic problems emerged, forcing the government to introduce an austerity program -lay offs and strikes occurred -and an increase in confrontations between government and organized labour -Ottawa finally approved the Bank of British Columbia on the condition that there would be no provincial government involvement
-1970s had the collapse of the Bennett regime -an election of the first NDP government in the province
McGill University – Provincial Politics class these notes are from in 2006 | Guest Lecturer Professor Antonia Maioni
Healthcare and Provinces in Canada
1) Jurisdictional responsibility vs. fiscal capacity -there is a myth that there is a “Medicare system” in Canada -but there are actually 10 unique systems across the country -Canada Health Act is a federal statute that sets the rules for the money that Ottawa sends the provinces -the provinces are each governed by their own individual healthcare legislation
-division of powers (1867) -healthcare is a prime example that wasn’t important in 1867, but is very important now -Section 92(7) healthcare is a provincial jurisdiction -however, the federal government has carved out a space for itself in the healthcare system -the federal government controls the money, so it plays a role -how much does the federal government spend on healthcare -the provinces say that the federal government spends 15-18% on healthcare -but the federal government believe they spend 25% -provincially, healthcare is eating up 35-45% of the provincial budget -this percentage is rising
2) Historical development of healthcare systems -provincial innovation vs. federal diffusion -the CCF in Saskatchewan, led by Tommy Douglas, came to power in 1944 on the platform of providing medical services for all citizens -he realized that the idea of healthcare for all wasn’t supported by all -doctors needed to be convinced -hospital public insurance began in 1947, in order to pay the doctors directly, but patients wouldn’t need to pay for their stay at the hospital -this program became popular in other provinces -Ontario (Conservative government) took the example from Saskatchewan and thought about also implementing hospital insurance -the Ontario premier wanted to bring the federal government in to help implement this expensive program -in 1957 the federal government passed the Hospital Insurance D S Act to help pay almost half of the cost of hospital insurance -the provinces quickly signed on -by 1961 the provinces had legislation in place in order to receive the money from the federal government -the hospital insurance program freed up money for Tommy Douglas to introduce public medical insurance in 1961 -physicians went on strike in 1962 in Saskatchewan to protest these new measures -to end the strike, the provinces conceded that doctors would be reimbursed by the provinces and would retain their autonomy as professionals (they could bill for every service, they could have their own clinics, etc) -Canada doesn’t have salary doctors….they bill for what they do -1962 the first public medical insurance program inaugurated in Saskatchewan -the question was when the domino effect would hit the rest of Canada -the federal government in 1962 was on shaky ground, so Diefenbaker called a Royal Commission on Healthcare (the Emit Hall Commission) -this commission ruled that all provinces should have similar medical systems to Saskatchewan -this report was presented in 1964 to the Pearson government -the 1960s in Canada was ideologically polarized -Alberta (Ernest Manning under Social Credit) had different ideas -Manning Care -voluntary insurance systems using private insurance -Manning was eventually trumped by the federal government’s fiscal capacity -in 1966, the federal government passed the Medical Care Act as a cost sharing program -for all provinces that set up a system similar to Saskatchewan, the federal government will reimburse for 50% of every dollar spent by the province on the health system -by 1971, every province had a medical system like Saskatchewan’s in place -for both public medical insurance and public hospital insurance
-in 1977 the federal government decided to change the way which they send money to the provinces -Established Programs Financing Act came in to place -instead of receiving the health bill from the provinces and reimbursing the provinces 50%, the federal government would provide a block sum of money to the provinces -this meant that Canada would no longer be on the hook for the rising costs of the healthcare system -all overruns would have to be covered by the provinces
-in 1984, Trudeau passed the Canada Health Act which would include 5 principles -if a province transgressed on any of these prinvicples, the health minister would cut funding to the provinces -the provinces NEED the federal funding -the five principles: 1) Public Administration -money to pay for doctors and hospitals had to go through the provincial treasury -public payment -accountability for the money 2) Universal -100% of residents of a province were covered and eligible for health insurance 3) Comprehensive -all medically necessary services had to be covered under provincial health systems -what is deemed medically necessary? 4) Portable -a citizen in Moose Jaw that moved to Montréal must be covered -their coverage is portable across the country 5) Equal Access -the most controversial -healthcare would be provided on equal terms -no cue jumping…everyone is treated the same way -according to need not financial position -1986-87 the Ontario doctors went on strike to protest -the provinces are having a tough time following all these principles but also paying for healthcare -Mulroney began cutting the lump sum of healthcare transfers -1995 Canada Health and Social Transfer -put in place by Finance Minister Martin -all money for social programs that the federal government sent to the provincial government were put together in one lump sum, and this number was reduced -so healthcare, education, welfare, any other social programs one payment -all these federal cuts to the provinces were then passed on to the hospitals (governed by health districts) -the hospitals then have to make significant cuts within their hospitals
-by 2004, federal-provincial relations were in a bad state -the public’s confidence in the public health system was lost
-although the public health model is hugely popular, the system is put under the microscope
3) Financing and basic principles
4) Future challenges -the role of the courts -“private” initiatives in provinces
Chaoulli v Québec
-the Canadian charter was applied to a Québec law that the waiting time infringed on his charter rights -the Supreme Court used the Québec charter to side with the plantiff -the court said that Québec’s ban on private insurance was infringing on individual rights when there is undue waiting time -this has opened up a can of worms…lots of questions -innovations for reform are coming from provincial governments
-Québec’s response to the Supreme Court -allow private insurance for a few services (elective surgery for hip/knee and cataract) -also puts in a waiting time guarantee -if they do not receive their service by a certain time, the patient will go to a private clinic and the public system will pay for it
-Alberta’s Third Way -considering allowing physicians to work in both the public and private health services
-British Columbia is shopping for healthcare models in Europe
Provincial Profiles: Manitoba
Kenneth J McKenzie. “Reflections on the Political Economy of Fiscal Federalism in Canada.” C.D. Howe Institute Working Paper (September 2005).www.cdhowe.org/pdf/workingpaper_4.pdf
Premiers of different administrations: 1878-1887 – Conservatives 1888-1900 – Liberals 1900-1915 – Conservatives 1915-1922 – Liberals 1922-1943 – United Farmers of Manitoba 1943-1958 – Liberal Progressives 1958-1969 – Progressive Conservatives 1969-1977 – New Democrats 1977-1981 – Progressive Conservative 1981-1988 – New Democrats 1988-1999 – Progressive Conservative (Gary Filman) 1999-2006 – New Democrats (Gary Doer)
-initially a small and primitive place (1870) -unlock the other six provinces, it lacked a representative and responsible government -12,000 people lived in Manitoba in 1870 -560 aboriginals -6,000 Metis -4,000 English/Native origin -1,500 white non-aboriginal -there was a slight French majority in the province in 1870 -owned and governed by the Hudson’s Bay Company -had the most violent entry into confederation -Louis Riel formed a provisional government that elected 12 English and 12 French delegates -went to negotiate with Ottawa, but wasn’t recognized for provincial status -within the violent clashes, 3 people (including Thomas Scott) were killed -Orange Order (militant Protestant group) -province established in 1870 and was officially bilingual -guaranteed separate schools system built in to the Manitoba Act -the fed government maintained control of Crown land and natural resources – needed fro the railway -1874 R.A. Davis became Manitoba’s first real Premier -significant immigration (mostly English speaking Ontarians, Mennonites, Icelanders, and some French Canadians) in the 1870s -after 1878 election, John Norquay became Premier (nominally a Conservative) -two main issues: -boundary disputes with Ontario -railway negotiations -by the 1888 election, party labels were still not established (although Thomas Greenway was considered a Liberal) -the English Protestants constituted a clear-cut majority at this point -they sought a makeover of the province -to build Manitoba in the image of Ontario -this brought the issue of bilingualism and separate schools to the forefront -these became the principle issues for Manitoba from 1890-1960s -1890 Manitoba abolished the use of French in the legislature and in the courts -also dismantled the separate school system -both things were established in the Manitoba Act -however the Manitoban courts upheld the decision to eliminate French -SCC ruled in favor of the Manitoba Act -but the British Privy Council upheld the Manitoban government’s decision to abolish French -Mackenzie Bowl (Conservative) ordered the government (under Greenway) to support separate schools -Greenway refused and won the 18** provincial election -Prime Minister Laurier argued that education was a provincial matter -Greenway-Laurier compromise:
-in 1899 the Conservatives were elected -Hugh John Macdonald (son of Sir John A Macdonald) -the Premier passed to Robman *** and lasted for 15 years of great economic and demographic growth -the Liberals became a threat by 1914 and under TC Norris they took the province in 1915 -the Winnipeg General Strike 1919 -the First World War increased the ranks of the labour movement -the Liberals were perceived as too urbanized and contained ‘too many lawyers’ -by 1922, the United Farmers of Manitoba were able to defeat the Liberals -they won 28 seats, with the Liberals elected 9, Conservative 7, and Labour 6 -John Bracken assumed the Premiership from 1922-1943 (the party didn’t really have a leader during the election) -by 1927, the UFM ran under the label of the Progressive Party -in 1928, Bracken created a formal entente with the Liberals, resulting in another successful election -during the depression, there was an excuse for greater economic restraint by the government -this is what Bracken implemented (greater restrictions) -Bracken continued to maintain the various coalitions to maintain power -in 1936, the coalition with the Liberal/Progressive won a narrow majority -Stuart Garson (chief Lieutenant to Bracken) won the 1945 election (with another coalition) -1948 Douglas Campbell became Premier (Coalition of Liberals/Conservatives won the 1949 election) -by 1950, the Conservatives withdrew from the coalition and displaced the CCF as the official opposition -some Tories converted to “Liberal Progressives” which caused confusion -Conservatives placed second to Campbell’s Liberal Progressives in the 1953 election -Duff ROblam (grandson of Roblan Roblam) challended the party leadership fo Progressive Conservatives
Provincial Profiles: Ontario
-almost everything has to have the support of Ontario -36% of the nation’s population resides in Ontario
-Ontario began to assume its contemporary form with the arrival of thousands of Loyalists in the 1780s -these immigrants demanded the political institutions which they had been accustomed to (Britain) -1791 Constitution Act divided the colonies into Upper and Lower Canada -also gave rise to the Tories and Reformers -Tories associated with economic elite -1837 rebellion in Upper Canada led by William Lyon Mackenzie -to resolve this crisis, Britain joined Quebec in the Act of Union in 1841 and established responsible government -the reform movement split into: -Clear Grits: -More democratic reform -Dorch Brown was leader -Moderate Reformers -John Sandfield Macdonald -John A Macdonald was inspiration of the Tories -Ontarios first post-confederation government was a coalition of … led by John Sandfield Macdonald -education bill was the foremost accomplishment -Sanfield Macdonald was defeated in 1871 and set the stage for Liberal rule under Edward Blake and then Oliver Mowet…for 24 years -Mowet’s long tenure was attributed to his ability to maintain a balance between the various interests within the province -pragmatism characterized Mowet’s government -“a model of conservative reform” -when Mowet left, the Ontario Liberals began their decent (although they lasted for another 9 years) -manufacturing condition -all pine timber cut on Crown land would be sown into lumber in Canada before being exported
-1905 Consevrative James Whitney was elected -father of “progressive conservatism” -praised with introduction of Ontario Hydro (although most praise goes to Adam Beck) -he confronted major problems -regulation 17 -restricted the use of French as a language of instruction for the first two years of school…and only then to districts with sufficient demand -a response to public opinion -later relaxed to students beyond grade 2 if they could not understand English -Whitney thought he was helping Franco-Ontarians adjust to an English speaking province -Whitney enjoyed victories from 1905-1914 -succeeded by William Hurst -served during WWI -prohibition -franchisment of women -served a full 5yr term until 1919 when the UFO party (United Farmers of Ontario) -formed in 1914 and grew between 1917-1919 -the party’s success was attributable to the agricultural concerns in rural Ontario with reductions in the rural population -also a moral decay that was perceived in the province -also exempted farmers sons from conscription in WWI -formed a coalition with the Independent Labour Party in 1917 which also felt that their needs weren’t being met by the traditional parties -the aftermath of WWI and conscription crisis produced the feeling that the traditional parties are not working (usually lasts for 5-10 years)
-the 1923 election produced a Conservative victory under Howard Ferguson -regulation 17 was repealed -sustained economic development -railway and highway expansion (in northern and rural areas of the province) -also played a role in gerrymandering the ridings in favor of his party
-George Henry succeeded Ferguson (assumed power during the great depression) -there were three dominant issues: -liquor prohibition -religious -hydro electricity -Roman Catholics were demanding corporate and separate taxes to help fund separate schools -the Conservatives were challenged by Liberals Mitch Hepburn
-Hepburn took majority of the seats in 1934 -not remembered fondly -his handling of GM strike in Oshawa was poor -he thwarted the advance of unionism and the emergence of the CIO (American Congress of …) -sent in police officers -1937 election campaign was fought around this issue -he won, despite this issue but his party was damaged -during WWII he had ongoing conflicts with Mackenzie King’s government -strained the federal-provincial relationship -this hurt the provincial party more than it hurt the federal party
-Liberals were defeated in 1943 -surprising rise of CCF/NDP -took 34 seats -the Conservatives took 38 seats -the Liberals took 16 seats -George Drew was the new Conservative leader -anti-labour -anti-French -anti-Catholic -Drew changed the name of the provincial conservatives to the Progressive Conservatives -he also introduced a 22 point program -a “radically moderate” program -emphasized economic and social security, advance labour laws, mothers allowances, old age pensions -with the strength of CCF presence, Drew’s minority government called an election in 1945 and took a majority of the province’s ridings (66 seats) and 44% of popular vote -1945 election -despite the CCF being the best organized ever, they were accused of being communist and they were damaged from this criticism
-from 1943-1985 the Conservative party held power for 42 years -most of the reform occurred in the 1960s -redistribution of ridings (10 new seats) -new minimum wage legislation -substantial increase in university grants -additional financial assistance to separate schools -there was not one dominant event during this period -Bill Davis ruled for 14 years of these 42 years -the government’s record and popularity of the party tended to be greater than that of the leaders’ themselves -John Robart became a central figure during the unity period -in the 1960s, the competition for the opposition comes from Liberal and NDP -the Conservatives had support ride and drop (but not significantly enough to take them from government) -in the late 1970s, bilingualism comes back as a major issue -Bill Davis translated statutes into French -because of the multicultural makeup of the province, other programs were also made available in French
Provincial Profiles: Nova Scotia
-Nova Scotia was a colony before confederation (had a system of responsible government before confederation) -1867 there was a lot of debate/conflict/discussion over Nova Scotia joining confederation -Conservatives were in favor of Confederation -the Liberals were opposed -Nova Scotia’s didn’t get to vote on a referendum on Canada, but they voted an anti-confederation party in 1867 (after union already occurred…so it didn’t change the terms of union) -1882-1925 was a period of Liberal provincial power -Jospeh Howe (preconfederation premier of Nova Scotia) fought for better conditions for Nova Scotia -he was put in federal Cabinet by Macdonald -1948 campaign, the Liberals campaigned “all is well with Angus Wells” -the Conservatives didn’t do well in the provincial election (led by Robert Stanfield) -1956 the Conservatives won the provincial election -paving roads was a strong Tory platform (local dimension of provincial politics) -he extended French language education to the end of grade 12 -he paved the way for medicare -under the Diefenbaker regime, provincial grants were increased…and when Pearson became PM, Stanfield fought for more money from the federal government -by 1967, Stanfield had led the conservatives to four consecutive victories -much of this was attributed to his personality -by 1970, Stanfield has moved on to federal Conservative leadership -he contested against Trudeau, and wasn’t successful -Gerald Reghan formed the next Liberal government with 2 NDP seats -but a pair of byelections allowed Reghana to form a majority for 4 years -energy was an issue -mostly for foreign exported oil (expensive) -Reghan envisioned a single public power system in the province -he created the Nova Scotia Power Commission -electricity costs rose substantially thereafter (this hurt their popularity) -economic recession hit (high unemployment, poor wages) -Conservatives elected a new leader in 1971 (John Buchanan) who set out to rebuild the party -despite losing the 1974 election, he continued to rebuild -by 1978 the people gave Buchanan an opportunity to govern -he offered to freeze power rates -1981 election, the Liberals sunk to their lowest rate ever…NDP increased its popular vote -Buchanan was successful in the first part of his mandate -negotiated an offshore development deal -secured the maximum federal aid to the provinces through transfer payments -the federal Liberals were in power federally, and didn’t help Nova Scotia by moving the naval reserve from Halifax to Quebec City -Buchanan managed to hold on to power because the Liberals were stricken with scandal -1984 the Conservatives won 42 seats (51% of the popular vote) -the conservatives eventually faced their own series of scandals -political ministers abused their powers -Buchanan decided to wait until late 1988 for an election, to let the scandal cool off -the Conservatives retained a reduced majority (but it wasn’t easy)…this win was on the basis of Buchanan’s popularity -after the election, the reduced fishery became a major issue…as well as economy -the federal government introduced restrictions on the number of catches allowed for fish…and a strong Canadian dollar hurt exports
-early 1990s witnessed the collapse of the Buchanan Conservatives -Liberals were elected despite their leadership crisis -Liberals took 40/52 seats (49% of popular vote) -1993, the new Liberal leader was John Savage
that’s all for Nova Scotia…on to New Brunswick
Provincial Profile: New Brunswick
-political parties were slow to develop into their modern/disciplined form -from 1867-1967, there were 8 different regimes identified -longest period of government being 1883-1908 of Liberal rule (25 years) -the early period was NOT a modern two party system because of weak party discipline -there were often coalitions of Liberals/Conservatives -an anti-confederation government was elected in 1865 -but with the support of the British government and support of Upper Canada, the confederation forces continued the struggle -in 1866 an election was called, where the supporters of confederation were assisted by provincial financial problems -New Brunswick became one of the original 4 members of confederation -the issue of confederation never came up again -separate schools became an issue after confederation -66-70% of the population is English speaking -Common Schools Act 1871 created a single school system and prohibited religious school instruction -became the main focus of 1871 election (divided Acadians/Anglophones from Catholics) -to help resolve this issue, two Roman Catholics were added to the Cabinet
As with all political fates, a fair degree of success can only be counted on through luck. If this is the case, R.B. Bennett was the most unfortunate prime minister in Canadian history and one of the most negatively portrayed by historians. By evaluating various historical perspectives on R.B. Bennett and his administration’s treatment of Western Canada during the Great Depression, this essay will accomplish four objectives. First, it will outline various divergent histories of Bennett’s personality and his perceived ineptitude in public life. Second, it will discuss the plight of the West and examine their relationship to Bennett’s administrative responses. Third, this essay will demonstrate the failures of Bennett from the perspective of many historians and discuss why Bennett is possibly the worst prime minister in Canadian history. Finally, it will conclude that Bennett is misrepresented historically and is more a sacrificial lamb than an inept failure in Canadian political history.
Of Canada’s Western prime ministers, none have received a more pejorative historical telling than Richard Bedford Bennett, the Conservative Member of Parliament from Calgary, Alberta. On his development in historical sketches, the general consensus describes R.B. Bennett as being born in 1870, the child of a resolute and passionate Methodist New Brunswick mother. Historians emphasize that he was fatherless in his youth, developing a strong work ethic due to his Methodist upbringing, which would later shape his political destiny. Historian P.B. Waite highlights Bennett’s career as a teacher who, through the mentorship of Max Aitken (Lord Beaverbrook), became a millionaire lawyer and a representative of Calgary in both the North-West Territorial legislature and provincial legislature of Alberta. Consequently, R.B. Bennett “thought of himself as Calgarian. It was his home; it was where he had made his way in the world” (Waite, 54). Some historians tend not to labour over this fact, probably because of subsequent conflict between Bennett and the West, but it can be argued that his perspective on politics was initially guided by his experiences in Western Canadian culture.
Another interesting pattern of historiography is the description of Bennett’s personality which is often less than complementary. His faulting political ambition receives criticism often directed on his lack of personality and business-like mantra. In numerous sources, including P.B. Waite’s Three Sketches of the Personal Life and Ideas of R.B. Bennett 1870-1947, Bennett is described as an egotistical, selfish, shy and lonely bachelor incapable of compassion, who was capable of violent rudeness when called upon. These historians are merely exaggerating a point to demonize his political performance given their hindsight into the depression years. Desmond Morton’s description is more moderate stating that Bennett “was a big, plump man with a booming voice, a domineering manner, and a capacity for generosity that he kept utterly secret” (Morton, 212). Clearly, Bennett was not the most personable of politicians. Even a biased conservative biography by Andrew D. Maclean states that “unlike most great men, Mr. Bennett [was] quick to find the weak points in character or ability and permits that knowledge to override any other qualification a man may have” (Maclean, 104). Fortunately for Bennett, in electoral politics, these attributes were not as pressing as oratorical skill and hence he could succeed based on his provocative speeches. Despite the consistent character assassinations of Bennett, as stated previously, historians are more likely skewed by their perspective on Bennett’s leadership of Canada, in relation to the West, to which this essay will now turn.
The Great Depression of the 1930s transformed unemployment into the single most challenging threat to laissez faire capitalism. Canada has a seasonal agrarian economy and with the onset of winter, farming activity ground to a halt not to resume until after a long circle of bitter winter months. According to Struthers, “until the development of the Canadian West as a major wheat-producing region between 1896 and 1930, few economic links existed to bind the diverse regions of Canada together” (Struthers, 5). The Canadian West was so vast that standards of livings had varied widely between it and other Canadians regions. Throughout the 1920s, the urbanization process continued across Canada while in the West, farming expansion also continued unabated. The Palliser Triangle represented potential prosperity for impoverished European families. Despite the economic imperialism of the east and several minor depressions, their desire for self-sustaining autonomy could be realized.
Some historians conclude that because of the unique spatial dimensions of this agricultural landscape, the Great Depression hit Western Canada hardest. Caught in unprecedented catastrophe, two events culminated in the crippling of that Western prosperity. One was the global phenomenon triggered by the stock market crash of October 1929. The result locally was that the price of wheat fell 40 per cent, where as the price index for flour which fell only 20 percent (Varty Lecture: March 1st). This disproportionate transfer of the farmers’ relative wealth to eastern millers exacerbated the plight of Western Canada and aided the rise of socialist ideals. The second event was that a ‘Dust Bowl’ had replaced the euphoria and optimism in the West. Environmental drought caused by change in wind interactions between the Gulf of Mexico and Pacific streams, and imprudent cultivation practices, localized in Western Canada, meant that the soil could literally blow away (Varty Lecture: March 1st). Conclusively, of the spatial contingencies in Canada “the plight of farmer in western Canada was rather worse. Canada’s backbone, the prairies, was broken, not by the depression alone, but by depression and drought” (Watkins, 181).
Enter the Western political leader R.B. Bennett with whom historians diverge in their discussion of the degree of his success or failure after rising to the post of Prime Minister. Some historians, like Morton, are quick to defend him given the historical context. However, others like Struthers argue Bennett could have avoided some of the errors of his administration. To begin, with the 1930 election, unemployment proved to be decisive in the election campaign. On the campaign trail, historians Struthers and Morton assert the notion that Mackenzie King felt “quite removed form the economic calamity that was beginning to preoccupy Canadians” (Morton, 211) while R.B. Bennett’s campaign “was seeking to make unemployment the issue” (Struthers, 45). Ultimately, most of the unemployment was confined to the drought stricken western provinces as a result of a poor wheat crop and so King’s electoral strategy was to deflect responsibility onto western provincial jurisdiction under section 92 of the BNA Act. Like many business-owners, Matthew Elliott, my great grandfather, a pharmacist in Milestone, Saskatchewan voted for the pro-business candidate of Bennett’s party. Promising action, Bennett emerged victorious with an enthusiasm that would quickly fade given the deepening drought and poverty of his local constituency and the global economic collapse from which a small helpless nation could neither avoid nor rebound from alone. The general consensus between historians is that, with historical hindsight, it was fortunate for the Liberals to have lost given the impending disaster of the 1930s.
R.B. Bennett’s new mandate as the government hinged on his solution to the unemployment crisis which was looming over Canada. Unfortunately, the western drought proved to be a serious liability for Bennett’s prosperity plan and his pro-business, anti-interventionist inclinations provided little relief to the millions of unemployed who were become increasingly desperate and agitated. According to Struthers, “the Tory leader was convinced that the present depression was a passing, mostly seasonal phenomenon” (Struthers, 48). He was patently wrong. To be fair, it was implicit, in the historical assertions of Thompson and Seager in Canada 1922-1939: Decades of Discord, that the political culture of the time did not believe the crisis would last for much longer. This position is expanded by Dough Owram, who points of that “the world was forced to operate in ruthless competition which creates maldistribution of wealth and ‘gives rise to the violent fluctuations in the purchasing power of consumers” (Owram, 219). Bennett, therefore, acted on short-term policy implementation rather than a long-term initiative that may not have produced anything profoundly helpful. As a consequence, R.B. Bennett “who was [posturing] a radical change in government policy to ensure prosperity” (Berton, 47) merely implemented minor relief plans that did not engage the federal government heavily in provincial jurisdiction. Bennett established the 1930 Relief Act, which relied on municipal and provincial funding for implementation at 50 percent and 25 percent respectively. Unfortunately, “Bennett had no way of ensuring that the money was fairly and wisely spent” (Struthers, 50) and there was a general lack of finances on those levels of government. In addition, Richard Wilbur’s analysis of the Bennett administration argues that unemployment was unequally distributed between municipalities adding to the failure of the Act. Struthers aptly points this out as an early debacle in the administration’s plan.
By 1931, Bennett governed under the Statute of Westminster but such monumental achievements are overshadowed by the economic situation, which was still gradually deteriorating along with similar democracies but more significantly due to the devastation of the prairie wheat crisis shared only by the American west (Wilbur, 7). With the wheat economy bust, 54 per cent of the nation’s population worked in towns and cities, and urban issues like old-age pensions were the most pressing issues of the day (Struthers, 47). Desperation was apparent as my grandmother recalls ‘hobo train-hoppers’ begging her father for food on several occasions in the summer months. According to Struthers, transients provided the battleground for the crisis. Bennett strongly believed that the urbanization of transients was a pejorative movement and was characterized as having “lived in terror that peace, order, and government would be disrupted by a Soviet-style revolution” (Berton, 141). His fear of transients and the idea of single men in bustling civic communities was counter-intuitive to his conservative values, threatened a Communist-revolt striking at the heart to his religious adherence to simple purity of rural life. Bennett believed that the people should be forced ‘back to the land’ (Struthers, 92). He rejected state intervention as long as feasibly possible.
After the collapse of Bennett’s unemployment relief effort in the spring of 1932, he commissioned the infamous social worker Charlotte Whitton to write a two-hundred-page report on the Western crisis that was the expanding liability on his government. Several historians including Berton and Struthers point to her as a figure of western betrayal for what appears to be self-aggrandizement of the profession of social workers. Well documented by Struthers, Seager and Berton, as the direction of the Canadian Council on Child Welfare, Whitton was “eager to discredit relief administrators” (Seager, 253) and replace them with qualified social workers. The most astonishing revelation, however, was Whitton’s argument that almost “40 percent of those then receiving relief in the West did not really see it…” adding that “…the plight of the people was pitiful but it was ‘not one deriving from the present emergency’ and therefore should not be supported by federal relief” (Struthers, 77). The 100,000 transients in the west, she warned Bennett, were “getting out of hand” (Berton, 136) and called for more social workers like her for the relief effort. This only served to confirm, in Bennett’s conservative mind, that the distinction between lazy and desperate unemployed was distorted and that there was widespread abuse in the relief system, as according to Struthers.
In January 1933, Bennett added to his administrative blunders when the provincial leaders asked that the federal government be entirely financially responsible for direct relief. Bennett’s response failed to mitigate deep resentment from western premiers, like Pattulo of BC and Gardiner of Saskatchewan, when he attacked them for fiscal ‘extravagance’ and suggested that “the Prairie Provinces give up old age pensions, telephones, and electrical service to ‘maintain the financial integrity of the nation’” (Seager, 254). The fiscal concerns of Bennett were calling for the burdensome western provinces to deliver balanced budgets. Ultimately, Bennett had to pick up the slack of their supposed incompetence and yet this is not apparent in Seager’s view. Having ignored the finer points of Whitton’s solution, Bennett established a direct relief method for the transients beyond the creation of paved roads that characterized his previous Relief Acts.
Curiously among the historical perspectives, Bennett’s achievement such as the beginning of the St. Lawrence Seaway project, the establishment of the CBC and Bank of Canada go underemphasized in most accounts. In the place of the significance of those accomplishements is Army General Andrew McNaughton’s proposed scheme called PC 2248. “By taking the men out of the conditions of misery in the cities and giving them a reasonable standard of living and comfort,” McNaughton explained persuasively, “…the government would be ‘removing the active elements on which ‘Red’ agitator could play’ (Seager, 268). With the plan underway, the RCMP began removing transients from the trains in Western Canada and relocating them in work camps outside of urban centres. According to Struthers, “the Department of National Defence (DND) relief camps represent one of the most tragic and puzzling episodes of the Depression in Canada” (Struthers, 95) and would be Bennett’s greatest plunder.
By 1935, there were more than two hundred camps in the system serving mostly Western Canada. Regardless of the historian’s political leanings, their description and analysis of these camps is resoundingly negative. According to Wilbury’s account, those on relief were “inmates of the government labor camps” (Wilbury, 17) casting a grim light on Bennett’s failed solution which may have exacerbated the problem. Unfortunately for Bennett, the military styled DND camps would be referred to as ‘slave camps’ that “symbolized everything wrong with Bennett’s approach to the depression and eventually provoked the most violent episode of the decade” (Struthers, 96). Struthers is referring to the scathing actions of Bennett in regard to the Regina Riot.
The On-to-Ottawa Trek was a protest from BC headed to Ottawa and had been “violently broken up two thousand miles from its goal” (Seager, 272). 120 people were arrested at the July 1st, 1935 Regina Riot which ended a police officer’s life. Pierre Berton asserts that Bennett instructed the RCMP in Saskatchewan in order to hold the protests in Regina pursuant of Section 98 of the Criminal Code (Berton, 323). According to Berton, Bennett’s fear of violent revolution provoked violent acts as “Colonel Wood was under repeated pressure from Ottawa to arrest the leadership of the trek” (Berton, 326). Other than the Winnipeg General Strike of 1919, the Regina Riot of July 1, 1935, is probably one of the larger civil disturbances in Canada history. Highly critical of Bennett’s ineffectual leadership, Struthers adds that the riot was a “fitting conclusion to Bennett’s five years in office for it symbolized the failure of the unemployment polices pursued by his administration” (Struthers, 136).
With the unavoidable crisis in Western Canada, the defection of H.H. Stevens in 1934, the formation of the Reconstruction Party and the sardonic emergence of ‘Bennett Buggies’, Bennett’s credibility began to wear thin. It did not help that Bennett was a millionaire businessman of the most bourgeois ‘breeding’. In addition, Bennett’s altercations with the newspapers “fueled the image of an unkind bitter man” (Berton, 101) and the Tim Buck fiasco over a Communist member convicted under Section 98 of the Criminal Code would be overturned later leaving Buck a hero and Bennett’s administration a villain beyond repute. Ultimately, he could not solve the problems of the depression but would make one last attempt at redemption in 1935.
The last stand for Bennett was the CBC public radio announcements in early 1935 which attempted to serve the purpose of bringing hope to the people. There is strong criticism that it took far too long in the term for Bennett to make his ‘New Deal’. With the hindsight of historians, such criticism is to be expected, however, one must take into account that the welfare state was something alien to Bennett’s time. For Wilbury, Bennett’s New Deal was an imitation of the original Roosevelt response to the depression. Struthers concurs looking to England stating that “in sum, Bennett’s bill was a cautious, conservative document which closely resembled the original British legislations” (Struthers, 124). Overall, Bennett’s radio announcements were skeptically received by some historians. Both Roosevelt and Bennett pledged for interventionist policies in order to save capitalism in North America (Seager, 263). For Bennett is was too little too late. King played the strategy of supporting the ‘New Deal’ based on the merits of the proposal instead of allowing Bennett to use the bill as an election promised that squandered by Liberal opportunism. Bennett was put out of action over illness. In comparing King and Bennett, historian Pierre Berton points out that the “two were miles apart in personality and political savvy” (343, Berton). For Berton, King was a politician; Bennett was not. King made no promises during the election campaign and won. The Regina Riot and the ‘slave camps’ contributed to his undoing. Other successes like providing for an eight-hour day, a six-day work week, and a federal minimum wage (Seager, 264) are hardly observed in historical recollections or are deeply undervalued as achievements of Bennett.
The result of Bennett’s failure was that the Western electorate gave up ordinary political parties for the CCF and Social Credit. New leaders gained support by promising to help struggling constituents and to stand up to Ottawa. Unable to overcome the Depression, Bennett lost the 1935 election to his Liberal opponent, Mackenzie King. His larger failings were in the dealing of specifics in the Great Depression, particularly federal-provincial relations with the four western provinces, the DND camps and the Regina Riot. The massive majority gained by King is more telling of the single member district electoral system than Bennett’s failures. How much of the depression is truly Bennett’s fault is impossible to gage and historians seem to debate over the depth of his ineptitude rather than the successes he achieved. The 1935 election sealed Bennett’s fate as a failed leader, but this is only one side of a complex diverging understanding of Bennett and his accomplishments under the most dire of circumstances. While various writers describe to a degree the details of R.B. Bennett’s political strategy during the depression, they vary on the emphasis of his success or failure.
At once a man of decidedly ill repute and a statesman often-misunderstood, R.B. Bennett did the best he knew how. Bennett receives a negative historical analysis because Canadian historians have changed their social perspective of how Canada should be. Unfortunately, Bennett’s philosophies were the antithesis of the welfare state; few can argue that Bennett was successful in his laissez faire policies. Hypothetically, if Bennett had been reelected, a counter-factual analysis would reveal that the political capital economic upturn caused by World War II would have over shadowed his perceived ineptitude during the depression. King and the Liberal Party were the beneficiaries of Bennett’s failure. In this way, Bennett was Canadian history’s most sacrificial prime minister.
Work Cited
Berton, Pierre. The Great Depression 1929-1939. Toronto: McClelland and Steward Inc,
1990.
Morton, Desmond. A Short History of Canada: Fifth Edition. Toronto: McClelland &
Stewart Ltd, 2001.
Orwam, Doug. The Government Generation: Canadian Intellectuals and the State: 1990-
1945. Toronto: University of Toronto, 1986.
Seager, Allan and Thompson, Herd John. Canada 1922-1939: Decades of Discord, the
Canadian Centenary Series. Toronto: McClelland & Steward Ltd, 1985.
Struthers, James. No Fault of Their Own: Unemployment and Canadian Welfare State:
1914-1941. Toronto: University of Toronto Press, 1983.
Maclean, D. Andrew. R.B. Bennett: The Prime Minister of Canada. Toronto: Excelsior
Publishing Company, Ltd, 1934.
Waite, P.B. The Loner: Three Sketched of the Personal Life and Ideas of R.B. Bennett
1870-1947. Toronto: University of Toronto Press, 1992.