Based on Beeple’s artwork, modified by Professor Nerdster, free to distribute:-)
The short-summary is:
It’s the transition, stupid!
More detail:
Capitalism must solve the climate crisis, obviously, according to Carney. In this chapter, Carney is making a push to show how ESG ought to be used which aligns with his Glasgow COP26 work. This chapter is very much advocacy as he is the special envoy to the UN on climate finance.
The Rise and Rise of ESG
Carney lays out the trajectory for ESG. Just as GAAP (in the wake of crash of 1929) and as IFRS (following the 2008 credit crisis) imposed new standards in accounting, we now see increased pressure for companies to set out their sustainable development goals. Carney identifies a key challenge however, that there is a wide variety in methodologies in environmental, social and governance (ESG) and subjectivity is more prominent then in absolutes typical in accounting. Noting of course that accounting, too is subject to managerial influence. Hence, to shore up standardization, Carney is working on Glasgow COP26 ie. re-assert global standards for ESG. Glasgow COP26 is the next global conference, Paris 2015 was the last major conference. For Carney, the providers of capital such as pensions, banks and insurers will increasingly need more transparency, stipulate their investment horizons and clarify where they sit on the continuum of maximizing value for shareholders versus doing the same for stakeholders (who as stakeholders provide a positive feedback loop back to increased shareholder value in many instances anyway, according to Carney).
The Rise of ESG Historically:
It started with SRI (Socially Responsible Investing) in the 1960s. SRI screened for tobacco companies and apartheid in South Africa. ESG has broadened considerations:
Environmental Impacts
Climate change and Greenhouse Gas emissions
Air and water pollution
Biodiversity
Deforestation
Water scarcity
Waste management
Energy efficiency
Social Contributions
Customer satisfaction
Labour standards
Data protection and privacy
Human rights
Gender and diversity
Community Relations
Employee engagement
Governance and Management
Board composition
Whistleblower schemes
Audit committee structure
Political contributions
Bribery and corruption
Executive compensation
Lobbying
Hortense Bioy
The Surge of Interest in Separating the Good Motives from Bad Execution
Modern ESG involves analyzing and investing in purpose-driven companies. In short, ESG is about having credible strategies while avoiding those that are part of the problem (gambling, firearms, deforestation, tobacco, fossil fuels) but also supporting “bad” companies and industries that are actually part of the solution, not just green washing (fronting that they care). Sustainably managed assets totaled $30 trillion at the start of 2018 and is now already at $100 trillion in 2020 according to Morningstar’s Hortense Bioy in August 2020. In addition, the UN’s Principal for Responsible Invest (PRI) have now been more widely supported which mandated ejecting member who don’t follow ESG principles. So there are now more serious consequences for green washing / fronting that they care.
How ESG can Guide Stakeholder Value Creation
a massive amount of ink in this chapter is dedicated to the technical deployment of a more rigorous version of ESG. The details are as follows:
Carney insists on looking at finance first impact investing, that is to say, “seeking to do well by doing good” (Value(s), 421) using ESG criteria to identify common factors that assist risk management and value creation BUT ALSO delivering superior financial returns;
‘Do well by doing good’ is about positive social or environmental benefits AND accretive financial returns;
With mandatory pensions, you can’t ‘vote with your feet’ but beneficiaries on socially responsible resolutions are possible;
As the CFA (charter financial analyst exams) trains you to identify a client’s risk appetite, it should also train you to prioritize non-financial appetites ie. ESG; Again, think John Kay, who says that the purpose of living is not to breath anymore then the purpose of business is to make a profit. Breathing and profits are necessary but not the purpose…;
Carney supports attempts to evaluate wooly environmental and social outcomes as rigorously as financial returns;
As such, Carney points to the Impact Management Project’s approach as detailed here
·(From the Impact Investing Institute)
· Carney advocates a broad alignment between stakeholders and shareholders which occurs when purpose and competitive advantage of a company both depend on achieving a specific social or environmental value which Carney calls “Shared Value”;
Trade-Off versus Divine Coincidence
Some will trade a degree of financial returns to gain greater social returns while other seek divine coincidence which is what Carney is more interested in exploring in this chapter. Divine coincidence is a central bank / new Keynesian terms that suggests there is zero-tradeoff between stabilization of inflation and the stabilization of the welfare output gap. Divine coincidence approach of environmental outcomes and accretive returns that increase together. But what Carney is referring to regarding divine coincidence is more likely that doing well on ESG just so happens to mean doing well in terms of financial performance for factors obvious as well as less tangible (hard to draw causal links given complexity). Said another way, Carney’s thesis is that stakeholder values have a feedback loop that fuels the maximization of shareholder values. Carney wants explicitly calculated, reported and tracked social and environmental goods to be embedded in financial reporting…and its finally starting to happen through various international bodies: TCFD, FSB, Glasgow COP26, IFRS…..
Why ESG is so Lucrative or At Least Will Be…
Carney’s big persuasion push in this chapter is that purpose-driven companies tend to score on ESG metrics and also tend to outperform those that do not score well on ESG. Why? Possible explanations have to consider:
Superior management = superior ESG adherence = superior financial returns. Some ESG factors are more helpful financially than other ESG factors, the ones that are short-term could be overweighted and thus deliver shareholder value sooner, for example Wal-Mart has a logistics competency at its core and their carbon footprint is reduced which would align with divine coincidence;
Some ESG factors are more long-term. Some ESG factors are indirect contributors of competitiveness such as brand, social license which improve a company’s ability to attract and retain talent. For example, opposite to Wal-Mart, a company that protects endangered species but receives no direct reward might receive more or better job applicants as is the case with Patagonia for example;
The prospect of strong cashflows could explain why a ESG company trade at a premium in the case of Wal-Mart (controlling for other factors which is difficult empirically) and on social license in the case of Tesla (i.e investors and institutions bias towards cashflow metrics, managing what they can measure as Peter Drucker famously points out but social media darlings and rocket launches play into an aspiration mix that communicates both “it’s the transition, stupid!” and stock momentum)
Carney admits that ESG performance will not automatically translate into higher cash flows and that society’s values should not be determined exclusively by whether the stock market gives a company credit for helping achieve those ESG goals.
Somethings…money can’t buy but companies have massive impacts such as species loss or inequality according to Carney. The value in those cannot be captured by the firm and thus not translated into the price of the company.
As Albert Einstein said “not everything that counts can be counted, and not everything that can be counted counts.” Carney notes that there is are a lot of different methodologies to decide what should count, and determine what society believes should be counted…..
Performance….Further Arguments for ESG
Sustainable investment strategies (divine coincidence) outperform traditional strategies, according to Carney. He points to a study by Causeway Capital’s Mozaffar Khan, George Serafeim of Harvard and Aason Yoon of Northwestern University which shows that activities that enforce better and material social and environmental value get you ‘Alpha’ ie outperformance relative to the market median of 3 to 6 percent annually.
Again, Carney references Divine Coincidence here. The researchers found that this may be a function of the positive ESG sentiment such as public sentiment momentum (ie. Tesla is the top example).
Public sentiment influences the value of corporate sustainability activities therefore the price paid for corporate sustainability and the investment returns of portfolios that consider ESG data is boosted by those sentiments.
Again, Carney acknowledges that ESG does not equal Alpha automatically. The formulaic application of ESG ratings or kitemarks are not enough. Also, that as more firms use ESG… “if ESG mainstreams, then overall market performance, risk-adjusted returns, should improve, but relative performance will not.” (Value(s), 427)
Broad societal improvements to workforce diversity and inclusion across the board won’t differentiate specific companies that have helped make it happen, except during the transition to a more equal and inclusive society. “These shifts will create ‘social alpha’ , or what people would colloquially refer to as progress.” (Value(s), 427).
Fiduciary Duty
Carney is making an appeal here to the idea that CFA (chartered financial analysts turned portfolio managers) should really include calculations and inputs on ESG. Investors must weight ESG factors to fulfil their fiduciary duty to those whom the money is being managed. To do that investors need:
1) clear objectives of an investment…ie. that we knew the value that our capital is bringing in terms of ESG.
2) understanding the divine coincidence between stakeholder and shareholder value….i.e what’s good for the abstract other will have intangible benefits for the investor and the client.
Carney argues that investors must consider maximizing their client’s welfare not simply financial results…Recent polls show that owners of capital care more than simply about profit and want ESG to be a factor to some degree. 50% of those surveyed by FCDO (Foreign, Commonwealth & Development Office) were interested in sustainable investment today or in the future….33% were willing to accept LOWER returns if they knew their investment made a difference to something they cared about. In pensions, OTPP (Ontario Teacher’s Pension Plan) and UK cancer researches want to exclude things like children in cages, tobacco companies even if these firms are very profitable
Carney proposes changing the definition of what constitutes fiduciary duty.
Also notes the success of Make My Money Matter in the UK which aims to get individual investors to express their views.
FSB – TCFD
Effective in June, 2021, 1,500 firms with a market cap of $17 trillion are now reporting against TCFD (Task Force on Climate-related Financial Disclosure from the Financial Stability Board of the G20) which was launched only 3 years ago. How do we get this to be accretive is being researched and more people are moving into ESG roles to support that analysis.
The Investing Ecosystem for Stakeholder Value Creation
Carney is basically saying, we need climate disclosure. This investment ecosystem is rapidly developing, evolving and confusing according to Carney. Here are the main actors to explain what the information they need is:
Companies that receive investments and put it to work on green initiatives or social projects get a weighting;
Investors that provide that capital to those companies to support these activities, they can pursue investment strategies that are traditional or ones that systematically do take into account ESG facotrs;
Stakeholders including employees, suppliers, customers and communities are wanting more transparency;
Governments and regulators that oversee the system, set the rules and address the systemic consequences of actions that companies and investors take. It is a superior solution IF the consequences are independent of any single human actor’s will; if the consequences and punishment are autonomous and objective then those punished will not seek to punish the regulator themselves. This is particularly applicable to good parenting, autonomous punishment works much better.
Problems with Disclosure
Obviously, investors have different weighting on each ESG factor because they may care about different factors differently to others, I might like fire arms for example. Reducing exposure to tail risks and improving returns are part of solution, but companies may shift away from social license and resilience to systematic shocks as memories fade (think about how SARS memories faded in the run-up to Covid). We just don’t know when the next pandemic, climate Minsky-moment or decline in social license (catastrophic global war perhaps) will or might happen.
Carney is betting that the stakeholders are going to push investors over time as these ideas that Carney is espousing are mainstreamed.
Trying to understand if he’s late to the party: this has been tried. Companies don’t do this. Impact accounting and ESG needs to be more transparent in their investment goals.
ESG seems to be a differentiator…but there will be push-back.
Information and Disclosure:
IASB and FASB and securities regulators will likely oversee disclosures.
There is the IAS39 for valuation of financial instruments and the IAS9 for expected losses on loans.
But sustainability reporting has the following:
GRI (Global Reporting Initiative),
SASB (Sustainability Accounting Standards Board),
And as mentioned prior, the TCFD (https://www.fsb-tcfd.org/) the Task Force on Climate-Related Disclosures…is another group pushing for ESG disclosures as mandatory.
Social media to scientific analysis informs the view of public expectations…in the case of social media I hope not considering social media is not representative of public opinion.
There are competing interests per topic and opinion will vary over time but those opinions all should matter, according to Carney.
There has been a major attempt to consolidate by the big four (Deloitte, PwC, EY and KPMG) to develop a corporate reporting framework that has agreed standards with the GRI, SASB and TCFD metrics. The metrics are as follows:
1) Core metrics: 22 well-established metrics and reporting requirements, there are quantitative and obtained with some effort and time;
2) Expanded metrics: 34 metrics which are less well established which convey a wider supply chain scope. These metrics are more advanced ways of communicating sustainable value creation.
Impact Management Project (IMP): is building a framework on: What is already reflected in financial accounts (IASB);
§ Information material for enterprise value creation (SASB);
§ Information for sustainable development (GRI);
Integrated Reporting: developed in 2013 to explain the value creation incrementally of human, intellectual, manufacturer, social and natural capital.
The European Union has been leading on non-financial through something imaginatively called “Non-Financial Reporting Directive” (NFRD)
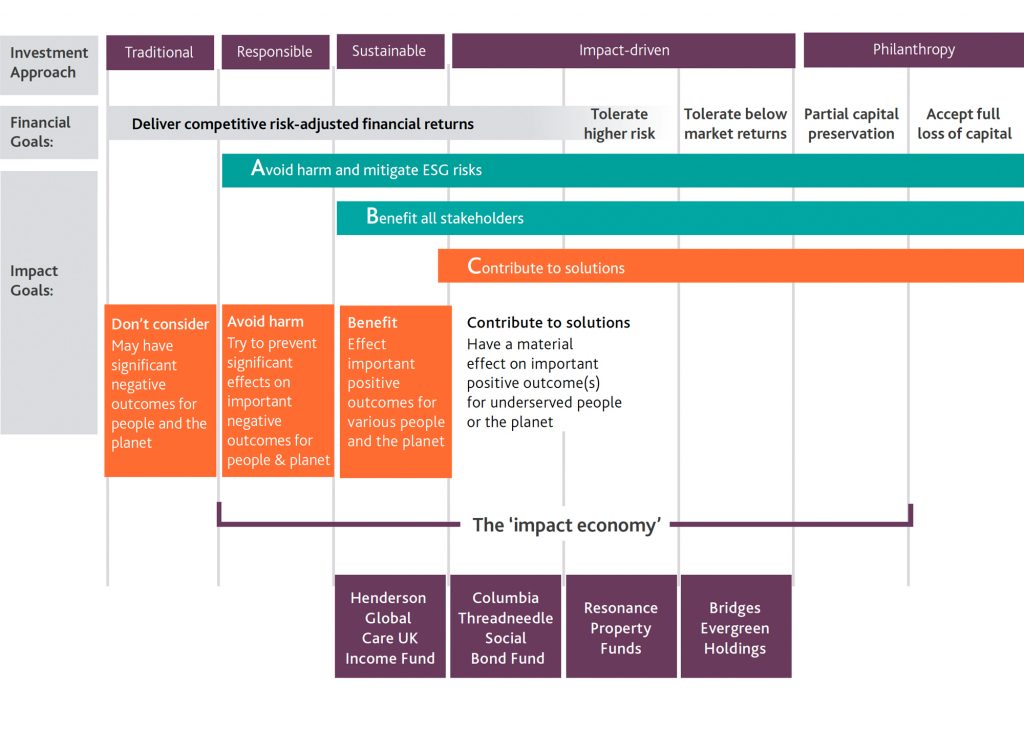
There are three major approaches to using ESG by investors
1. Ratings based Approach
2. Fundamental value where raw ESG data is analyzed in an integrated assessment;
Or
3. Impact assessments
[1] Ratings Based Approach
in this approach the investor outsources the assessments to ESG data providers how have their own methodologies for objective and subjective data and then create a comprehensive indices.
There is a lot of self-reporting and surveys can be gamed;
Ratings system data may vary and therefore data vendors will have wildly different scores;
The correlation between 6 different ESG rating companies was only 0.46 in other words only about half the time did they get close to the same rating;
The more profitable a firm the lower the ESG discrepancy so there is hope that energy and time can avoid inaccurate ESG reporting;
Governance metrics were the weakest at 0.19. In other words only about 1/5 of the time did the 6 different rating firms score similarly;
Disagreement are increasing in 2019. Berg, Koelbel and Rigobon showed that there are three primary drivers of difference in reporting: 1) measurement (what metrics are being used), 2) differences in scope (what attributes are being used), 3) weighting (the level of materiality the ratings vendor ascribes to a given attribute).
Different ESG outcomes mean ultimately different values.
Carney argues the rating approach is simply too subjective. It is not straightforward to value the outcomes that a given investor values. Improvements will come but ultimately, this is subjective.
Carney reiterates that sustained practice of a virtuous goal of value creation is essential.
[2] Fundamental Sustainable Value
in this approach, rather then ratings based approaches, investors have access to the raw tools. The data is usually publicly available data (social media, NGOs, company website, company filings) and then disseminated systematically. Examples are:
HIS Markit;
Refinitiv;
Bloomberg.
The end user determines the materiality. This approach is akin to fundamental analysis in the Equity Research field in which the expert is providing a final investment decision by analyzing company performance, building a financial model that provides a homebrewed answer to the company’s intrinsic value…..and then trading accordingly.
As part of fundamental sustainable value, there is a growing emphasis on Shared-Value. Shared-Value reinforces:
(1) creating innovative products that solve a social need,
(2) enhancing productivity in supply and value chains,
(3) investing to improve the industry cluster where the business is based…
Carney is supportive of this approach because of the complex changes and having someone at the wheel. However, companies are the leaders at conveying their ESG strategy and this is still going to lead to a lack of standardization. Carney admits that there is a significant risk that this is about branding over substance….
[3] Impact, Monetization and Value
This approach looks at the financial AND social contributions. They seek to measure social impact. This approach uses:
IFC Operating Principles,
Impact Management Project Dimensions of Impact,
And Global Impact Investing Network’s GIIN’s IRIS+ metrics,
1/3 of FTSE100 companies already do this IMV….
Impact monetization puts prices on the impacts. The calculations are sometimes easy like: how many solar panels sold minus production costs? While it’s social impact includes solar arrays installed in a house and the array is known to replace CO2 emissions by $17 therefore the monetary impact of this solar panel company is X. But some investors might place a higher value on CO2 creation averted or that the value factor of CO2 will rise which is a value judgement in and of itself. For example, Canada uses it’s carbon price path of $170CAD per ton….
The Serafiem/Cohen Impact Measurement Model asks that you compare the total environmental cost of 1,800 company. You could find 2 chemical companies with sales of $12B each but one created environmental damage of $17B and the other only $4B.
These are the same problems with having to calculate the value of Amazon.com and the actual Amazon. There are some many factors that aren’t measured.
Calculating the impact value of moving from fossil fuels to renewable power generation requires looking at the different estimates of the diminishing marginal utility of impact….
Ranges and sensitivity analysis are useful here but Carney warns that false precision could set in.
The danger in Impact, Monetization Analysis is that the analysts will become disconnected from the raw data and develop a sense of false precision that cannot be validated since it is subjectively derived.
Aggregating the nuance, it will basically create an obsession with that one number much like a stock price itself.
Securing Climate Impact
The Transition to Net Zero…Carney believes that the evidence points to a need to shift toward green solutions in order to prevent exceeding the 2 degrees Celcius consensus from the Paris agreement which will unleash a feedback loop that is irrevocable.
Since climate transition is an imperative of climate physics and chemistry, it’s obvious that this demand for change is going to go mainstream, therefore jump on the wagon. Engineers and politicians see it.
Companies are increasingly being as whether they are doing their part or whether they will be crushed and become “climate roadkill” (Value(s), 449).
25 countries already of a Net Zero plan….Carney believes that harnessing finance is critical to make this happen. Every financial decision- should take climate change into account in that decision-making.
There are ways to evaluate the providers of capital:
What percentage of companies we invest in have a net-zero transition plan in mind?
What percentage of the portfolio is net-zero aligned?
What percentage deviation from the target is a given company?
What degree of the portfolio is actually warming: how much emissions is this particular company generating? GPIF, AXA and Allianz volunteer this information
Carney works at Brookfields to try to create net-zero as an asset class….
Social Purposes of Investing:
William Blake “Know your values rather than be enslaved by those of another.” Carney concludes that we ought to measure if the impact is achieved! Carney does not believe that investor should able to put companies into ethical blind pools of ESG collateral….. Creating value for all means measuring that value. That is what this chapter has been about.
Ø Theory (8/10) versus practice (6/10). In theory, something works but in practice, operationally, that something might not work. Executives are interested in the next 2 to 5 years. As Tetlock showed in his master work Superforecasting, our predictions get very hazy past 5 years. Therefore, executives and others will continue to ignore climate physics in the short-run and point to correlative speculation when weather events are more and more extreme. It’s sad but true. Shareholders are wolves too! Carney does not address the counter-arguments sufficiently here.
Ø AMEE.co.uk in the 2000s and mid-2010s attempted to create a systematic ESG metric that is more than a value add but is mainstream, but then they pivoted to supply chain risk because of the greenwashing effect. Self reporting is one problem, there is the tacit consent challenge. The classic criticism of anyone who supports climate change initiatives is that their intentions are conspiratorial and self-interested at a proportion nearing 100%. I don’t think Mark Carney is looking to enrich himself because climate change is not in fact a serious threat, he may enrich himself somewhat because he is creating value by raising climate finance into the mainstream and it is the right thing to do.
Ø Carney says the investing ecosystem is rapidly evolving, but what is the massive sample size data on that? I’m not talking about a survey which is about as reliable as polling data about Donald Trump. “Yes of course I care about the environment!” Yes, this topic is trending because it aligns capital with solutions to climate change, but the financial sector still has a streak of strategic gambling and as such there will be a strong counter-argument / hedge against ESG as not that accretive after-all. Hard to predict the future but Carney is making an aspiration case, this is how it WILL play out which he’s betting will have a self-fulfilling impact. But as I have argued, I don’t think most people will be reading Value(s) in the way he entirely wants. It’s too lengthy, too academic and should be distilled further to connect with the audience, hence I have provided these summaries….
Ø Carney thinks the Edmonton Oilers have the greatest player in the world and that cognitive error matters because there is no I in team. And his prediction that the Oilers would go all the way to the Stanley Cup in 2020-21 was dashed in the first round by the Winnipeg Jets! Now, you could read into Carney’s enthusiasm that he a) loves the Oilers/ loyal to the team at a partisan level which is fine, b) places to much emphasis on heroes and individual leaders…it takes a village to achieve great things: you have to lead with good talent of course, but also good strategy, supporters and meeting people where they are at to move them into the light. I think Carney does tend to invite people into his ivory tower and then expect to totally persuade by telling people the way he sees the world (based on being well cited).
Ø Carney may be violating his principal that the four most dangerous words in the English language (actually five words) “this time it is different” in this chapter. With ESG, he’s saying “this time it is different”. Social license has been around and doesn’t figure that prominently in the MBA programs of the world, unfortunately. I support the aspiration but measurement is going to be your Achilles heel as well as what motivates financiers who are an exclusive group regardless of some democratization of stock trading in recent years. Few bankers will agree with John Kay that breathing is to living as profit is to business…for bankers the only thing that matters is money and right now. They discount the value of money in the future for this reason. The John Kay quote is that profit is no more important to business as breathing is important to living: necessary but not sufficient.
Ø It’s interesting that Carney believes ratings vendors will never get rid of subjectivity. It’s self-evidently true but what if the ratings firms were rated as well. And that the consequences of their poor ratings were made clearer to the end users….or is the rating process too far removed from the companies themselves while the employees are loyal to their firm and thus consulting firms ought to march in there to provide this oversight?
Ø Carney has shown it is the crisis that triggers re-evaluations and gets political and social change. Therefore, climate events are a series of relatively small crises which are correlated to Greenhouse gas emissions but there are counter-narratives that dispute the causal link of the increases in the hurricane season in part to absolve polluting sectors of the economy (most of the product components). Known as “De nile” from Al Gore’s An Inconvenient Truth.
Ø Machievelli says that presenting to the public that you are lovable is better, but it is also essential that you be ruthless and feared. Does sustainable impact investing draw both actual supporters of the environment/human stability as well as self-interested posers? Yes. The ruthless and feared VW executives figured they could game the system…they are merely the folks that got caught…..
Ø G7 Finance Minister summit in June 2021 was unprecedented as they came together to commit to a 15% corporate tax minimum in all those jurisdictions UK, Canada, France, UK, Germany, Italy, EU, Japan. But of course, where there is a will, there is a consulting firm that will help these corporations maximize their after-tax profit (PwC, Deloitte, KPMG, EY).
Ø Carbon off-setting in theory is cool. In practice, it might be a bit challenging to imagine that the “books balance” in the intended manner of having 1 ton of carbon generated and corresponding additional tree that reduced 1 ton of carbon. The key is the additional tree planted wouldn’t have otherwise been planted, for example…because it was going to be planted anyway, then a carbon off-set, in this case, could be attributed to more then one off-setting attempt.
Ø Carney is advocating more people skill up for ESG. There were Masters degrees in environmental science (a decade ago while I was at LSE) that basically created an army of advocates without any significant job and career opportunities over the last decade (perhaps the economy was also screwed up…but…my point is well known). Just as those who studied Middle-Eastern politics in the wake of the Iraq war, those who studied environmentalism found that their skill is still not really taken seriously on its own. You need to be well-rounded, have strong fundamental understanding of things like accounting, finance, marketing, sales, mathematics, engineering or another marketable skills. That talent stack would, as a whole, get you in the doorway of a desired industry. Often, environmentalists I know would ironically become lawyers defending corporations in ways that padded their ESG optics, for example. So being jaded about ESG is informed by practical experience.
Ø Carney enters the political frame by stating that what society believes should be valued is X. He makes not systematic effort to evaluate what society wants himself. Hence, he needs to consider how citizens engage their own options and preferences.
Ø Carney doesn’t necessarily call out who the polluters are…he doesn’t put pen to paper to say that fossil fuel companies are the problem and could be part of the solution. And what to do about Alberta’s transition? Carney doesn’t talk about a way to help Albertans who have driven the Canadian economy forward in terms of GDP should be compensated…and or supported in retaining economic development locally against the back drop of the Rookie Mountains. Think about how Britain settled the slavery questions in 1834 by compensating the owners of slaves? Then think about how the US settled the slavery question between 1861 – 65? Oil is like slavery in some ways as I argued a decade ago.
Ø Carney as well as other advocates struggle with the fact that profit motives are the metric for success for companies (“you can’t [unfortunately for civil servants etc] manage what you can’t measure”} – Peter Drucker, therefore the creation of value and that the capture of that value in the form of money is THE primary driver. Whether it is the only driver is another matter. But I think a critic can be forgiven for thinking that it is naïve to think that this generation of C-suite decision-makers are mostly pre-occupied with the long-term impacts of the company at which they have climbed the ‘greasy hole’ to the top of. Really lucky and foolish CEOs have been incredibly successful merely because the things that we can measure about them keep appreciating in value…they keep hitting their targets. With ESG, you asking CEOs who may actually be hindering their business but are lucky that what is being measured is working (despite their own bad decision-making which can not be untangled for company performance)…you are asking the CEOs to stake their remaining career on something that cannot be measured in profit terms…
Ø Just because you can find a poll that shows ESG factors are valued by consumers of large asset managers, doesn’t mean you aren’t leading the witness. The question is will we all buy in to the sacrifice and the benefits of the grand transition? I think that more and more people are making decisions with the environment being a variable, but we are poor systems-thinkers. Typically, you and I are going to spend our days being mindful (in the moment) which means we like the dopamine hit of doing carbon off-setting things but not if it gets in the way of amygdala. Also there is a wide spectrum of preferences. To assume that they all care about profits and or all care about ESG, why would that happen? Surely it’s a mix of incentives and motives. And even if there was a major climate catastrophe, it is not clear that polluters would stop polluting considering (they would certainly argue) that the damage has now been done (absolutism abound!), they would argue that the feedback loop of hyper temperature increases that Carney warns about is probably wrong because predicting the future even in climate physics is difficult and they would continue to burn energy to build things they were building just before said catastrophe just as post-Covid, we’re returning to offices because there are rents on that commercial real-estate and C-suite wants to get more value of the capital expenditure on the company’s income statement.
Ø IF THE INVESTOR SEES the consequence of their preferences then they will be shaped for the better. If Quebec felt the consequences of shutting down the oil sands directly then their behaviour would be modified. If the consequences of your behaviours are imposed by an autonomous system it is much better than if the consequences are imposed by other people (Ottawa, bureaucrats, etc); in that latter case, it will fell like a game: As per How to talk so little kids will listen.
Ø Michael E Porter, Goerge Serafeim and Mark Kramer, ‘Where ESG Fails’, Institutional Investor, 16 October 2019.
Ø Robert G Eccles and Svetlana Klimenko, ‘The Investor Revolution’, Harvard Business Review (May – June 2019), ‘The True Faces of Sustainable Investing: Busting Myths Around ESG Investors’, Morningstar (April 2019).
Ø UK Department for International Development, ‘Investing in a Better World: result of UK survey on Financing the SDGs’ (September 2019).
Ø Sarah Boseley, ‘Revealed: cancer scientists’ pensions invested in tobacco’, Guardian, 30 May 2016.
Ø Oliver Hart and Luigi Zingales, ‘Companies Should Maximize Shareholder Welfare Not Market value’, Journal of Law, Finance, and Accounting 2(2) (2017).
Ø ‘Dynamic Materiality: Measuring What Matters’, Truvalue Labs (January 2020).
Ø Dane Christensen, George Serafeim and Anwhere Sikochi.
Ø PwC, ‘Purpose and Impact in Sustainability Reporting’ (November 2019).
Ø ‘Fiduciary Duty in the 21st: Final Report’, United Nations Environmental Programme Finance Initiative (2019).
Chapter 10: Covid Crisis: Fallout, Recovery and Renaissance
Key Takeaways
The reality is that mobility did decline as people accepted the lockdowns. State legitimacy is ensured by containing the virus. A lot of what Carney is saying here is a summary of what is relatively uncontroversial. He discusses the framework for the common good. Is that it is possible to calculate that value of a given person? The solidarity of citizens is important to note here, because the view was that no one should die in this pandemic regardless of age (or rather that folks did not want to contract this virus).
Other topics:
Perceived fairness of healthcare: you cannot have one set of rules for the rich and another for general citizens.
Value of a senior versus other citizens.
The young will have to pay twice in increased taxes and the depression of the moment.
Kids with internet had an advantage in home schooling.
Value creation and destruction increased under Covid.
R0 as the metric is a useful anchor just as the 1.5 degree Celsius increase to evade the most harmful effects of climate change.
Managing R0 was the core activity of this pandemic as far as governments were concerned.
Carney rationally described how the government that is presented ought to appear competent.
Local businesses will be emphasized over global for years to come.
There will be future black swans, no kidding.
We have continued to move towards market society however, in this Covid crisis, we have “acted like Rawlsians and communitarian rather than utilitarians and libertarians.” (260, Value(s)).
Covid and Climate Change
Carney predicts that the pandemic’s post active phase will see an increase the societal confidence in science, demands for stakeholder capitalism
Carney then draws a parallel between Covid and climate change. Using science to inform decision making for example. Having targets. How no country can isolate for each other in a pandemic or a climate crisis.
Leadership means being a custodian to the long-term. It’s not about you, says Carney.
There is a so what to this chapter….it falls short of saying anything about how the issuance of debt what appropriate or not. He didn’t talk about work from home or how the virus works which is a missed opportunity.
Carney seems to downplay the fact that the biggest failing of the pandemic is actually that government are operated by people who are focused inwardly in their own self interest within the architecture they have inherited. And such there is a lack of real time data to respond to the real society as it is occurring. There is a high lack information between citizen and government. The government should get out of the way for those who want that and step in for those who need help. Being able to distinguish between complex contradictory people as we all are is critical. It’s a credit card for UBI, it’s an interface to detail ones preferences voluntarily, it’s a relationship that is not simply a marketing blast….
Carney makes sweeping claims here that are sufficiently inoffensive to warrant much comment. There are no innovative sliders that he trials in this chapter, there was a lot of spicy behaviour in Covid but Carney manages to keep it very potatoe.
Surprised he doesn’t go after thie no mask wearers and other violators of lockDown. We tend to forget that these regulations were ignored by millions of people as they were ill enforced…
Citations Worth Noting for Part 1: Chapter 10
World Health Organization, ‘Coronavirus disease 2019 (COVID-19) Situation Report – 11’, 31 January 2020.
Christian von Soest and Julia Grauvogel, ‘Identity, procedures and performance: how authoritarian regimes legitimize their rule’, Contemporary Politics 23 (3) (2017), pp. 287 – 305.
Stephanie Hegarty, ‘The Chinese doctor who tried to warn others about coronavirus’, BBC, 6 February 2020.
Ruth Igielnik, ‘Most Americans say they regularly wore a mask in stores in the past month; fewer see oher doing it’, Pew Research Center, 23 June 2020.
Timothy Besley, ‘State Capacity, Reciprocity, and the Social Contract’, Econometrica 88(4) (July 2020), p. 1309 – 10.
Allan Freeman, ‘The unequal toll of Canada’s pandemic’, iPolitics, 29 May 2020.
Daniel Kahneman, Thinking, Fast and Slow (London: Allan Lane, 2011).
Timothy Besley and Nicholas Stern, ‘The Economics of Lockdown’, Fiscal Studies 41(3) October 2020), pp. 493 – 513.
This chapter discusses the discovering of COVID and all the other asks of this pandemic that we are all very familiar with. Carney was the governor of the Bank of England until February 2020. Economic and family priorities.
The Covid crisis emphasized:
Solidarity: companies, bank, society
Responsibility: for each other, employees, supplies, customers.
Sustainability: where the health consequences skew towards seniors while the economics consequences skew towards millennials and Gen Z.
Fairness: sharing the burden, providing access to care.
Dynamism: restoring the economy with massive government intervention and private sector resurgences…..
Duty of the State:
Carney goes through a review of political philosophy from Thomas Hobbes (1588 – 1679) to John Locke (1632 – 1704) to Rousseau (1712 – 1778) to suggest that in exchange for giving up certain freedoms, the state promises to deliver protection to its citizens. Much the same with central banks; that the public gives up the detailed nuanced control of the money supply in exchange the financial system delivers prosperity.
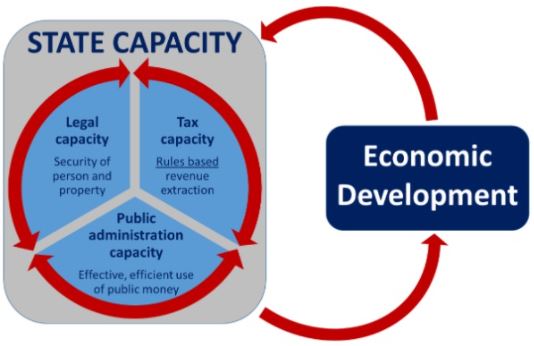
Capacity of the State must have:
1) legal capacity: ability to create regulations, enforce contracts and protect property rights: these include social distancing regulations that aimed to reduce transmission of COVID 19;
2) collective capacity delivering services;
3) fiscal capacity: power to tax and spend: state capacity has moved from 10% of GDP to 25% to 50% of GDP with corresponding services to protect citizens from COVID 19.
Other Points:
Poor compliance in democratic societies;
Stock piles were not restocked;
Bill Gates Ted Talk from 2015 was not actioned by any one actor;
Many countries didn’t have PPE and depended on China’s production initially;
No country is really prepared for this particular kind of pandemic;
South Korea had a pandemic in 2015 and Carney repeats the often mentioned success of South Korea through contact tracing and geo-targeting of users;
Governments need to be better at coordinating: there were departmental territoriality;
In simulations for pandemics this was very evident.
Cost-Benefit Analysis for Hard Choices:
There was a weighting of variables to decide whether to lockdown or otherwise.
The effects of lockdown: domestic abuse were hard to do that.
Calculating the value of a human life: is hard to do. But there is actuaries to put the intrinsic versus investment value of a life or the net present value of all future cashflows that person is predicted to generate. Life is priceless. Sometimes the calculation is about the productivity of the person in life…..
Schelling’s “The Life You Save May Be Your Own” points out that the value of a life principally the concern of the person living it. Value of a Statistical Life (VSL) became the industry standard. The example Carney provides is the a risk of death in a high-risk job might be 1 in 10,000 and employees receive $300 of danger pay, therefore the VSL is $3,000,000. There are several other methods: 1) stated-preference, 2)hedonic-wage, 3) contingent etc. And different countries use different metrics in similar circumstances. In Canada, the estimated range of a human life is $3.4M to $9.9M CAD meanwhile in the US, the estimated range of a human life is $1M to $10M USD. Healthcare looks at quality-adjusted life year (QALY) and cost-utility versus cost-benefit analysis. Schelling’s assumption about how a person can evaluate the value of their life. VSL usage is a moral choice. Wealthcare many not be measured properly according to Carney. Another model is the VSLY Value of a Statistical Life Year. The question remains: do all lives have an equal value or is it the number of life years should be treated as equal?
While it is complicated, I would have liked Carney to have explained the system of money creation in simple terms as it pertains to the pandemic. The level of government issuance of support has been massive. It is imperative folks understand how stimulus money is created.
The perception that money is created out of thin air, subject to political pressures is not true. Zeitgeist and other explanations of the money system are warped thinking. There friends and family going around saying that central banks ‘just print money’ whenever it suits them…
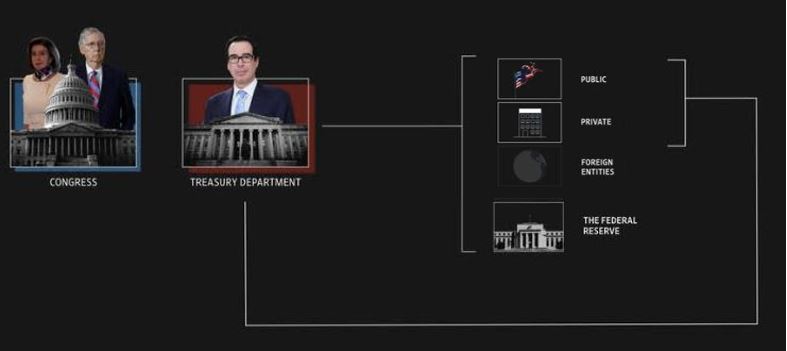
Here is a good explanation of how the central bank enables money creation: To support small businesses and citizens out of work: Is the government increasing tax or are they printing money during the pandemic? The stimulus money was not coming from new taxes so here the government raises through borrowing. The government issues treasury bills to three groups of savers:
(1) public sector (other parts of the government,
(2) the private sector (people and companies),
(3) foreign entities.
The government agrees to pay those savers back with interest at a future date. In the short-term the government uses that cash sucked out of the economy in exchange for the treasury bills to issue stimulus cheques back into the economy. Keynesian economics says that the more stimulus there is, the more economic activity which enables more private savings which then fuels more transactions for bonds. The government can borrow, unlike an individual, through this system as long as the economy is growing at the same or greater rate then that of the debt. The economy is growing at the same rate as debt then the debt to GDP ratio will be stable. If the debt to GDP ratio is stable, then the government can argue for continued investment in its debt securities (ie. bonds).
An additional layer of complexity is that: (4) the source which is the Mint in Canada and the Federal Reserve in the US does not print actual paper money much any more but does indeed ‘print out of thin air’: electronic money, that is credited in the treasury department’s account. In exchange, the Fed then holds treasury bills. The key consequence of issuing too much money with this source (4) is inflation whereby more money in circulation is chasing the same limited number of goods available thus driving the price upward of the individual goods. The 10 year Treasury Note then starts to go up and inflation creeps in. In this case, the Fed needs to increase interest rates to counteract/dampen the purchasing of the demand side…..
The fines for violating COVID rules have an earned media dynamic: we know that the virus is spread through gatherings where one ore more participants has the virus. When someone gets an ‘arbitrary fine’ it effectively markets better than other forms of advertising such as digital. The injustice of the fine is earned media.
There are Canadians under the false impression that government at the federal, provincial and municipal level are not allowed to make rules that ‘violate’ the Charter of Rights and Freedoms. Well, a constitution has to be enforced, my friend…
This time will be different which was Carney’s number one lie in finance seems to be fillable here to say, why would you think that in a future pandemic in say 2055, that our children will be able to respond better then this time?
Just are Carney fails to explain how the central bank manages the money supply, he too here fails to give a basic description of the “obvious’ nature of the COVID 19 virus. Its unique gestation period in which it sheds without the host having any symptoms for T+7 days is very novel unlike other viruses that are initially extremely aggressive, for example, ebola or SARS.
The threat of future pandemics is very real until it isn’t at all. If COVID had the immune effects of HIV then the response would have been more severe in North America. However COVID can be contracted and the likelihood of death is 1 – 5% based on comorbidities. We’ve literally spent the last year talking about this virus. The next virus if it were HIV but airborne, the human race would be in full black plaque mode. Freedom loving + scientific illiteracy are a potent weapon.
Lack of understanding the characteristics of the virus.
In ability to connect barriers that create friction such as laws, walls and masks have the underlying same logic; they do not prevent all the negatives from happening but laws, walls and masks make the unwanted thing from happening, obviously.
Citations Worth Noting for Part 1: Chapter 9:
John Locke, A Third Concerning Toleration, in Ian Shapiro (ed.), Two Treaties of Government and A Letter Concerning Toleration, 1689.
Jean-Jacques Rousseau, The Social Contract.
Thomas Piketty, Capital in the Twenty-First Century (Cambridge, Mass.: Harvard University Press, 2014).
Derek Thompson, ‘What’s Behind South Korea’s COVID-19 Exceptionalism?’, Atlantic, 6 May 2020.
A.E. Hofflander, ‘The Human Life Value: An Historical Perspective’, Journal of Risk and Insurance 33(1) (1966).
Cass Sunstein, The Cost-Benefit Revolution (Cambridge, Mass.: MIT Press, 2018): OECD (2012).
This publication is dedicated to finance, politics and history