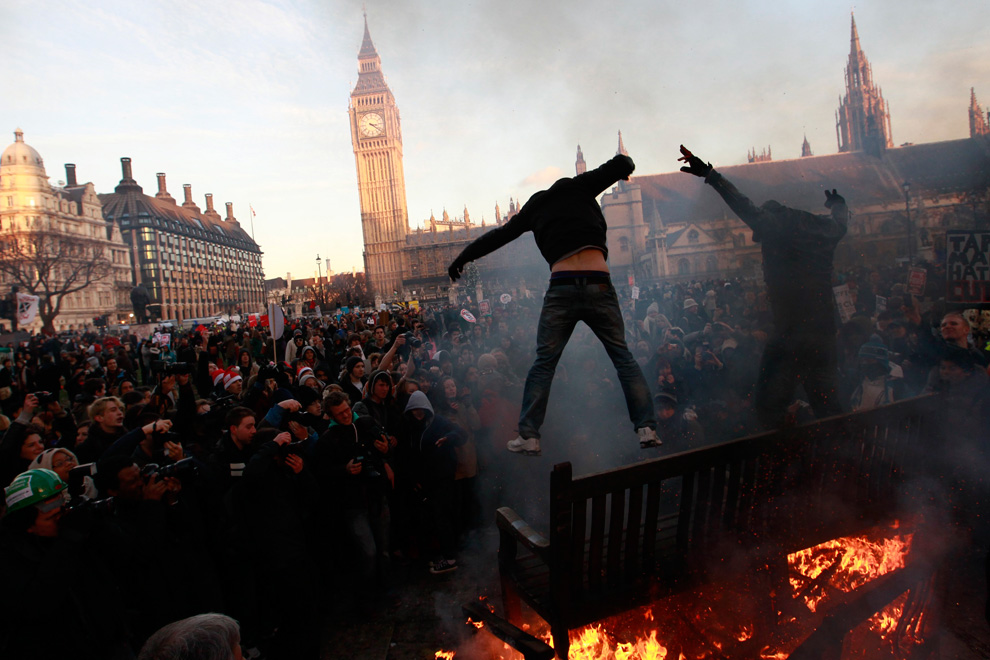Chapter 8 Creating a Simpler, Safer, Fairer Financial System
Key Takeaway
The Problem with Humans versus Objects – Determinism:
Carney makes the classic case that value measurement losses sight of intrinsic or objective reality and then there is a burst of the bubble and wealthy people lose their shirts. This touches on the central thesis of Random Walk Down Wall Street. Many economists have this instinct to try to explain reality by convincing themselves and then others that people are perfectly rational actors. Carney points out that this rational actors theory is wacky: adding that economists envy physicists and engineers, economists love neat equations and want a deterministic model of reality but that’s just too bad, economist! Determinism, meaning that any input will have a predetermined outcome in the model, doesn’t work when the subject of your experiment has agency/choice. Try telling a toddler that they are rational! Lol.
Sir Isaac Newton said it best: “I can calculate the motions of celestial bodies, but not the madness of people. ” Now, fun fact, Newton wrote that having lost a huge investment by speculating in the famous South Sea Company which basically involved misleading investors into thinking that the British empire had opened up South America to trade when in reality, they were actually capped at 1 ship per port per year in South America….But of course, human being aren’t going to let facts get in the way of investment momentum that drives prices up! Get on the train, folks! And again, because humans are awesome, we will #$ck with you’re predictions whether you like it or not.
Case in point, not everything that is going up is a bubble. Value that is disconnected from fundamentals of accounting are more likely to be a bubble says Carney but there are no guarantees. The investment could be a castle in the sky or just a really good investment…
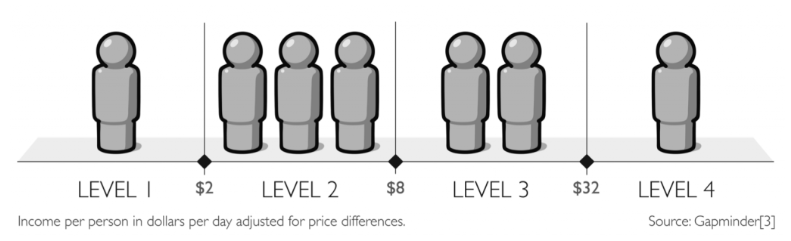
2008 – 2016 UK:
The lost decade in the UK where there was political fragmentation of the economy is from 2008 to 2016, according to Carney. The real household income did not grow in the UK for that decade (technically 8 years…but whatever). There was a decline of trust in experts. Finance lost its integrity, prudence and became more protectionist. It came crashing down on the poorest in the financial crisis as discussed in the previous chapter. The G20 had to make radical adjustments and reforms. Value was disconnected on the way up and re-calibrated on the way down.
No, I’m not gonna put Thug Life shades (sunglasses) on Queen Elizabeth II. I have some modicum of decency left in me. I thought about though…
When Queen Elizabeth II asked:
“Why did no one notice the credit crisis?” The answer: signed by 33 distinguished economists said ‘it was the failure of the collective imagination of many bright people in the UK and internationally to understand the risk of the system as a whole.’
So another factor is certainly, the lack of systems thinking! What I do may not have a positive / negative impact on me, but it could have a positive / negative impact on others.
The decline in the trust for experts comes from experts being:
too academic and therefore disconnected to practical reality…
simply creating bearers for others to understand their view point and choosing to capture value instead of communicating valuably.
Unable to see the credit crisis coming…
Lack of systems thinking / solidarity / or, in other words, the reliance on the invisible hand / free market as infinitely wise.
The fault lines were:
too much debt;
excessive reliance on markets for liquidity;
Complexity in derivative markets;
Huge regulatory risk,
Misaligned banks and imitators.
Getting Global Support for Reforms:G20 finance ministers backstopped the entire system.
G8 treasury leaders. They didn’t think that the system would self equilibrate as a solution. As such, they created a new plan with the FSB (financial stability board). It is the United Nations for finance. Mario Draghi had an immediate impact on the financial system as the chair. The FSB developed over 100 reforms. And Mark Carney succeeded Draghi as chair of the G20.
Chairing the G20 Finance Stability Board comes with several important lessons:
You must have a clear vision; you need political backing. FSB has the power to recommend reforms, however the national legislatures must put these reforms in place…
You must get the best people you can around the table. Bureaucracy is not helpful here. The group is composed of central bankers, regulators, finance ministers….
You must build consensus that entrenches ownership. Dany Rodrik sees an intractable problem here: a trilema of economics, democracy and sovereignty…We have a seeding or pooling influence. No country is obligated to implement these reforms however it is in everyone, globally that these reforms be implemented at the national level. Commercial banks were happy that “heads they win tails we lose” with the bail out but there were positive reforms made via FSB.
Mark Carney’s Three Lies of Finance:
Financial crises happen frequently, if you hear someone say any of these lies, then take note:
“This time, it’s different”
“Markets always clear”
“Markets are always moral”
“This time, it’s different”: what’s happening today is fundamentally different from all prior human history….Nope, don’t believe this lie. Usually, a new innovation is compelling because of its initial success, complexity and opacity. Solving the stagflation of the 1979s and 80s with new monetary stability that were democratic, effective, evident remits, strong governance….The Great Moderation from the 1990s to 2008s also paralleled, technological growth, non-financial consumption, such that it was easy to become complacent. And people assumed housing prices can only go up. This optimism is known at the business cycle. Carney refers to this as the Minsky moment: where lending is abruptly pulled back when financial experts realize there is a correct brewing and thus causes the economic downturn to more severe. In 2008, “Minsky went mainstream.” (186, Value(s)).
“Markets always clear”: at the right price, excess supply and demand will clear (ie. the supply will meet demand). Labour markets are efficient and clear? Sorry, nope they are rigid and sticky. If money is efficient, then they will reach equilibrium? Sorry, nope markets are incredibly ineffective in reality. Markets do not always clear because life is not a textbook. You can’t describe the real world because people are too complex for any mental or predictive model. Synthetic credit risk; the risk was spread all up. Panic ensues with risk being pooled. The real world is far more complex, we cannot anticipate all of human activity at any given time. Calculating every scenario is impossible, Newtonian physics doesn’t quite work in every scenario and physics doesn’t even involve tricky human beings.
Keynes in General Theory shows that when having his students rank the prettiness of faces in exchange for a prize, it’s more important to calculate what the average opinion believes the average opinion is. Keynes noted that this is what happens in markets where everyone else was thinking, the derivative of the derivative of what other people will do matters more (subjective utility). Keynesian saw the instability is on spontaneous preferences, the full consequences are only based on animal spirits. The belief that markets are always right was what enabled the last bubble and the next bubble. Markets are populated by people however, fickle people.
Cass Sunstein argues that 1) preferences in public differ to what is in our heads, 2) social obligations impact our acceptance of new things. For example, if 1000 people protest something, then we will be more amenable to that something as well. Read: Robert Schiller’s Narrative Economics. Critical mass opinion happens in finance as well. The Minsky cycle works on average and average opinion. How do markets become more differentiated? There is a spontaneous urge to make a decision rather than a complex weighted calculation of the mathematical benefits x the probabilities of a given consequence of the decision…
“Markets are moral”: FICC (fixed income, currencies and commodities markets) have a lot of fraud in them even though they determine the cost of resources, food, housing, government debt prices etc. The commodity squeezes in rye in 1868, cocoa in 2010, and ‘wash trades’ in Manhattan Electrical Supply on 1930 and the Tera Exchange in 2014 show a recurring phenomenon. There have been a lot of squeezes. Planted rumours to drive up a cost happens frequently wherever traders are bored or desperate. Tweaking LIBOR and FX involved manipulating these foreign exchange benchmarks rates for the interest across firms at the expense of retail and corporate clients in the billions. Technology evolves and laws are passed. Engineers of the subprime crisis were clubby and colluded online, globe bank misconduct costs were $320 Billion for $5Trillion of assets. People were colluding online and few were held to account. And there was no rush to take the blame. Trust in the UK went from 90% (1980) of UK citizens thinking banks were well run versus 20% (in 2008). Financial firms help the real economy. The FICC markets, markets are ever more important to people. FICC markets can go wrong with poor regulation. Carney argues you need Hard infrastructure (regulations, foreign exchange benchmark objectivity) and Soft infrastructure like corporate culture, informal codes and policy handbooks. Light banks. Central banks participate in fire insurance. Mistrust between companies and hesitate to invest in firms. FICC infrastructure is key, soft codes of infrastructure, weak banks. Relies on informality.
Carney argues that the solutions are the following:
Trust: G20’s Financial Stability Board helps by acknowledging that the market is amoral and will not always clear by instilling greater trust, less complexity.
Smarter: Ensure traders remain pro-market (shouldn’t be a problem) but support smarter regulation.
Avoid Lies: Ensure financial professionals avoid the attractiveness of the 3 lies.
Realistic: Recognize that regulation will not bust the cycles since innovation is always happening but ensure that regulators be understanding. Implement policy that make real markets more robust with market infrastructure that creates the best markets for innovation.
Transparency: In 2008, Over the Counter derivative trades were largely unregulated, bilaterally settled (closed door) and unreported, but now 90% of new single currency interest rate derivatives are centrally cleared in the US i.e there is transparency.
Systems Thinking: Ensure financial professionals recognize the importance of protecting the system as a whole.
Risks in Emerging Markets are a danger for another financial crisis where the lie that markets always clear continues. China’s economic success contains a lot of shadow banking (SIVs, mortgage brokers, finance companies, hedge funds and private asset pools), there are lots of repo financing, major borrowers and banks with significant opacity. There is now a worrying amount of debt in China that could leave Ray Dalio reevaluating his career choices once again. There could be a major margin call / run on Chinese assets, with first mover. There will be mismatches of markets. There could be a rush to get out of the Chinese market: this is the risk of being trapped when the assumption that markets will always clear (buyers and sellers will find each other) is exposed as wrong. Cyber to crypto crises could also trigger another financial crisis.
Risks in Illiquid Assets treated as if They Are Liquid:
New risk is the global assets under management of $50 trillion in 2010 to $90 trillion in 2021. But $30 trillion is promised to be liquid when it is illiquid assets. Carney’s addressed this problem of not having consistency between liquidity of funds’ asset versus their redemption terms while he was governor of the Bank of England with the help of the FCA (Financial Conduct Authority):
1) liquidity of funds’ assets should be valued as either a) the price discount needed to do a quick sale of a vertical slice of those assets OR b) a time period needed to sell the asset without a price discount.
2) Investors who redeem get a price for their investment that mirrors the discount required to sell a proportion of a funds’ within the special redemption notice period;
3) the “redemption notice period mirror the time needed to sell the required proportion of a funds’ assets without discounts beyond those caputed in the price received by redeeming investors.” (196, Value(s)).
During the 2008 crisis:
Liquidity disappeared with cash-powered banks refusing to lend;
There was a ‘run on repo’ which increased the haircuts on collateral to de-risk counterparties which were shadow banks that then collapsed;
In Europe, the debt crisis compounded these problems driving up nationalist sentiments…
There is now the liquidity coverage ratio and net stable funding ratios…but there are weaknesses with US repo market troubles in 2019- 2020. The Fed’s open market operates calmed down…Carney doesn’t know where the next bubble will burst but he has a few ideas.
Bagegot’s principal of being the lender of last resort thus preventing short-term liquidity shortages from causing wide spread insolvency.
Bank of England presentation by Mark Carney…
Central banks have challenges:
Figuring out if the firm is solvent when the market is against that firm’s assets and the market can be wrong longer than that firm can stay liquid;
What constitutes good collateral, can always lend government bonds and in the 2008 crisis, it didn’t appear to have an impact on the functioning of the system, banks horde
The penalty rate means the firms come late because it convey weakness.
Central banks have now moved to doing transparent auctions of liquidity to many counter-parties which includes banks, broker-dealers, an central counterparties in the derivatives market. Bank of England has a contingent term repo facility….
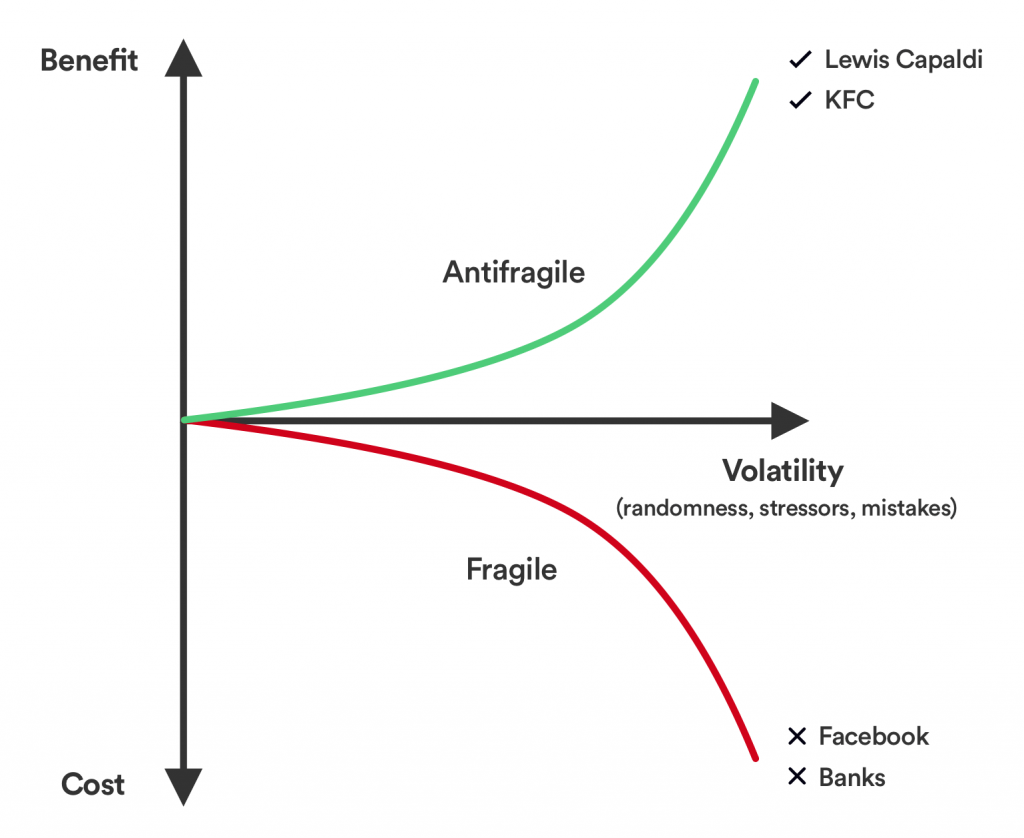
An Anti-Fragile System – This Time is Different – What Was Done to Banks:
Public trust was harmed most by the mantra of too-big-to-fail banks.
Banks didn’t pass lending out enough which amplified inequality.
Privatization of profits while socializing the losses harmed trust.
Public paid $15 trillion in bailouts, government guarantees against bank debts and special central bank liquidity projects…..
G20 FSB brought in standards to create an anti-fragile system:
Banks are less complex.
Banks have a ‘living will’ and are reorganized so they have a firewall between the banking that continues to serve families and business even if their investment banking division is imploding.
Trading is less between banks thus shifting to lending to customers.
Public funding has dropped by 90% post-crisis with market discipline…
Senior leadership can be expected to bare the cost of failure.
Can’t legislate virtue but can legislate incentives around how senior leaders train staff.
Improving cyber penetration attack resilience.
Looking for risks across the economy, thinking system level about where the next crisis is least likely to be and make sure that is focused.
Macroprudential policy: addressing systematic risks….cyclical risk when the financial system loosens up, debt grows and complacency sets in, the Minsky effect is severe…
Macroprudential policy: addressing systematic risks…structural risks when there is a wbe of exposures to derivatives risk, which means the need to have liquidity buffers, restrictions on mortgage lending, shutting down the shadow banking approach.
Bank of England serves the purposes “To promote the people of the United Kingdom”
Restoring Morality to Markets:
Oscillating regulation, light touch versus total regulation.
Aligning compensation with values;
Increasing senior management accountability;
Renewing the vocation of finance.
Longer-Term Horizons Focus the Mind: Bonuses in the UK are now managed with compensation by delayed by 7 years. If there is misconduct then bonuses can be clawed back, according to Carney. Business mission statements tend.
FICC Markets now have new guidelines:
have clear, proportionate and consistently applied standards of market practice;
are transparent enough to allow users to verify that those standards are consistently applied;
provide open access (either directly or through an open competitive and well-regulated system of intermediation);
Allow market participants to compete on the basis of merit; and
Provide confidence that participants will behave with integrity.
Effective markets are those which also:
Allow en users to undertake investment, funding, risk transfer and other transactions in a predictable way;
Are underpinned by robust trading and post-trade infrastructure enabling participants to source available liquidity;
Enable market participants to form, discover and trade at competitive prices; and
Ensure proper allocation of capital and risk.
Drawing on the Magna Carta:
Having the right principles is essential. Keep pace with the innovation. Senior Managers Regime (SMR) individual accountability. Values need to be exercised like a muscle. SMR makes sure senior leadership is accountable even if many of them were involves in the 2008 financial crisis. Employees must be connected to their communities.
Mark Carney can look to Mario Draghi for inspiration since, Draghi is now the Prime Minister of Italy (as of 2021). Central Bankers can cross into the political sphere. Currently Draghi is trying to get bank mergers to happen in order to clean themselves up. So like Carney, using the power of politics to effect change is sometimes valuable where as a central banker, you cannot effect change. Analogies, and history does not have predictive power, Italy is very different from Canada, however it is instructive that getting into a position of power may not be a high hurdle for Carney. Finance catteacts people with no socience training, because they are looking for absolutes. These folks lean deterministic.
A bit odd that the Senior Managers Regime (SMR) doesn’t really connect because the people who self-select to work in banking are frequently math. The problem is that the people with the experience made decisions in the financial crisis that seem to benefit themselves disproportionately company to the general public. It is similar to having doctors make decisions for hospitals, there is a conflict of interest in being in control and regulating oneself.
Perhaps the bad behaviour is in Crypto…
Great economic shocks cause institutions to recalibrate and reform. It isn’t the individual actors that drive such change but rather macro externalities where no one internally can be blamed that cause reform.
Citations Worth Noting for Part 1: Chapter 8:
Carmen M. Reinhart and Kenneth S. Rogoff, This Time is Different: Either Centuries of Financial Folly (Princeton: Princeton University Press, 2009)
Raghuram Rajan, Fault Lines: How Hidden Fractures Still Threaten the World Economy (Princeton: Princeton University Press, 2010).
Hyman P. Minsky, ‘The Financial Instability Hypothesis’, Levy Economics Institute Working Paper No. 74 (May 1992).
Kenneth J. Arrow and Gerard Debreu, ‘Existence of an equilibrium for a competitive economy’, Econometrica 22(3) (1954).
Gilian Tet, Fool’s Gold (London: Little, Brown, 2009) which shows that derivatives were distributed throughout 100s of balance sheets through the pooling and distribution of that risk. Similar in essence to a decentralized ledger.
John Maynard Keynes, The General Theory of Employment, Interest and Money (London: Palgrave Macmillan, 1936).
Wlater Bagehot, Lombard Street: A Description of the Money Market (Cambridge: Cambridge University Press, 2011).
Financial Stability Board, ‘Strengthening Governance Frameworks to Mitigate Misconduct Risk: A Toolkit for Firms and Supervisors’ (April 2018).
Life is short. Love one another….focus on common ground. But if you’re getting into an argument, check these classic argumentative habits. But know that the biggest mistake you can make in life is to believe that your opinion is the correct one, that your opinion should be imposed on all others in your immediate or extended sphere. The second biggest mistake is to think that people will ever really understand what you are saying, even if you try to be as clear as possible. And that’s because others: a) can’t live your life, b) want to project on to you their interpretation of what you have just said and c) will never be able to fully get inside your head. Plus, your counterpart is too busy preparing their next point in the conversation…while you are talking. So accept that a civil argument is mostly to exercise your own mind.
A List of Classic Social Science concepts to be aware of in any Argument:
“Winning” an Argument
Okay, you can’t really win an argument, but the best next thing is to say to your counterpart, “fine, what is the next step based on your argument?” If your counterparty has made a valid point, they will frequently stay mired in the awareness stage in which they are trying to validate the logic of their argument rather then extending it outwardly to the implications and the consequences of their argument. For example, that inequality is evil. All you have to do is say; “So, what’s the next step.” And they will have difficulty because a policy of enforcing equality is way more difficult than the normative claim that equality and fairness is a positive aspiration. Saying “what’s the next step” typically shifts the debate into your corner.
Anchoring
Your counterparty will want to make the first offer in a negotiation, so that they frame the discussion around what they are advocating. That’s why striking a specific price point is critical. You could say that healthcare is a human right for example. That anchors and locks down your position and shapes the discussion thereafter.
Cognitive dissonance
Is a situation where you mind holds two conflicting ideas at the same time. When you have a belief that you believe is true and then discover that the facts show otherwise, instead of accepting being wrong, you come up with scrambled thinking to avoid reconciling yourself with the truth that you were wrong. This is also known as negative capability; the most successful management and leadership are able to overcome cognitive dissonance, identify it and figure it out in others. Tells that someone has cognitive dissonances are: 1) using word salad to win an argument, 2) mind-reading the other person’s intentions, 3) expanding the opponents argument with absurd absolutes, 4) tells like “so….your saying” which are misinterpretations of what you are saying. Cognitive dissonance is a flaw that EVERYONE has and can be used to turn others onto your side, if you point out someone else’s cognitive dissonance in a compelling way, you can help them see your world view better, as long as you do that gently.
Confirmation bias
Is where your brain subconsciously finds evidence in the real world that reflects what you are most thinking about. The human brain builds biases based on patterns observed over time. As a result, biases are impossible to get rid of. The curious point here is that confirmation bias is also where your brain starts pointing out instances that align with what you are looking for as evidence to support your pre-existing view. So when you are in an argument, you might actually have confirmation bias that the other person does not and because neither of you can access eachother’s biases directly, you just argue without knowing which biases are preventing clarity of position from being realized. And of course, if people are involved there are competing interpretations of what the truth is from their perspective….
Filter
We “filter” reality and each person is interpreting reality from their own perspective. Bertrand Russel said that there only markers that we are experiencing the same reality are physical markers. A filter is the brain’s interpretation of physical reality. The brain is shaped by the Value Laden hypothesis. Max Weber described this phenomenon in the 19th century; basically, we have values or theories or frameworks (based on pattern recognition and the like) that we believe can predict future actions and we go out into the world, to prove our theories are correct. And sadly, we tend to believe our filters too much which creates confirmation bias.
High-Ground Strategy
Taking a debate away from the level of detailed debate to a topic that everyone can agree on. Being intentionally vague has its place in any communication strategy. It’s also known as triangulation, we aren’t trying to win an argument this way, we’re just trying to make ourselves feel better about ourselves.
Thinking Past the Sale
Persuasion tactic where you get those you are trying to persuade to think about what it will be like after the decision is made. The act of forcing us to imagine what you want to have happen is a means of shaping opinion, as long as you can also sell the good and downplay the bad. Visualizations are very powerful.
Pacing and Leading
Pacing and leading is when the speaker gets into the learner’s head, so that they understand your thinking, speech and breath of the speaker and thus this more persuasive because we believe the speaker is speaking for us. As I said in the introduction, your counterparty is never going to fully get you but if you can create the illusion that you get them, you’re ahead of the game. Things like repeating in your own words what your counterparty has just said is helpful. Basically, mirroring the audience or counterparty. Negative attacks on your character is what people remember in these conversations. You should match your counterparty’s cadence of attacks until you’re both covered in holiday stuffing or whatever. Just kidding, chill.
Psychic Psychiatrist illusion
Believing that you can diagnose someone’s sanity just by their outward actions from a far is just wrong. This activity is typically shunned in most circumstances but can be used as an attack on someone who’s leadership you detest.
Walking Talking Contradiction
Policies are obviously going to overlap and conflict with each other. Politicians by definition will make statements that contradict other statements made because facts are moving objects in the sense that time is a moving object. People want snacks and beer and burgers and salad. We are walking emotional contradictors, not logical beings. Get used to it, don’t fight human nature unless you intend to be confounded by it (i.e lose).
Rhetoric is Not Action
If you ask your counterparty to put their money where their mouth is (demonstrate how they live by their opinion /or make a bet) and they refuse, they are simply being rhetorical. Rhetoric, virtue signally is also an extension of the contradiction since emotional statements are often illogical and will contradict themselves. Words matter but to what degree depends on how much you want to undermine the communicator. The difference between assimilation and integration for example, is mostly in the speakers head. Understand that top persuaders will communicate to the the less informed (who have not studied the nuances) with the aim of persuading. Most folks are least likely to detect contradictions and most likely to be appealed to on emotional grounds but when the general public spots a contradiction, we as people get a little high off of the enlightenment that needs to be handled with care or you risk insulting the intelligence of the uninformed. Remember that the less informed aren’t necessarily idiots are all, it’s just they have better things to do then argue about what you care about.
History Does Not Repeat Itself
Using analogies from past events to imply a future outcome that is relevant to whatever argument you are having now is hollow talk. You can’t predictive the future generally, but in particular by saying this current situation is just like this other past situation and look how that past situation turned out therefore the same will happen here, is lazy thinking.
Facts are Weaker than Fiction
Better more reliable facts are helpful but secondary. Facts relating to human behavior and activity can change and evolve. Facts are moving objects therefore any statement is subject to being made false through time-lapse (passage of time). Meanwhile, fiction is static because there are no reference points to suggest it is changing. And people love certainty!
Rationality versus Irrationality
Human beings are irrational most of the time, therefore appealing to the irrational is far more effective. Get used to it. An example where rationality does not take hold is the financial sector. There are systems to analyze finance which managers use to ensure they are in control of the apparatus of capital creation, however, Burton Malkiel’s A Random Walk Down Wall Streetillustrates that irrationality rules the stock market. Human are irrational with pockets of rationality in specific circumstances; the final purchase decision is usually not rational. Love is not rational. And politics is the art of the possible, not the art of the rational. Complicated prediction models with many assumptions have the possibility of being very wrong because the assumptions are rarely dispassionately derived.
Acknowledging that this Argument was good Exercise:
it’s a nice way to diffuse a situation, if you can explain what this argument really was about. It was about exercising your brain. The most important “muscle” in the human body, needs a good work out and so you can finish off any argument by stating the obvious that 1) we’re not going to solve the world’s problems by the end of this argument, 2) it was good exercise…
Max Weber (1864 – 1920), who died in the last global pandemic, is the father of modern sociology. His approaches to research and methodology were ground breaking within academia. His definitions have been exceptional, for example, the state as having a monopoly on the legitimate use of physical force and defining charismatic leaders, bureaucracy, methodological individualism and controversially the Protestant Work ethic. Max Weber also had some anti-Polish views which is bizarre and potentially evil. Below are notes on his theories in relation to nationalism, war and strategic ends.
Weber’s Theory of Nationalism: power & prestige
Facts & Figures
List of previous final exam questions:
How did Weber define and explain nationalism? What role did prestige and power play in his understanding of nationalism?
Why is there no sociological definition of nationalism according to Weber?
Discuss the constructed ethnicity Weber argued.
To what extent, if at all, Weber developed clear concepts and theories of ethnicity, nationality, nation-state and nationalism.
Guenther Roth & Claus Wittich (eds), Economy and Society (2 vols., Berkeley & Los Angeles, 1978). vol.1, `Ethnic Groups’, pp.385-398
H.H.Gerth & C.Wright Mills (eds), From Max Weber: Essays in Sociology (New York, 1946). `Structures of Power’, pp.159-179 (most of which is also to be found in Economy and Society, vol.2, pp.910-926).
Beetham, D. (1974). Max Weber and the Theory of Modern Politics. London. Chapter 5 `Nationalism and the nation-state’
M. Guibernau, Nationalisms: The Nation-State and Nationalism in the Twentieth Century (Cambridge, 1996), chapter 1 `Nationalism in classical sociological theory’.
Defining, Background, Foundations
Of all the writing undertaken in Max Weber’s 56 years, only two significant passages use social science to address the question of nationalism. In order to ascertain why Weber never explicitly formulated a theory of nationalism, this paper will do the following.
Posthumous Works Should Be Questioned: MAJOR point about his papers on Nations and Ethnicity: We would never have known about Weber’s thoughts on ethnic groups and nations had his wife not published it posthumously by Marianne Weber in Economy & Society. It wasn’t his finest material. He says at the end of ethnic groups that there is no ideal type for ethnicity. It is fragmentary like Economy & Society in general.
Nation & Ethnic Group: Weber would never have had it published because there is no ideal type here.Weber’s ethnicity text is associated with a Gemeinshaft concept: it is a belief not a fact: it is a belief in relationships that are rationally calculated: it is pre-modern: it might not work in large scale societies. NOTE that he did study subjective texts
Outline the Nation and Ethnic Groups papers and argue Weber forwards an instrumentalist view of these phenomena.
Argue that Weber’s ultimate value is informed by the same value-laden pursuit: political power and prestige of the German nation-state.
Conclude that Weber never formulated a sociological explanation of nationalism for two reasons,
a) the concept had not fully developed as central in the modernization process during his lifetime AND
b) he recognized the subjectivity and amorphous tendency of this field of study.
NOTHING CAN BE ACHIEVED WITHOUT Struggle. Workaholic, Germany world position, struggle, becoming a politcian, struggle. Darwinists Realpolitk.
(Tonnies, 1887) 2 forms of Human Association:
Gemeinschaft: community of sentiment ie. the nation. Ties on effective relationships: small-scale interactions.
Gemeinschaft (often translated as community) is an association in which individuals are oriented to the large association as much if not more than to their own self interest. Furthermore, individuals in Gemeinschaft are regulated by common mores, or beliefs about the appropriate behavior and responsibility of members of the association, to each other and to the association at large; associations marked by “unity of will” (Tönnies, 22). Tönnies saw the family as the most perfect expression of Gemeinschaft; however, he expected that Gemeinschaft could be based on shared place and shared belief as well as kinship, and he included globally dispersed religious communities as possible examples of Gemeinschaft.
Gemeinschafts are broadly characterized by a moderate division of labour, strong personal relationships, strong families, and relatively simple social institutions. In such societies there is seldom a need to enforce social control externally, due to a collective sense of loyalty individuals feel for society.Weber moralizes the Gemeinshaft: Weber we are not going to get those Gemeinshaft back with ethical.
Gesellshaft: society and rational association: ties are less effective: self-interested.
In contrast, Gesellschaft (often translated as society or civil society or ‘association’) describes associations in which, for the individual, the larger association never takes on more importance than the individual’s self interest, and lack the same level of shared mores. Gesellschaft is maintained through individuals acting in their own self-interest. A modern business is a good example of Gesellschaft, the workers, managers, and owners may have very little in terms of shared orientations or beliefs, they may not care deeply for the product they are making, but it is in all their self interest to come to work to make money, and thus the business continues.
Unlike Gemeinschaften, Gesellschaften emphasize secondary relationships rather than familial or community ties, and there is generally less individual loyalty to society. Social cohesion in Gesellschafts typically derives from a more elaborate division of labor. Such societies are considered more susceptible to class conflict as well as racial and ethnic conflicts.
Since, for Tönnies, Gemeinschaft and Gesellschaft are normal types, he considered them a matter of Pure Sociology, whereas in Applied Sociology, on doing empirical research, he expected to find nothing else than a mix of them. Nevertheless, following Tönnies, without normal types one might not be able to analyze this mix.
The primary direction of history from Gemeinschaft -> Gessellschaft. Weber doesn’t believe in developmental movements: he sees the calculability of relationship.
Weber is a methodological individualists: he is interested in communializing: socializing effects: we aren’t moving from Gemeinschaft to Gesellshaft but certain things are producing Gesellschaft: people might say that their family relationships have a more effective ties. A wage labourer will negotiation personal contracts: not so clear-cut.
Values Judgements Backed By Science:
As long as Weber is able to shift Polish: confronted Bauer: Weber don’t believe in objective truths: this is the best I can offer but with new evidence he will shift on Polish. Build up a scientific then use it to defend his means.
He knows that he is full of values he accepts and thinks its okay aslong as you are rational. Spent his whole career being value-laden then he says that science should strive to be objective BUT then if we do all this we should not be doing it in the lecture (Science, 1919). Science Vocation: instrinctive values and then you have choosen values. EH doesn’t like Christian pacifist but he respects them for rational. He respects induvudal sermon on the mount.
CENTRAL Question:
(Hennis, 1988) Weber’s Central Question: what is the meaningful life?
Menschentum… I think, I am not sure how to translate this maybe “the quality of being human,…” I am not sure, but this is definitely what Hennis central question is about, Weber is concerned with the human,… I think thats the answer,…
(Hennis, 1988) Weber was passionate but we should not believe his personal letters to be cannon. Karl Marx revised, revised and then revised his ideas so we should not obsess about chicken-scratched outlines of shooting Poles or opposing Versaille.
1) Nation is valued by Weber as a life order:: what kinds of people does the social arrangement produce. SO what kind of person is the German peasant: which will lead to the Germans to go west where as the Poles will go to East Elba: Germans like freedom according to Hennis. The promise of freedom caused German migration.
2) It is a sign of life orders, how a particular life can be developed. Germany is a place, political order, high culture, within which certain personalities can be generated which have value: they make ethical choices: you have clear conceptions of your ends: this is more likely to occur in the powerful German state. It isn’t a life order, but a multi-class claim that they are the same: Junker, peasant class, Weber never bought into the ethnic commonality. Hennis: has the problem of whether Weber is a defensable thinker. Weber was brilliant but he didn’t say exactly what he should have according to Hennis.
There is a central question throughout Weber’s works. It is in the dissertation. The central questions IS ever present.
Weber’s central question: is the triumph of the souls of men? That Weber is a Hedgehog (one big moral idea) to use the Berlin and not a Fox (many small ideas).
(Hennis, 1988): (Freiberg Inaugural Lecture 1895) is wonderful: Weber is interested in what kind of human beings in the East Elbian situation this leads to nationalism. Hennis: 1st Chapter and 2nd Chapter are useful but he’s a bit too internal: not cogent as a writer.
Hennis ideas about Prestige are useful. Honour = Prestige. Weber has the three dimensions: Power, Class and Status
Status is related to status group: stand each has their peculiar sense of honor status groups about honour. The nation is about status group with prestige> He is arguing an ideal interest in maintaining your status and your honour. It is a class system. Nobleman has to justify their economic function: as soon as you start justifying……
You cannot offend my honour: you see the conception in refusal to sign the armistice: this is not something that a rational means end can be applied. The prestige concept: it becomes more intense when Weber’s Germany confront other world powers: Weber is not conscious of Austria or France. Weber saw Russia, Britain and US as the real powers.
Weber: (Freiberg Inaugural Lecture, 1895): the youthful prank of Germany. Weber uses the organic metaphor: but he projects it into the young nation: it has to force the old out ie Junkers. BUT Breuilly says Weber doesn’t care about nations, members of groups that have youth. Weber is a methodological individualism> Breuilly says that the Inaugural Address is a crude, arbitrary and Weber later says he was ashamed and could have expressed more clearly his ideas in that lecture…..(Hennis, 1988) would have agreed.
He mentions this explicitly with reference to his brief membership in the Pan-German League (1893-1899). Because of Weber’s peculiarity in only focusing on certain aspects of what Hennis defines as “Liberalism” (belief in removal of limitations, progress with time, universality of values) he can at best label his writings as those of a “voluntaristic Liberalism, more properly perhaps of a liberal voluntarism closely bound to freedom” (197). Hennis’ inability to label Weber as “Liberal” in his sense of the term ultimately demonstrates Weber’s actions as coinciding with his theoretical writings. Weber’s “Liberalism”, thus, is separate from “contemporary Liberalism” in its “passionate efforts on behalf of impartiality” (202).
I think Weber certainly was not a liberal in the sense of believing in progress. He did support free markets and strong parliaments and permissive laws.
TOPICS:
Political Power Junkers to the Bourgeoisi
Agriculture East Elbia Economics
Real Politik the Importance of Nation should serve the purpose of national
Pan-German League (Mommsen, 1984) (controversial)
It would seem strange that Weber not stay longer in a bourgeois organization that placed “national values” at the core of its agenda. According to Wolfgang Mommsen, Weber left the League because it catered too strongly to Junker interests and was not “uncompromisingly national” on the Polish question. Mommsen never explicitly defines Weber’s “nationalism,” only to remark that his “nationalist” views changed with respect to the Polish. He holds that the “national idea” was Weber’s ultimate norm, but that his “nationalist thought transcended the epoch of his generation” in his ability to know its limits and change its emphasis (Mommsen 63-64). Thus, he concludes, “it is unlikely that Weber would have long remained associated with the league as it moved increasingly in the direction of…irresponsible chauvinism. Moreover, he was never totally in agreement with the radical Polish demands of the Pan-Germans” (55). While Weber would later come to criticise the League’s aggressive foreign policy intents during the war, to think of him as “illiberal” is exactly as Chickering describes – a “value judgement” that does not take into account different interpretations and means of achieving a particular goal. (303)
A good and informed section on the Pan-German League and Weber’s links with it.
(Radkau, 2005): what he says about the Inaugural Lecture. Weber is incoherent, worker politic is bluster: weak economic argument. (Radkau, 2005): landowners construct how economics. (Radkau, 2005) (Breuilly)
Real Politik: was a prevalent position: BUT Weber is an early nationalist of this agreessive patriotism> (Radkau, 2005): in Weber’s early life: Weber wasn’t reflecting the mood he was anticipating on shaping it. Weber wasn’t just spouting clichés. Mommsen/Radkau view on the Inaugural Lecture is superior according to Breuilly: read them.
Weber & Iron Cage: haunted by pressure of time. Workaholic: ‘time was money’
(Radkau, 2005) reveals that life is not a consistent entity: it is a confused, broken life has several phases. The better you know Weber, the more you like him. Weber’s over analysis caused him much personal illness.
Weber defines nation as a “community of sentiment, which could find it adequate expression only in a state of its own, and which thus normally strives to create one.” Weber argues that Tonnies is a cretin/ethno-cultural nationalist boob.
Stargardt argues that Weber begins/“expresses the starting point for open liberal politics.”
Stargardt is Weberian AGAINST controversial Mommsen who has forcefully argued that Weber “was a Liberal in Imperial Germany and model of primacy of politics tilts the nation-building role of the state over towards geopolitics, at least during and before WW1 – hence Weber’s ALL or NOTHING predictions of the fate of German nation in great power conflicts. The federal state was explicitly submission to a dominant national group control: Constitutional support for Prussia hegemony.
Weber must have known about Bauer/Renner.
Renner’s personality principle: a strong state segregate cultural difference form the sphere of a national conflict to the domain of individual rights.
Weber and Bauer end up supporting Statism: historical perspective the radical liberal politics of multiculturalism – has potentially illiberal social foundations. The problem is that the state is responsible for managing cultural identities against an ethnic nationalism: but both Weber and Bauer know that the state should also be founded in social sentiment. Popular sovereignty lies at the centre of all democratic politics according to (Stargardt, 1996). Weber and Bauer’s susceptibility to the Gemeinshaft causes much ambiguity: Tonnies mourned the end of romantic medieval community.
Thesis: Stargardt argues that Weber and Bauer are left in a position shaped by what they thought they opposed. (Stargardt, 1996): you cannot escape the validity of Tonnies dichotomy of Gesellshaft & Gemeinschaft.
Weber is an instrumentalist not actually interested in multinational models for Germany itself for example. Counterfactually, what would Weber have said if he was an Austrian? I’d guess he’d be an Austro-German unificationist??? Hard to say.
Bauer & Weber both use Tonnies dichotomy ie. Gemeinschaft and Gesellschaft.
Karl Renner/Otto Bauer + Weber (Stargardt’s argument) they concerned about opposing multicultural states. Weber has an instrumental support for Polish nation-state was to fragment Russian potential hegemony (multi-nation empire). Weber admired Renner/Bauer even if they were Austro-social-democrats, for they viewed citizenship values and norms based on belonging rather then the Tonnies ethnic approach that Weber abandoned in 1912 at the second German Sociologists Conference. Weber doesn’t like the Poles because they aren’t committed Germans.
WRONG ARGUMENT: the Weber is obviously an instrumentalist why would Weber support the Austro-Hungarian empire’s maintenance post-1918 (probably for the same reason that Bismarck et al did) to nullify the SLAVS, Weber consistently hated the Poles and he was willing to sacrifice the Austrians anyway because they aren’t part of his Gesellshaft, political sphere???
Poland ISSUE shift in 1919.
POLAND was participating in 1857, Prussia, Austria, Russia. Poland Danzig is German but part of Poland.
(Mommsen, 1984) reveals that Weber made a statement about Poles in Germany: that the first Pole to claim Prussia should be SHOT. BREUILLY REFERS to Weber makes a one off quip it shouldn’t be blown out of proportion in 1919: Weber had returned to 1895 (German for Germans).
CAUSE 1) his biases on the question of nationalism: His methodology does not accommodate scrutiny on the issue of the German nation. He quite consciously did not question whether the national idea could fairly be judged as the highest guiding principle of political action.(62pp) WHAT IS AT THE ROOT OF WEBER’s position on nationalism?
Weber is never ever to develop a general theory of nationalism. This is because his view of nationalism is value laden (see 2 Reasons). His highest value is to that of the German nation and its place amongst the nations of the world.
Weber Prestige & Power Arguments. Weber overvalued the principle of power and their ideal fulfilment in the concept of the nation that was characteristic of the imperial epoch – an overvaluation that was to lead to old Europe to catastrophe.
(67pp, Mommsen, 1984).
Objective: Germany as a global political actors; WEBER believed that POWER was the highest goal and CULTURE was secondary.
Weber sought to impose his general will on others, in defiance of other nations.
Weber disliked small nations: GERMANY had to be a “voice about the future of the world.”
Germany has to carry on the war in order to win recognition as great power in the idle of Europe. Protect our honour for its descendents shake off the chains of political serfdom and vassalage.
HOW can Weber be scientific if nationalism is not placed under the same scrutiny as bureaucratization, political leadership?
Essentialist and instrumentalist perspectives on culture and nationhood; political arguments in favour and against; is there, or can there be, a European culture?
Conception of Cultural Bonds
a) Essentialist approach: nationalists believe in the innate value or goodness of a language and therefore requires cultural protection against others. Has instrumental purposes consequently….Herder
b) Instrumentalist/Functionalist approach: nationalists believe in the utility of a belief for political ends. The instrumentalist conception of cultural bonds is more detached, objective and built upon internal and external identity-markers.
The essentialist versus instrumentalist conceptions of culture cannot be ignored with regard to a European cosmopolitan culture. The essentialist approach would argue for the innate goodness of particular culture and therefore requires cultural protection against others. This is the irrational, emotionality of culture. If a culture can be viewed simply as having a value all its own then Fichte’s Prussia address in 1806 Addresses to the German Nation is sound.[1] Essentialists have the tendency to delimit cultural value within the frame of nation state, although Fichte was writing during an unstable time in German history, he embodies ethnic nationalism at its most repugnant, hierarchical and illiberal according to Abizadeh.
It is later echoed by Max Weber, a fellow German nationalist a century later.[2] The Weberian ideal type of the nation “means, above all, that one may exact from certain groups of men a specific sentiment of solidarity in the face of other groups.”[3] This is why Max Weber viciously attacked Naumann’s Mitteleuropa arguing in a letter that “‘Mittleeuropa’ means that we shall have to pay for every stupidity with our blood…committed [to] the thick-headed policies of the Magyars and the Vienna court…Can we bind this all together so that each part has the feeling: I can live with these stupidities, since the other one is here suffering with me?”[4] While Weber is a product of an era of realist Darwinian thinking, cultural essentialism is still remarkably agile despite the lessons of the 20th century.
Herder (1860s) was mobilizing in the 19th century. He emphasizes the linguistic reality and the normative worth of community (German poetry, romanticism, the need to preserve their existence).
Is the nation something that exists at a single point or is it something that passes through time? Or is it that individuals believe the nation exists?
The question is where is the value of the community? Is it good to preserve the Italian language? Is this a normative question? Is it itself a value or is it just a useful tool in achieving other goals?
EMPIRICAL FAILURE of NATION_STATE IDEAL:
At the same time cultures are constantly evolving so a European culture may be something possible in the long-term, but even then it might not be desirable.
The instrumentalist conception of cultural bonds is more detached, objective and built upon internal and external identity-markers. Without going into detail, the dichotomy between the essentialist and instrumentalist approaches is really only useful in pointing out that; essentialists often have the ulterior motive of self-preservation and maintaining – in the Weber/Fitche example – prestige: their essentialist objectives have instrumentalist consequences.
Freiburg Inaugural Address (1895)
Weber’s “early nationalism” from his Freiburg Inaugural Lecture: “we economic nationalists measure the classes who lead the nation with or aspire to do so with the one political criterion we regard as sovereign. What concerns us is their political maturity…their grasp of the nation’s enduring economic and political power interests…” (Lassman and Speirs 20). The focus on economic nationalism, to Norkus, has been overlooked by other writers such as David Beetham and Kari Palonen, specifically the view of a great nation possessing “prestige” by using its relative economic strength to control world markets (Norkus, 2004 401).
(Norkus, 2004)
In his later critiques of Pan-German nationalism, “the ‘economic’ idea was replaced with a more subjectivist idea of the broadest status group struggling for a higher place in the regional or world estate order of nations. In this struggle, economic and military power is not the only efficient ammunition” (408). Norkus places Weber’s political-economic “nationalism” in the modernist camp of Anderson, Gellner, and Hobsbawm, but has difficulty labelling his political-sociological “nationalism”
(409-411).
Freiburg Inaugural Address (1895) as VALUE-LADEN? Breuilly says that Weber set out to discuss about national interests and yes it was political. But it was set out to parameters he sets out in the opening: “an Inaugural Address is an opportunity to set a personal stand-point.” He was arguing for the improvement of the economy: it was his means rather than his ends> he uses the national economy to critique the Poles in Germany. Except for the hilarious the Bourgeois isn’t strong enough. Working class aren’t worthy.Economic proposals for East Elbia are impractical. (ivory tower)
Economics: science is international but the goals are nation. The moment you use scientific evidence it will be nationalist because that is your value. International economics but rational ends. (page15: but as soon as it is value)
1919 Intellectual or Incoherent Shift: the creation of the Kingdom of Poland: East Elbian lands. Weber believes East Elbia is German. Social scientists are speaking out against. He is stepping back to 1895 inaugural address. (Crucial)
(Freiburg Inaugural Address 1895): Polish state? Did he want a Polish state? It wasn’t an issue: Germany is the key issue: Ethnic composition of East Elbia. His view changes during the war: Weber does not care about Poland until it has utility for his ultimate end. When German owns the Polish national-lands: With Russia out of the war: Germany should create a Polish state that is close to us.
BUT in 1905 Dragmonov: Poles in Russia. This changes that the Russians are struggling with Poles too. So Weber makes a fundamental intellectual shift, they offer a new framework for cultural autonomy.
(Radkau, 2005): explain Weber on his personal experiences. War triggers the debate for him.
Nationalism, Ethnicity: DEFINING & MEANING
To what extent, if at all, Weber developed clear concepts and theories of ethnicity, nationality, nation-state and nationalism.
[“Nation”] seems to refer…to a specific kind of pathos which is linked to the idea of a powerful political community of people who share a common language, or religion, or common customs, or political memories…it is proper to expect from certain groups a specific sentiment of solidarity in the face of other groups. Thus, the concept belongs in the sphere of values. Yet, there is no agreement on how these groups should be delimited or about what concerted action should result from such solidarity” (Roth and Wittich, 398, 922)
(Guibernau, 1996)
Chapter 1 Nationalism in Classical Social Theory:
Heinrich Von Treitschke (the demagogue). Influential to both Durkheim & Weber.
The State:
1) The people legally united as an independent power. The state is a) engaged in supreme moralizing and humanizing agency b) there is no authority above the sate.
2) The state exerts its power through war. Treitschke denies the state as the only entity capable of maintaining a monopoly of violence….State must have territory.
War is the defining grandeur of perpetual conflict of nations and it simply foolish to desire the suppression of their rivalry. ONLY under war do people become heroic nationalists.
The interests of the community are above the individual: he is Machiavellian in his approach to policy aims as designed to protect the nation first and fore most. The idea of state as supreme entity guided ‘not by emotion but by calculating, clear experience of the world. The state protects and embraces the life of the people, regulating it externally in all directions.
On German Unification:
Three possible Germanies: Prussia is the hegemony always.
Confederation of German states
US federal model three branches of government.
Unitary German state.
On Nationalism. Patriotism is the conscious cooperating with the body-politic, of being rooted in ancestral achievements and of tormenting them to descendants.
Appeal to history. Consciousness of cooperation: handed down from generation to generation.
Two Powerful Forces:
The tendency of every state to amalgamate its population, in speech and manners, into one single unity.
Impulse of every vigorous nationalist to construct a state of its own.
Nationalism should be real or imagined blood-relationship. All real poetry came out of great nationalism. The largest state is the most powerful state. Large state is necessarily nobler and culturally superior to smaller ones. Larger states can impose themselves as superior states and promote their culture and art for granted. Smaller states may usurp larger ones.
The idea of a world state is odious; the ideal of one state containing all mankind is no ideal at all… the whole content of civilisation cannot be realised in a single state. Every nation over estimates itself and more importantly that ‘without this feeling of itself, the nation would also lack the consciousness of being a community.
Will only powerful nations be able to assert themselves in the future?
Max Weber
The state as ‘a human community that (successfully) claims the monopoly of the legitimate use of physical force within a given territory.’ State has the right to use violence. Politics is striving to share and distribute power either among states or among groups within a state. Clearly influence by Treitschke’s violence Die Politik.
The distinction between nation and state + theory of values to nations of culture as a basis for the difference arising between nations.
Ethnic troup corresponds, to one of the most vexing since emotionally charge concepts; the nation as soon as we attempt a sociological definition: He argues “We shall call ethnic groups those human groups that entertain a subjective belief in their common descent because of similarities of physical type or of customer or bother or because of memories of colonization and migration.
Ethnicity shit here
The NATION > PRESTIGE: the cultivation of the nation is the cultivation of superiority. The culture values of the group set off as a nation. The propagation of national ideas just as those who wield power in the polity provokes the idea of the state.
Solidarity in the face of other groups, For Weber, national solidarity among people speaking the same language may be just as easily rejected as accepted, Instead he suggest that solidarity may be linked to memories of a common political destiny. The nation as community of sentiment which would adequately manifest itself in a state of its own. Therefore nationality is not sociological distinct concept for Weber: it ought to be defined not from the standpoint of common qualities that establish the nationality community, by solely form the goal of an independent state: The correct relationship between state and nation, in which the latter identified by language and culture is of greatest importance for the state’s power status.
The nation is not identical with the people of the state the membership or a given polity. Numerous polities comprise groups among whom the independent of their nation is emphatically asserted in the face of other groups, or on the other hand, the comprise parts of the group whose members decide this group to be on homogenous nation.
The nation can exist outside of the state. That the nation and state do not have to fit perfectly. The more power is emphasized, the close appear to be the link between nation and state. Weber relates the significance of power within politics: the nation to the ideal of power in the Freiburg Address (1895) there is the idea of cultural nation. Mommsen stress that Weber had moved far forms the idea of the purely cultural nation. He was only able to accept the national idea in associating with a governmental system that pursues power politics on a grand scale.
The power structure allows for Switzerland to remain neutral. No great power wants to upset the others by making claim to Switzerland.
Weber sees the nation as part of the struggle: the eternal struggle for survival. The struggle for self-determination has favoured modern Western capitalism. THE STRUGGLE is a Nietzsche-ian idea that (Henniss, 1988) builds on.
The Unification of Germany 1871 influences Weber’s thought. The preservation of nationality as the highest principles. Weber did not formulate a theory of nationalism but adopted a ‘nationalist’ attitude through his life. The Elbia Case Study: Junker patriarchal system is being transformed and labourers allowing the latter a relative degree of independence and security were collapsing everywhere.
Slav race either possesses as a gift from nature or has acquired through breeding in the course of its history is what has helped them to expand in this zone. (37pp). Weber shared the nationalism enthusiasm in the goal of preserving a German nation. Making the German Reich a great power amount he European would power as the only justifiable objective of the war.
Weber’s national feeling was aroused by the Allies’ peace conditions. When he opened his lectures in Munich, he spoke with passionate national urgency: ‘we can only have … ac hoc goal: to turn this peace treaty into a scrap of paper. The nation and its power in the world remained the ultimate political value for him.
(Beetham, 1974)
Nation is subjective phenomenon: “a nation exists where people believe themselves to be one, or to put it in less circular manner, where people have a sense of belonging to a community which demands or finds its expression in an autonomous state” (122pp, Beetham) Weber is interested in nations that attempt to take power.
Nation is rooted in objective factors:
common race b) language c) religion d) customs.
Communit of language (Sprachgemeinschfat) “which he regards as the most common objective basis, was not a universal feature: Swtizerland, Canada.
“Nor did the existence of such objective factors on their own make a nation.”
RACE IS THE LEAST IMPORTANT
3 Different Elements of the Nation:
1) Objective common factor between people, which distinguishes them from others
2) where this common factor is regarded as a source of value and thus produces a feeling of solidarity against outsiders
3) this solidarity finds expression in autonomous political institutions, co-extensive with the community or at least generated the demand for these.
Racial assumptions about the difference between Germans and Polish in his Freiburg Address regarding physical and psychical racial difference.
“With racial theories,’ he said at a meeting of the German Sociological Association held to discuss the subject, ‘it is possible to prove or refute whatever you like.’
Language is the most common factor: belief in the exclusiveness of their language community seizes the masses as well, and national conflicts become necessarily sharper, bound up as they are with the ideal and economic interests of mass communication in the individual languages” (123, Beetham).
“the democratisation of literary culture, language played an increasingly important part in national sentiment, possession of a common language was not itself everywhere paramount.” (124, Beetham).
Irish versus English = Religion.
French Canadian, Swiss and Germans in Alsace = common customs, social structure, shared values, ways of thinking.
“The French Canadians’ loyalty towards economic and social structures and customs of the United States, in the face of which their own individuality was guaranteed by the Canadian state.” (124, Beetham).
Kultur difficult to define: value attitude towards the world. “The sense of Kultur that we are concerned with here is a narrower one: it indicated those particular values which distinguish a group or society from others – which constituted its individuality, Weber does not confine the term ‘Kultur’ narrowly to artistic or literary values: it embraces values of whatever kind –manners, character, patterns of thought (Geist)
Beetham believe sthat the concept of Kultur provides the bridge between Weber’s empirical and normative conception of the nation.
Empirical = Kultur embraced both the objective difference of language and custom
Subjective appreciation of their distinctiveness, that constituted the essence of a nation, and against which ‘reasons of state’ were often powerless.
Value concept = Kultur is most obvious in that it embodied a conception of minimal literacy or artistic standards, in relation to which certain groups or people could be judged as uncultured. “the self-conscious development of group distinctiveness and individuality that was equally a criterion of ‘Kultur’ was also a value for Weber: it indeed it can be regarde as an extension of his central commitment to individualism at the personal level, sicne it was based upon the same belief that distinctiveness was more valuable than uniformity, and that “capiticy to articulate distinctive values was among the highest human achievements.
“It was as a vehicle for, and embodiment of, Kultur in this sense that the nation had supreme value for Weber.” (127, Beetham).
NATION = Kultur, STATE = Power: “The nation was concerned with the realm of ‘Kultur’; the state was the realm of power. Weber’s conception of the nation state was that though nation and state belonged to fundamentally different caterogires, they were also reciprocal.” (128, Beetham).
If you reject power then you cannot be a nation. Nationality requires political association, requires political power
Max Weber: The Nation
The Nation is power prestige – historical attainment of power-positions.
Power prestige: All groups who hold the power to steer common conduct within a polity will most strongly instill themselves with this ideal fervor of power prestige. Material and direct imperialist interests
This power prestige is intellectually created with specific partners of a specific culture diffused among the members of the polity. The nation is that certain groups of men act in solidarity against the other groups. “Thus the concept belongs in the sphere of values” (22pp, Hutchinson Oxford Reader Nationalism)
Nation is not identitcal with the people of a state. There is a difference between nation and state. Numerous polities comprise groups among whom the independence of their ‘nation’ is emphatically asserted in the face of other groups OR they comprise parts of a group whose members declare this group to be one homogenous ‘nation’.
A nation is not identitcal with a community speaking the same langage: that this by no menas laway suffices is idnividaul by the Serbs and Croats, North Americans, Irish and Englihs.
(Guibernau, 1996)
Ethnicity (1912)
Subjectively perception of race and similarities. Ethnic membership does not constitute a group; it only facilitates group formation of any kind, particularly in the political sphere. It is the political community that artificially organized: this inspires the belief in common ethnicity.
State creates a presumed identity.
The ethnicity tends to persist even after the disintegration of the political community, unless drastic difference in the custom, physical type, or above all, language exists among its members.
A political community can engender sentiments of likeness which will persist after its demise and will have an ethnic connotation; but such an effect, Weber argues, is most directly created by the language group which is the bearer of a specific ‘cultural possession of the masses.
Weber looks at ethnic groups not nationalism. Nationality does not require a common ethnicity: in fact a share language is pre-eminently considered the normal basis of nationality. (33pp).
The significance of language is necessarily increasing along with democratization of state, society, and culture. Masses participation into a culture.
Ethnic Groups (Whimster, 2003, 2003; Beetham, 1974)
Weber’s approach in Ethnic Groups is worthy of analysis because it is more vigorous than the Nation piece and there are parallels with his social constructivist interpretation of the nation.
Weber argues in Ethnic Groups that ethnicity may appear to be a preexisting natural phenomenon but is created by a political association. It becomes the conspicuous differences that divide groups into political loyal segments for Weber.[5]
He reverses the intuitive causal relationship that would suggest ethnicity engenders political association. For Weber, “artificial distinctions, politically imposed, lead to the myth of a common ethnic descent”[6], therefore, for example, the Twelve Tribes of Israel were politically imposed.
Ethnicity as a social construct would have been difficult to grasp in the early 20th century when social Darwinist arguments were being advanced. His instrumentalist view in ethnicity’s construction is shaped by this idea of power and consequently prestige as operative forces in Weber’s thinking.
One needs to distinguish what Weber argues ethnicity IS (a belief in common descent) and WHY it exists, where he argues that (probably) it is a product of political domination. However, that may lay well in the past and not play a central role later; which means that those later ethnic beliefs cannot be explained in terms of political instrumentalism. (Primordialism -> Modernists) The question then arises, what sustains such beliefs once the political cause is removed? Clearly such beliefs do enable forms of cooperation which are of mutual benefit and that may be the reason they continue to operate.
The nation and ethnicity are viewed through an instrumentalist lens(wrong): they are spaces for the struggle for political domination. There is no moral, racial, ethnic or national reality outside of the state’s power.[7]
PREOCCUPATION with DIGGESTIBLE CONCEPTS: Despite being a social scientist, Weber was also a value laden individual.[8]I think Weber’s comment on this sentence would be that social scientists who considered themselves not to be “value-laden” would be deluding themselves.
That is why Weber’s cursory analysis of these two concepts suggests not only an instrumentalist approach but also Weber’s intellectual interests. The reason that Weber largely ignores these two concepts is due to their subjective nature and thus he takes them for granted.
NOTE that it is impressive for Weber’s time to believe Ethnicity as constructed.
For Weber, the concept of Gesellschaft or political association can be grasped through his rational-legal logic but the Gemeinschaft or nation does not have an “empirical quality common to those who count as members of the nation.”[9]
The nation and ethnicity are not generalizable concepts: why study something amorphous? As abstract, “ambiguous” concepts, it would lack scientific rigor to address the national and ethnic ‘feelings’ seriously.
More importantly, we must presume that these ideas were a given and for Weber not an area of interest worthy of publishable in-depth scientific analysis.[10]
Breuilly doesn’t agree with above statements. Also, Weber spent a good deal of time studying “subjective” beliefs, above all world religions, which then became vital components of broader social relationships and actions. My guess is that his interests in how modernity came about, that is large-scale political and other relationships, found more could be explained in terms of world religions or the formation of extensive economic markets or large, bureaucratic-military states, than in terms of ethnicity.
Weber wrote about what interested him – for example – the Protestant work-ethic. This may explain his view of that the nation and ethnic groups were secondary to his preoccupation with state power.
In addition to the value laden individual argument; there may be more than just a power and prestige aspect to Weber’s instrumental approach to nationalism. Weber was a product of his time, thus his idea of Nations and Ethnicity engenders a top down approach antagonistic to mass movements.[11] Since both the nation and ethnicity are conceptualized by Weber as imposed or constructed, this value judgment fits cleanly into Weber’s bourgeois perspective.
According to Beetham, Weber is a bourgeois nationalist who was “not only [bound by] the concept of the Kulturnation, but also the idolatry with which the bourgeoisie pursued the national culture as the final value.”[12] Nationalism suppresses the proletariat and thus has a practical political value for bourgeois Germany.
Weber believed that there would always be lower class groups; that only elites can actually run states; and that under modern conditions in Germany, these elites should primarily be drawn from the educated middle classes. However, he also thought that the labour movement would fare better in such a state than one dominated either by pre-industrial elites or the demagogic intellectuals who came to the fore in socialist parties. What is more, in such a society there would always be opportunities for able people of working class origin to rise up the social scale.
For Weber, “the nation is anchored in the superiority, or at least the irreplacability, of the culture values that are to be preserved and developed only through the cultivation of the peculiarity of the group.”[13] Thus, the nation is designed to protect culture and ethnicity against erosion from forces such as socialism.
The Ultimate End
RATIONALE OF NATIONALISM: What is curious, then, is that although Weber was a realist, pessimist and a genius, he was also a German nationalist. Distinct from the value laden social scientist, the personal and political Weber was committed to German nationalism of the post-1871 German unification era.
BREUILLY: A very interesting essay which tackles some difficult questions. I think I am persuaded by your points on the two fragments on nation and ethnic groups, on Weber’s elite and power perspective, and on the separation of his nationalism from any rational social science work.
I do think there are problems however in your points about his instrumentalism and the irrationalism of his nationalism.A), Weber insisted that ultimate values are non-rational. Valuing wealth or eternal salvation or power or beauty above other things are choices. One can be clear rather than vague, committed rather than indifferent, and consistent and rational in pursuit of such values (and for Weber clarity, commitment and consistency seem to have values in their own right) but it is no more or less rational to be a nationalist than a socialist or a Christian. I think Weber would ask you in turn: what ultimate values could I commit to which would be any more rational than those of German nationalism? And can one live a meaningful life without making some such commitment?
If there was a fragmented German nation for the first seven years of Weber’s life, one would scarcely know it in his writings. Following a rational-legal perspective, as long as the means are rational, Weber’s artificial German nationalism can and was vigorously defended given changing conditions.
It was defined through three episodes; first, the discrimination against Polish immigration in East Elbia, second, German nationalism during the Great War and finally, his reaction against the Treat of Versailles. Continuous through his political writings, nationalism for Germany and against other nation-states is only addressed for instrumental reasons of political power and prestige based on rationally deduced pragmatic arguments. For example, self-determination for the Polish nation Well – the formation of a semi-autonomous Polish state for that part of Poland which Russia had ruled and which Germany had occupied during the war. during the Great War is instrumental in subverting Russian dominance in the East. Weber is merely obsessed with German political power in relation to the question of nationalism, thus he produces only two social science papers on the subject.
(Whimster, 2003, 2003)
WEBER Power & Prestige
A) “Now, in contrast, we have to say that the state is that human community which within a defined territory successfully claims for itself the monopoly of legitimate physical force.” (131pp, Whimster, 2003)
B) Weber divides that nation from the state.
“Numerous polities comprise groups who emphatically assert the independence of their nation in the face of other groups; or they comprise merely parts of a group who members declare themselves to be one homgenous nation (Austria for example.
C) Nations can have common political destinies: Alsatians “with the French since the Revolutioanry War which represents their common heroic age, just as among the Baltic Barons with the Russian whose political destiny they helped to steer.” (147pp, Whimster, 2003).
D) FIGHTING FOR ONES COUNTRY. KILLING FOR the German nation. THE
QUESTION OF LOYALTIES. German Americans would unconditionally defend America.
D)b) Nationalism VARIES WITHIN THE NATION:
“It is a well-known fact that within the same nation the intensity of solidarity felt toward the outside is changeable and varies greatly in strength. On the whole, this sentiment has gorwn even where internal conflicts of interest have not diminished. Only sixty years ago the Kreuzzeitung still appealed for the intervention of the emperor of Russia in internal German affairs; today, in spite of increased class antagonism, this would be difficult to imagine” (149pp, Whimster, 2003).
D)c) TYPOLOGY of NATIONALISM
A sociological typology would have to analyse all the individualkinds of sentiments of group membership and solidarity in their genetic conditions and in their consequences for the social action of the participants. This cannot be attempted here. (149pp, Whimster, 2003).
E) Peculiarity of the group: INSTITUTION OF CULTURAL PROTECTION as means to power.
“Another element of the early idea was the notion that this mission was facilitated solely through the very cultivation of the peculiarity f the group set off as a nation. Therewith, in so far as its self-justifcation is sought in the value of its content, this mission can consistely be thought of only as a specific ‘culture’ mission. The significance of the ‘nation’ is usually anchored in the superiority m or at least the irreplacibility, of the culture values that are to be preserved and developed onoly through the cultivation of the peculiarity of the group.”(149pp, Whimster, 2003)
Therefore: Weber is making an intellectual account of how to deal with the Polish Question. The polish in question may be changing: Weber condemns the East Elbian poles in 1896 while he is willing to accommodate the Poles in the 1910s. On his death bed, he is says he hates Poles again.
Polish are a problem
Policy prescriptions are rationally deduced.
There are a series of possible policy ends.
You can defend rationally any policy end if it is rationally deduced.
(Weber, 1886: Friedburg Inaugural Lecture) Polish Question-> border restriction NOT possible. Agrarian communal policy for German re-settlement doesn’t WORK. His ultimate value is still for the preservation of the German nation. It doesn’t have to be rational. But the means do have to be rational: in this case they clearly are rational given available information.
He isn’t a pragmatic politician. He didn’t compromise on the core theory of his own nationalism. But he does draw different conclusions on the validity of other nationalities in order to protect his own. He is never able to draw a general theory of nationalism because he is a German and can only truly understand the German case.
Germany is better than all other nations: because Weber is German and his values are a product of who he is.
There must be a rational intellectual grounding to any pragmatic decision. Need to define our terms: pragmatic.
Pragmatic: denial of the value/fact distinction.
SCIENCE/VALUE DISTINCTIONL W7
Weber’s Values: doesn’t matter what the ends are: good scientific knowledge will allow objective science. If people can rationally understand, then it will be objective reasoning: until someone finds something more rational
The Protestant Work Ethic and Capitalism
Protestant Work Ethic (an Ideal Type: it is exaggerated because not all Protestants has a good work ethic). This ideal type is use to study a subjective value of the people being studied. Their values in a world of infinite chaos -> these people are trying to clutch their meaning on their world. Sociology is agent focused or value focused.
Significance is imposed on the world. People place significant on the world. Capitalism + Protestants makes an undersand . You can’t understa one ideal type: capitalism is something that exists, you have an ideal type of capitalism
Of all things Weber could have studied: why did he study the Protestant Work Ethic? Because it was Weber’s question: “how did a specific form of rationalism emerge in the Western World?”. His values=ends lead to that study.
WEBER VALUES:
Ultimate values cannot be rationally defended: “here I stand I can do no other” : Berlin: we can choose our positions in a pluralistic world or they choose us, their way we are value-laden as humans always are.
If you weren’t born a German would have still be a German nationalist? Weber would say that is absurdity.
Weber is haunted by instrumental rationality because people don’t have a value in such a system. Weber believes that most people don’t have values anyway.
Weber is relentlessly self-critical: constantly testing his values.
Weber’s conscious commitment to subscribing to his ultimate value: German nationalism.
‘Objectivity’ (1904)
For Weber there is NO final court of Objectivity (Whimster, 2003, pg 308)
“There is absolutely no ‘objective’ scientific analysis of cultural life” pg 374
The best that can be done is a construction of reality according to cultural interest. Science arose practically and can offer knowledge of the Significance of a decision.
The role of social science then is to distinguish between perception and judgement.
“The prime work of our journal… [is] the scientific investigation of the general cultural significance of the socio-economic structure of human communal life and its historical forms of organisation” (pg 370)
Ideal Types
There is a gulf between abstract/ theoretical and empirical historical research for Weber, however, given this intractability thinks that can be done is to construe reality according to our cultural ideals. Outlines ‘ideal types’ as a means (pg 389) successfully “develop knowledge of concrete cultural phenomena and their context, their causal determination and their significance” (pg 389). Whether ideal types are purely thought experiment or conceptual construction cannot be determined.
They are Utopian, and ‘nominal’ but help to determine judgement, perhaps a ‘guide’ to determine the best route to an END (this makes it Normative in some sense)
“The ‘objectivity’ of social scientific knowledge depends rather on the fact that the empirically given is always related to those evaluative ideas which alone give it cognitive value, and the significance of the empirically given is in turn derived from these evaluative ideas” (Pg 403)
“The proposition that the knowledge of the cultural significance if concrete historical relationships is exclusively and alone the final end, along with the means, the work of conceptual formation and criticism seeks to serve” pg 403
SCIENCE ENHANCES VALUES: Science can contribute…methods of thinking, the tools and training for thought…to gain clarity in the making of one’s value judgements by thinking of them rationally. (Gerth and Mills 143, 151)
(Brubaker, 1984) Limits of Rationality.
Weber makes 2 distinctions:
1) formal instrumental rationality,
2) substantive end rationality (you are conscious of rationality).
Subjective rationality applies to formal and rational
Objective rationality is not
If there a numberous ends then not all of which not all must be rational
Ringer’s text is about the methodology. Its about his theories of rationality.
We have 4 kinds of action: traditional, affectual, instrumental, substantive
Traditional: we’ve always been doing this.
Affectual: we are driven by our emotions.
Instrumental: it has a utility not necessarily a value
Substantive: we want to help people taking into account people into rationality.
On the first, Weber certainly thought that many relationships and social interactions were non-instrumental. His very division of forms of action into the emotional, the traditional, the rational-instrumental and the rational-substantive indicates this. Ethnicity may have endured simply through tradition and emotion (and nowadays, some would argue, endures because it enables valuable forms of cooperation).
Policy is about likely causal connections in the future. There can be no objecrtive reality.
Weber is Kantian in that “there is chaos but we bring categories” BUT Kant believe in autonomy & substantive rationality while Weber believes in ends that are incompatible.
Weber -> tracing out causal analysis -> Lawyers argue that there was a drunk driver causing an accident: there are many possible variables but the drunk driver is the cause: in the same what that Protestantism causes capitalism.
Policy is presidential predictions about the future:
Based on how things happened in the past -> we can be prudential.
(Brubaker, 1984) “Moral Vision of Weber” says there are two concepts of Weber -> live rationally as possible BUT weber says that reason cannot help all that much -> it is very useless and traditional and affectual forms of action shape our lives.
Brubaker says that Weber is an existentialist.
Ultimate value for Weber is the German nation’s interests.
That value is rational according to Breuilly, but the means to that value/end are rational.
(Between Two Laws, 1916) CHOOSING OUR DEPENDENT VARIABLE:
Weber never chose his ultimate value of German nationalism but there was no alternative choice to be made about it, given Weber’s identity and what German nationalism required.
Weber’s short piece called (Between Two Laws, 1916) highlights this deterministic argument. Weber says one must choose between the Swiss et al – those nations that saintly turn the other cheek[14] – and the German nation that embraces world political power. The choice is a false one, however, since Germany has a distinct role in world political history: namely to struggle against “Anglo-Saxon conventions” and “Russian bureaucracy.”[15]
Prestige and power are necessities.
Germany would be meaningless without them, thus violent unification would be purposeless if the German nation had failed in the Great War.
In this sense, Weber is another of many German scholars and general(?) civilians swept up in prestige for an artificial creation whose value is measured in chauvinistic strength and militaristic grandeur.
This proved to be an unfortunate cocktail for nation-state destruction unique to the German case.
FORMS OF ACTION: His very division of forms of action into the emotional, the traditional, the rational-instrumental and the rational-substantive indicates this.
Conclusions:
CONCLUSION: Is Weber a Fox or a Hedgehog (Berlin, 1969) Ontology of Weber.
Turning to Tolstoy, Berlin contends that at first glance, Tolstoy escapes definition into one of these two groups. He postulates, rather, that while Tolstoy’s talents are those of a fox, his beliefs are that one ought to be a hedgehog, and thus Tolstoy’s own voluminous assessments of his own work are misleading. Berlin goes on to use this idea of Tolstoy as a basis for an analysis of the theory of history that Tolstoy presents in his novel War and Peace.
Hedgehog: universalist one moral value system: universalism of modernity: Brubaker connection about Young versus Old Weber: he is not willing to compromise from his ultimate value; ie. Versaille incoherence
Berlin: universalism is impossible. Hedgehogs are wrong. Berlin states that his version of pluralism leaves no alternative but to say that ‘men choose between ultimate values BUT they choose them, because their life and thought are determined by fundamental moral categories and concepts that are, at any rate over large stretches of time and space, a part of being and thought and sense of their own identity; part of what makes them HUMAN – (Berlin, 1969)
(Berlin, 1969): How do we choose between possibilities?
Considering ultimate values, those values which are regarded as ends in themselves and not as means to other ends, we can do nothing other than commit ourselves. (HERE I stand I can do no other) The problem here is that the choise itself resists, according to this way of posing the question, any kind of rational construction. If this is so, then it is difficult so see how Berlin is distinguished from, Max Weber versus Carl Schmitt, who have stressed the reality of decision in the context of an unavoidable pluralism of values but derive very different political conclusions.
Fox: believes in many small fragmented things: value pluralism: you support this view having read the posthumously published Economy and Society was something he condoned. (Radkau, 2005; Mommson, 1984) fragmented life. Geertz is a methodological individualist looking at various cases.
Thesis of Conclusion: Weber could never be a successful politicians because he was too much of a Hedgehog. There are trade offs and sacrifices between competing values that Weber was not able to make.
(Guibernau, 1996) Conclusion
Weber has a nationalist view despite not have a theory of nationalism.
Weber regarded German unification as a point of departure for a policy of “German world power” The POINT OF CREATING a world policy and stressed that this policy should not be reduce to pure economic principles. Weber linked his nationalism to the power and prestige of Germany. “To recognize and encourage nationalism in other countries would have been against his main interest, that of German primacy.
PROBLEM WITH THE above academics:
They do not provide a dimension of nationalism as a provider of identity for individuals who live and work in modern societies;
They do not develop a clear cut distinction between nationalism and the nation-state;
They offer no theory of how nationalism can transform itself into a social movement general political autonomy; the ability to homogenise individuals living in a concrete territory; notion related to political concept of citizenship and of citizenship rights; duties and Janus-faced character.
Need to make the distinction between nationalism and the nation state.
There is a need for a common homeland.
Analyse how a sentiment of attachment to a homeland and a common culture cab be transformed into the political demand for the creation of a state.
Nationalist capability to bring together people from different social leves and cultural backgrounds; in so doing nationalism show that, however frequently nationalist feeling have been fosterest and invoke ideologically by dominant elites, is not merely an invention of the ruling classes to maintain the unconditional loyalty of the masses, making them believe that what they allegedly have in common is much more important than what in fact separate them. “I do not think that million of people around the world are so naïve: nationalist feelings are not just force-fed to an unwilling indifferent population.
Nationalism is a phenomenon which came into being in Europe around the 18th century.
Need to aim for impartiality on the question of nationalism as a fascist or a normative good.
Of all the writing undertaken in Max Weber’s 56 years, only two significant passages use social science to address the question of nationalism. In order to ascertain why Weber never explicitly formulated a theory of nationalism, this paper will do the following.
First, it will outline the Nation and Ethnic Groups papers and argue Weber forwards an instrumentalist view of these phenomena.
Second, the paper will argue that Weber’s ultimate value is informed by the same subjective pursuit: political power and prestige.
Finally, it will conclude that Weber never formulated a sociological explanation of nationalism for two reasons, a) the concept had not fully developed as central in the modernisation process during his lifetime and b) he recognized the subjectivity and amorphous tendency of this field of study.
2 Reasons why Weber never formulates a theory of nationalism:
A) Nationalism Studies was AFTER his LIFE HISTORY: the concept had not fully developed as central in the modernisation process during his lifetime. It is anachronistic to have expected Weber to provide a theory of nationalism because the concept had not been recognizable until during World War Two. According to Guibernau, there is no systematic treatment of nationalism in classical social theory because “nationalism was not seen as phenomenon that could be connected to the rise of modern nation states, or as a feature linked to the expansion of industrialism.”[16] Nationalism did not have the salience as a scientific area, but was merely a political issue that Weber was passionate about. Nationalism is in background of his academic work but is the forefront of his political writing.
B) Amorphous Study Area: The second plausible explanation for stopping short of a typology of nationalism stems from his implicit recognition of the subjective and amorphous nature of this area of study. Near the end of his paper Ethnic Groups, Weber states that to understand ethnicity “[we] would have to analyze all the individual kinds of sentiments of group membership and solidarity in their genetic conditions and in their consequences for the social action of the participants. This cannot be attempted here.”[17] Cultural interpretive forms of analysis would be required. Herein Weber recognized that nationalism is a particularistic field, that the explanatory theory could be not be created without hyper-extensive research of all cases which is nearly impossible. Therefore, as John Breuilly states, “I do not think it is possible to have a satisfactory theory or even approach towards nationalism as a whole.”[18] The lack of a theory of nationalism from Weber is fortunate as nationalism studies have failed to consolidate into a cohesive core explanatory theory anyway.
SOLID CONCLUSION:
Weber has many advocates in a wide range of fields making him one of the greatest social theorists in Western academia. It is for this reason that a historical assessment of Weber and nationalism has occurred.
Specifically for nationalism studies, Weber was the precursor to the ‘subjectivist’ school of nationalism.[19] Weber was in no way interested in ethno-symbolism, primordialism, standing along side the modernist approach to nationalism.
Weber’s academic descendents include in particular Gellner & Breuilly for certain; as evidenced by the social constructivist anthropological approach.
His methodology of analyzing power is still widely referred but he has also proven that even a genius scholar is susceptible to intellectual indulgences: OR core values. The fact that his historically repugnant nationalism did not tarnish him much is indicative of his overbearing significance and his prestige as an individual, the same prestige he desired for Germany.
[1] Abizadeh, A (2005). “Was Fichte an Ethnic Nationalist? On Cultural Nationalism and Its Double”. History of political thought (0143-781X), 26 (2), p. 334.
[6] Whimster, 2003, Sam. eds. The Essential Weber: A Reader. London: Routledge, 2004, 124.
[7] Weber demonstrates his longevity in arguing against the morally outmoded conception of race believing that “with race theories you can prove or disprove anything you want.” See Roth and Wittich, 387.
[8] Weber was honest about the capacity for objective research in social science in science/value distinction see Ringer.
[9] H.H.Gerth & C.Wright Mills (eds), From Max Weber: Essays in Sociology (New York, 1946). `Structures of Power’, 172.
[10] Again, it may be that Weber’s wife inappropriately inserted those texts into Economy & Society.
[11] Hence Weber’s surprise at the enthusiasm of the German people in August 1914 and consistent distrust of the proletariat in his political writings.
[12] Beetham, D. (1974). Max Weber and the Theory of Modern Politics. London. Chapter 5 `Nationalism and the nation-state’. 144.
[15] Weber, Max. `Between two laws’, in Lassmann & Speirs, Political Writings, 76.
[16] M. Guibernau, Nationalisms: The Nation-State and Nationalism in the Twentieth Century (Cambridge, 1996), chapter 1 `Nationalism in classical sociological theory’, 41.
[18] Breuilly, John. (2001) “The State and Nationalism” from Guibernau, Montserrat and Huntchinson, John, Understanding Nationalism, pg 44, Polity Press.
[19] Anthony D. Smith, Nationalism and Modernism (Routledge, London, 1988), 170.
Defining, Background, Foundations (Detailed Background May Not Be Necessary in Exam)
2 important aspects of Max Weber’s Approach to War Writting:
(1) Weber’s Ultimate End > German nationalism: Weber’s ultimate value: preservation of German world power:
a) need to maintain the German state and culture (created in his youth: 1871)
b) build on the struggle itself as bring meaning to this creation of the German Reich.
c) Weber’s ultimate end is rational as a value-judgement: nationalism. The means ARE rational.
(Ringer, 2004)Weber’s science value distinction: we do not choose our ends, they choose us. It doesn’t matter what the ends are: good scientific knowledge will allow objective science.
(2) Weber’s Politics as a Vocation: (1919): all policy decisions are formulated through rational means to justify the ultimate end of the German Reich. As long as his means to achieve the irrational end are themselves rationally deduced then he fulfills the ER.
Weber aspires to the Ethic of Responsibility: a one-sided pursuit that models human beings as rational & pragmatic. (Whimster, 2003).
Before he articulated Ethic of Responsibility in 1919, he implemented ER to justify:
a) his stance on Unrestricted Submarine Warfare (USW).
b) his stance on negotiating a peace with honour at any cost.
Weber view prestige as more important than gains (which is difficult for others to agree with because they would see the deaths on the front lines as being in vain. Weber is more rational than Tirpitz and the High Command because he disassociates emotional pain with achieving long-term outcomes that are beneficial to (1).
There are two fundamentally different, irreconcilably opposed maxims:
Ethic of Conviction: acting on what is believed to be right because you believe it alone. If evil consequence flow from an action, then that is beyond ones control. Tirpitz & the High Command could be seen as exhibiting these tendencies.
Ethic of Conviction (EC): ‘The Christian does what is right and places the outcome in God’s hands. (Weber, 1919, 359). If evil consequences flow from an action done out of pure conviction, this type of person holds the world, not the doer, responsible or the stupidity of others, the will of God (Christian) who made them thus. (Weber, 1919, 360). You don’t weigh the consequence of your convictions. Value A is what I will strive for no matter what the consequences. The EC is a romanticism of the intellectually interests without a sense of responsibility. It was a product of the negative parliamentary system of Germany (section 39, Bismarck’s legacy…). You need EC to want to enter into politics….
Ethic of Responsibility: rationally deduce ones position by weighing the probable consequences given available information. Assumes that people aren’t necessarily good or rational.
Ethic of Responsibility (ER): ‘One must answer for the foreseeable consequences of one’s actions’. (360) ER is a view point of trying to weigh out the consequence of your action. You make allowances for precisely these everyday shortcomings of people: he does not presuppose goodness and perfection in human beings. If the probable consequence will be reduce the war: Is it necessary for political leadership. “There is a responsibility for the cause (EC) it becomes the lode stone of all action.” ALMOST ALL POLITICIANS FAIL: “the eventual outcome of political action frequently, indeed regularly, stand in a quite inadequate, even paradoxical relation to its original, intended meaning and purpose (Weber, 1919 Politics, 355pp).
THESIS: Social science academics tend to establish their outcome and then deductively pursue a rationalization for that outcome to explain their values. Weber is rationally consistent in so far as his actions can be explained by the Ethic of Responsibility.
Should not misconstrue Private Opinion with Public Opinion divergence as a sign of a fragmented, shifting pragmatic politician but as part of German Public Morale issue.
Nationalism & Max Weber: War as Proving Ground Either We Take Our Place in History OR become subordinate against the Anglo & Russia world powers.
He believed in the responsibility of the Reich before the bar of history. The war was a proving ground. Quiet emotional, irrational but the state needs to be defended to cultivate the nation. (In Between Two Laws, Weber, 1916) he states that the creation of the Reich is in direct resistance to the division of the world between what he calls “Anglo-Saxon convention” and “Russian bureaucracy.” To not struggle honourably for the Reich existence is to make the Reich meaningless. In a sense the meaning and the normative value of the Nation is its creation of a space for struggle and ‘survival’ + protection of the divided smaller states of Europe.
(Hennis, 1988) Nietszche-ian struggle brings meaning for life: Germany facilitates meaning.
Weber is deterministic. Germany is a great power, it cannot be like the Swiss. The weak, artistic culturally diverse society has a place but not as significant as Germany.
Switzerland Reich
The Sermon of the Mount: Saintly Diabolical Politics
Weak, subordinate, small Powerful, grand, nominal
Renounce political power Accept burden of power
Other cultural possibilities Survivalists
Max Weber as a pragmatist for German nationalism.
Max Weber the pragmatist, reactionary, instrumentalist, politician, fragmented
(Breuilly doesn’t support this view)
In some areas, his opinions would change depending on the military situation in others (such as annexations) Weber’s ideas remained fairly consistent regardless of the political and military realities.
This argument is about how Weber’s nationalism may (or may not) have influenced his thoughts and whether this disabled him from making judgements based on his own notion that is the ‘ethic of responsibility’. Did Weber’s nationalism ever get in the way of him pursuing rational goals with regard to Germany’s position in the war?
War as Distraction: 1914 August: Joachim (Radkau, 2005) argues, the war offered Weber a refuge from his problems – a possible explanation for his original endorsement of the war.[1]
Weber as an Incoherent Pragmatist:
Weber managed to create framework without being a pragmatist but we are infallible. Our conclusions are influenced by the world: realities changed on the daily basis.
You can justify anything as long as you are not irrational: as long as you are rational. Rationality is ridding a tiger.
Weber can’t compromise those ends. Where as politicians have to compromise.
Weber wasn’t a populist but couldn’t accommodate irrational demands of the population.
Economic objectives with the Polish East Elbia. Ethic of Responsibility.
He was against Versaille (was that convinction? or ethic of responsibility?) He then came round a month later realizing it has to happen.
OR has his scientific argument stops his scientific ends has led him to the political conclusions.
BUT with Versaille 1919 his convictions force him to abandon his ER.
Ethic of Responsibility or Ethic of Conviction:
Ride tiger: rationality is what ever you think.
Weber got it right he could have rationally argued that he had been right.
Tautology of ER: Ethic of responsibility can only be measured retrospectively. You can only be aware of the consequences afterwards. Weber looks good for supporting the right things.
ER as Framework to Justify Anything
Wonderful framework ER. Why serious scientists needs to have a methodology: rationally. Stick to the facts.
1919 elucidates:
BUT a politician needs to react to so many facts.
Note that this rationality could be used to justify anything (counter-argument) BUT MY response is that Weber had values/principles at the core of his approach: he hated those who attacked Jews etc.
Counter-Argument to EFJA: Weber still has his values, therefore he would not have supported Hitler, as he did not support the Fatherland Party. The Genius of ER: he can argue anything. BUT Breuilly says he doesn’t. Rational ends that can justify his means, end Liberal bourgeois. So why does Weber ridicule other academics because they have different ends. Weber respects the Christians and Socialists. He respectfully hates the Socialist and Christians.
(Mommsen, 1984)
Breuilly doesn’t agree with Mommsen: that Weber’s approach would have supported Nazism through the ER. Determinism of Mommsen, 1984: he is very critical. Mommsen doesn’t like ER, doesn’t like President (charismatic) of Weber. Weber wants a stronger parliament: selection process for leader occurs. BUT in the Weimar Constitutional opinion (Hugo Price) making Weber wants to enhance the bundestag, Reichstag weakened, reduce Prussian influence, all powerful vice president.
Spectrum of Weber’s private (scholar) morale: Weber’s position with regard to the war changed greatly during its course; 1914, optimism > 1915, moody > 1916, pessimism.
Note that his GPM is always constant…
(A) 1914 > Weber’s position on the Outbreak Weber’s an optimist – in the sense that it would give the German Reich a raison d’être – and enthusiast.
Wolfgang (Mommsen, 1984) he “frequently criticized the German people for quietism and apolitical attitudes”, believing that “the nation’s patriotic enthusiasm, its willingness to make sacrifices, its national unity” would give the war an inner meaning, whatever the outcome.[2]
(Radkau, 2005) escape the polemic.
Enthusiasm is strange for two reasons:
(1) Weber did not mention the prospect of war in any of his personal letters during the July Crisis of 1914. In fact, Weber seemed to have completely shut out the world of politics as the letters focused solely on “personal problems”.[3]
(2) Second, Weber’s enthusiasm seems somewhat misplaced as he viewed Germany’s prospects for success pessimistically.[4]
Weber never published an academic support for the war: mention Michael Ignatieff’s support for the War in Iraq in 2003, then he become the leader of the Liberal Party of Canada.
Yet when war broke out with Germany very much at the centre of it Weber wished to be involved in the effort – preferably as a soldier at the front. Age, however, restricted him from active service and so he became the administrator of a military hospital in Heidelberg. In a letter to his mother in 1916, he laments not going to the front: a death trap for many young men…emotionalism. During this early period of the war, Weber scarcely commented on politics in public.
(B) 1915 onwards this mood began to shift >> Weber’s position on Annexation: he consistent & heavily influence by his nationalism.
Matthias Erzberger’s annexationism: Six Economic Associations memorandum of May 20th, 1914 signed by several Berlin professors and 1347 representatives of the cultural world. “Annexation of Flanders and Verdun + repressive measures for non-German speakers + Massive resettlement plans for non-Germans.”
Weber made his opposition to annexations public in December 1915 when he argued against them in a series of articles entitled ‘Bismarck’s Foreign Policy and the Present’ (1915) which were published in the Frankfurter Zeitung.
(GPM2): Weber’s concern about PUBLIC MORALE is important:
Bismarck’s Foreign Policy and the Present” he opposed a boundless annexation program. Lack of realims in an annexation policy of the west. The Article outlines the long-term effects of annexation propaganda on public opinion: as soon as it was apparent that such unrealistic goals could never be achieved, disillusionment would become widespread and the fighting spirit would dissipate.
Belgium was for Weber a pawn in negotiations against the Triple Entente.
(Mommsen, 1984) Weber explained that he did not believe that annexations in the west were desirable because it would not be not in Germany’s national interest to expand there.
Germany, he argued, should not expand beyond the borders of the natural German nation and Belgium, for example, was clearly not part of the German nation.
Integrating foreign nations into the German empire would serve only to weaken and destabilize the German nation as well as antagonize the other great nations of the west once the war was over.
Negotiations with Britain & France: Belgium conquest would weaken any negotiations made with Triple Entente (Breuilly?)
POLISH QUESTION: With regards to the possibility of annexations in the east, Weber took a more flexible approach. Weber had, early on in his academic career, defined the lack of a Polish nation-state as a problem. It was not just a problem that concerned him academically, but it also concerned him politically. Throughout the war, Weber advocated the creation of a Polish state.
Two Motivations:
1) (Mommsen, 1984) Weber’s goal was “to win the Poles as political, military and economic allies of Germany by seeking their friendship”[5].
2) Polish as fragmenting Russian hegemony/buffer zone: outweighed the former in Weber’s thinking. The newly created states were to be tied to Germany politically, economically (a tariff-union), militarily (the creation of military infrastructure) and would mainly have served as German buffer-states against Russia.[6]
In short then, Weber was opposed to annexations precisely because he was a pragmatic nationalist. Where nations existed, Germany could and should not take over as it would cause only problems. Yet, Germany, being a large and powerful nation should tie other nations to it without getting directly involved.
C) 1916 Weber’s Public Mask, Private (Scholar) Sorrows: Weber felt pessimistic and deeply troubled with the direction which the war, and the politics surrounding it, had taken.
Although attempts at ending the war in negotiation were made numerous times, they were all doomed from the onset because none of the belligerent powers were willing to abandon their interests or their allies. The one exception to this was post-revolutionary Russia.[7]
By this point it would seem that Weber had given up hope on Germany decisively winning the war and that fighting it until the bitter end would ruin Germany economically and cause the ‘home front’ to collapse.[8] Thus, logically, the only way out would be by negotiation. Weber seemed to realise this and yet he was not quite willing to admit to it. The nationalist in Weber would simply not let him acknowledge the bitter truth. Thus when the Peace Initiative was passed, Weber went to great lengths to criticise it because he feared it would be seen as a sign of weakness abroad and because it would increase the level of domestic tension which was becoming an increasing threat to Germany’s war effort. In all, he considered the passing of the motion as an event which could cost Germany its prestige abroad – it was thus a shameful act. The Peace Initiative did not have great political or military repercussions as the Reichstag could not enforce it.
Brest-Litovsk March 1918: (Radkau, 2005) observes in Weber a similar internal contradiction. In private (scholar) letters to his wife and close friends, Weber expresses criticism of the way in which the negotiations were being conducted and raises doubts that the peace will be a lasting one if Ludendorff and Hindenburg imposed a grossly unbalanced treaty.[9] Here Weber seems to be making a rational analysis of the situation. Yet publically, he recorded his support for the botched treaty.[10]
On the one hand, he wished to put on a brave face in order to keep up the appearance of a united Germany abroad. On the other hand, Weber supported the Supreme Command as he feared domestic division over the issue could hamper the general war effort.
Here Weber was still adhering to the ‘ethic of responsibility’. But his public support for the prolongation of the war in spite of the increasing certainty that it would not end well, render his private (scholar) reservations void. Here Weber’s nationalism blinded him from stating what even he knew were hard facts. Thus when Germany was beginning to collapse under the burden of war, Weber seems to have ditched rational and responsible rhetoric for passionate, desperate and often self-contradictory appeals to the German population’s nationalism. The argument is extended to cover his view that Germany should not sign the peace treaty and should resist giving up territory to Poland. (He was playing the politician)
During the Spring Offensive of 1918: Weber changes his war ams: he believe that they can win the war: this is silly optimism.
Weber could handle being a politician all the baby-kissing.
WEBER’S INCONSISTENCY only DURING WAR: Fortunately this period of Weber’s writing was fairly short-lived and once the extent of Germany’s defeat became all to obvious for him to cling onto hope, Weber found back to rational argument and presented some powerful pamphlets on the how Germany’s political future should be arranged.
(Beetham, 1974)
Weber held no simplistic belief that the prestige of a nation’s culture was dependent upon the mere extension of its power. Whatever prestige Germany might derive from the proposed cultural policy in the East, would not be a result of her power as such, but rather of the way it was used and the purposes to which it was put.” (142, Beetham). Machtstaat = totalitarian state
Those who regard Weber’s wartime nationalism simply as an extension of the nationalism of this early period thus overlook two developments in his thinking” (143, Beetham)
1) his critique of Germany’s prewar foreign policy, the politics of national vanity; which contributed to the outbreak of the war.
2) Confrontation witht the situation of national minorities in his Russian studies of 1905-6, and with the problem of how to preserve the cultural identity of smaller nations in face of the aggrandisement of a larger power. : this is apparent in his critique of Prussian attitude to the Poles as early as 1908” (143, Beetham).
Weber is still an emotionally committed German nationalist: he had his share of national prejudice, particularly in respect of the Russians.
Beethem’s thesis that Weber’s profession of a world political role for Germany involved the pursuit of power and aggrandisement for its own sake, and that this national commitment can simply be reduced to the ‘Gefuhlspolitik’. (politics of emotion).
INSTEAD “the ideas which are used to justify and give meaning to a particular way of life themselves set limits to the range of conduct possible within it” (143, Beetham).
There is nothing distinctively bourgeois about the pursuit of powerit is a different matter, however, with the ideas Weber uses to justify its exercise.
Dificult to avoid concluding that “Weber remained bound by the typical categories of thought of the bourgeois age, to which belonged not only the concept of the ‘Kulturnation’, but also the idolatry with which the bourgeoisie pursued the national culture as the final value.
Political Activism versus Academia
Weber cannot extricate himself from his political reality but his attempt is partially successful: politicians have short-term objective while Weber has long-term ones: throughout the war he is pontificating about the German Reich’s future in the long-term given the progress of the war. He took a job at the University of Vienna but could not stand to stay out of the dialogue on Germany’s future for long in 1918.
During the War: Weber energetically championed the concession of cultural autonomy to the Prussian poles and an honourable understanding with them. He pointed out that ‘a state need not necessarily be a ‘nation-state’ in the sense that it{oriented] its interests exclusively in favour of a single, dominant nationality. The state could “serve the cultural interests of several minorities in a way that was in full harmony with the interests of the dominant nationality”. Weber could not see the state replacing nationality. OR WAS IT SOMETHING ELSE: Russian Imperialism’s threatening creation of nationalist autonomy under Russian Rule????
Weber’s observations and his consciousness of responsibility led him to change form a firebrand to a compromiser on the question of Prussian Poles: HIS transformation was primarily due to the “recognition that a moderate nationality policy was needed to counter the attraction of a potential Russian policy of autonomy”. Russian promise of autonomy + German-Polish Question = concessions to Prussian Poles. Weber feared the peaceful acquisition of Poland by Russia as a crass Russian Imperialism. Weber wanted Germany to control Poland. Weber believed that only a sincerely liberal nationality policy could bring about a solution to the German-Polish problem.
8.2. The Treaty of Versailles and Germany’s Future in the World
“Max Weber looked upon the German negotiations in Versailles as unworthy of a great nation. he believed that the German side had had to indulge in self-humiliation, in the hope of winning better conditions from the enemy, and he rebelled against that.” (311)
Weber used all his influence to persuade the allies that too harsh a treatment of Germany would result in a reawakening of German nationalism → he wasn’t too worried about the latter; he just didn’t want Germany to be humiliated. To this end, Weber and others formed the Heidelberger Vereinigung für eine Politik des Rechts which was largely unsuccessful.
→ Weber supported the publication of Germany’s war papers despite some unease he felt about this: “Weber’s additional call for an investigatory commission to question the leading figures in the German government before and during the war was founded on his rigorous ethic of responsibility”. (316)
“Basically, Weber viewed the German negotiating position as hopeless from the outset and expected nothing from the negotiations and opposing arguments in Versailles.”
→ He firmly believed that the war guilt question did not apply to Germany as it was Tsarist Russia which bore the guilt of the war as they forced Germany and Austria into a situation in which their only available course of action which was honourable would be to take up arms (319).
→ He vehemently argued against signing the peace treaty “whatever the risks” yet “Weber had to face a difficult inner conflict between rejection at any price on national grounds and the sober evaluation of the consequences of such a step.” (320) By June he could no longer defend rejection even though he personally favoured it.
Weber’s nationalism gains strength as a result of Germany’s treatment by the allies. (321-2) Germany must once again build itself up to become a world power, regardless of what the treaty said. Weber also argued for the leaders of Germany (including the Kaiser) to hand themselves over to the American’s in order to argue their case and defend Germany’s honour. Ludendorff rejected this suggestion out of hand.
Notes on Weber’s politics:
“Domestically, he pressed for a democratic and social constitutional order; but democratization was only a means for him to produce qualified political leaders who would bring the legacy of the “Caesarist” statesman, Bismarck, to a new glory. He had no concrete plans for the form that the social reorganization of Germany would take, although he had spent so much time playing with socialist notions without, however, believing in them.”
Foreign policy and Germany’s place in the world were more important to him throughout the period.
In the end, Weber realised that his policies were out of touch. Whereas before the war he was seen as political outcast because he wanted to change the system and adopt a realistic foreign policy, he was seen as outdated after the war. (330-1)
COUNTER ARGUMENTS to Weber the Incoherent/Pragmatist: Weber the principled academic: (3) Max Weber as Principled
However, doesn’t the objection to annexation based on the argument that it undermined the very essence of a nation-state, go beyond pragmatism?
The causality is mixed up in the above argument that Weber is a pragmatist. Weber believes in the principle that nations should be self-determined, just as he respects his ultimate end of Germany on the world stage. He believes in the Bauer/Renner principles for the Polish and Slav nation-states because it coincides with his belief of a German nation-state. In other words, he believe in to each their own. As it happen a Polish kingdom does have strategic advantages against Russia aggression. As it happens, also, Belgian sovereignty has strategic advantages for British and French negotiations.
Not opposing annexationism in public while condemning it in private made sense precisely in terms of his Ethic of Responsibility.
Weber see the Great War as a product of international dynamics and not necessarily German mistakes….
On the Peace Negotiatoins: could one
Weber’s Principled view of The Nation-State System: Weber believed that “a correct relationship between state and nation, where the state = power and the nation = culture and language….It was therefore unwise to annex great peoples with strong national cultures.” (Mommsen, 1984)
Dragomanov
Weber discovered the works of Ukrainian federalist Dragomanov, who he believed brilliantly solved the problem of nationalities: checkout M.P. Dragomanov. The Collected Works of M.P. Drahomanov, 2 vols, Paris, 1905. If Dragomanov’s proposal were adopted we could bring the interests of the individual Russian nationalities under the same roof as an all-Russian great power policy. Dragomanov demanded sweeping federalist transformation of Russia into separate ‘regions’ with full cultural autonomy on the basis of ethnic borders. He attributed the Cadet program for the political autonomy of nationalities to Dragomanov’s ideas – whether consciously or unconsciously. Weber claimed Dragomanov’s writings as fundamental for any treatment of nationality problems. CHECK OUT A short synopsis of the writings of Dragomanov in “Mykhaylo Drahomanov: A Symposium and Selected Writings,2 ed. I.L. Rudnytsky, Annals of the Ukrainian Academy of Arts and Sciences in the USE 2 no.1 (New York, 1952). “unify…bourgeois liberalism’ across the barriers of the conflict of nationalities. Failed to recognize the extent to which the Russian liberal movement’s tolerant attitude to the national minorities was merely tactical because the aid of these minorities was essential to the success of the constitution. It is questionable where the Polish drive for independence could have been contained in the long run by the concession of broader autonomy.
Ethic of Responsibility or Conviction?: Max Weber’s principled approach Defended> Annexation, Government & Peace negotiations
Even Mommsen seeks to clarify “the inconsistencies and contradictions in his position, while at the same time recognizing its fundamental consistency”, citing Weber’s capacity for “judgement” that never wavered from the ethic of responsibility – separating him from the “shallow emotional nationalism” that engulfed the intelligentsia’s lack of rational justification for the consequence of their actions. (63, 447, Mommsen, 1984)
It is thus fascinating though not altogether surprising that Weber delivered his “Science as a Vocation” lecture two days after sitting with a panel of Social Democrats in Austria to speak out against Pan-Germanism and the founding of the Fatherland Party. (264) Thus his seemingly inconsistent actions actually conform to his overall theoretical framework, as outlined in “Science as a Vocation”, of distinguishing the “science” of nationalism from its “value”.
I don’t follow this concluding point. I am suspicious of arguments that reconcile “inconsistencies” by pointing to some deeper level without actually spelling out how that works. ie I agree but elaborate please. – Breuilly.
Social scientist, Level-headed, Principled Thesis:
Introduction: (1) Weber’s arguments centre around his ultimate end: Germany’s place as a world power (Between Two Laws): the need to maintain the German state to instrumentally facilitate German culture built on the struggle itself as bringing meaning to the 1871 Reich, (struggle -> protestant work ethic.)
(2) All policy decisions (which Weber has no influence in) are formulated in Weber’s case through rational means to justify that end. He uses the Ethic of Responsibility later outlined in his Politics as a Vocation 1919 lecture, which justifies his stances during the war (Aims, Annexation, USW, Peace Negotiations). Weber also argued for negotiating peace with honour at any cost. he is more interested in honour/prestige than gains which is difficult for others accept because the deaths on the front would seem vain.
(3) Limit Cases Analyzed (for time-sake A rational actor must have rational means to achieve an end that he believes is rational (but doesn’t have to be). consistency/rationality through the means of his arguments IS CLEAR. You can defend him because his means are rational BUT Weber has intellectual consistency in his irrational end.
Weber had a realist appraisal of German foreign policy in the war years, not by a principled appreciate of other nations’ right to exist? (Mommsen, 1984)
WHY IS NEGOTIATION WITH HONOUR SO IMPORTANT because HE BELIEVES without peace negotiations GERMANY WILL BE SUBJUGATED into a small group of nations and take the path of Switzerland (Between Two Laws). He want avoid the destruction of his ultimate value of a German nationalism. ER applied.
Concern for German Public Morale are demonstrative of Weber’s congruence with his ultimate end: principled.
Max Weber knew he would be attacked when he spoke out against the High Command: Weber is important academic voice in Germany: is Weber merely using reason to ride a Crazy Tiger. Weber is concerned about morale: Rational Choice Theory.
Weber’s Position is Responding to Two Groups:
The High Command (Fischer, 1961): strategic imbeciles or failed genius: the Schlieffen Plan-> defeat the French quickly then deal with Russians. The High Command could be characterized by maximalist ambitions.
Hindenburg: Fatherland Party -> Pan German Imperialist Racists/anti-semetic: Maximalist cases: WEBER HATED these cretins. German Fatherland Party (German: Deutsche Vaterlandspartei) was a pro-war party in the German Empire.The party was founded close to the end of 1917 and represented political circles supporting the war. Among founding members were Wolfgang Kapp (of the Kapp Putsch fame) and Alfred von Tirpitz (naval minister and post-war party leader). Peak of its political influence was summer 1918 when it had around 1,250,000 members. Main source of the funding was the Third Supreme Command. The party was dissolved after German Revolution (December 10, 1918).One member, Anton Drexler, went on to form a similar organization, the German Workers Party, which later became the National Socialist German Workers Party (Nazi Party) which came to power in 1933 under Adolf Hitler.
(Radkau, 2005) Weber thinks that the public needs to be confronted with the facts. SO German that weakness should be kept secret for national unity. Machivellian. Breuilly doesn’t agree with psychological: Radkau humanized Weber. Which Weber don’t like.
(GPM1) A Context of Crisis: Cohesion as a means of being a good nationalist: whenever the nation is challenged by exogenous forces there is a need for political cohesion: the nation must consolidate its opinion towards the objectives that the political elite have ascribed. In August of 1914, the German Reich enters survival mode, old differences within the nation are diffused and public criticism that might weaken subsequent peace negotiations are to be sidelined until the crisis is resolved. Public morale needs to be high for the war to end with honour.
Weber Support of the Administration: Weber does follow this line of thinking throughout the war: in the hope that it will produce a positive outcome for his ultimate end.
Burgfrieden: fortress peace or castle peace: party truce: Social Democratic Party and other agreed during the War. Unifying for victory, complete consolidation of public opinion until the completion of the war. For this reason, I think, Weber doesn’t want Tirpitz fired over the USW question because he fears weakening morale. Later in 1918, Weber attacks Erzberger for publicly damaging morale with the peace resolution speech in the Brest-Litovsk case: weakening morale was a terrible act for Weber.
Weber wanted to join combat forces: lamenting that that war should have started earlier actually in 1889 before Bismarck was fired, in a private (scholar) letter to his mother. How rational is it to wish to be part of such slaughter? Because it defends the ultimate end. In a personal letter to his mother in 1916: this is why would he have a feverish lament? Weber bought into that kind of thinking. The war was meaningful to Weber. Not rational but his lament is proof that there is a place for emotion in Weber’s life.
Weber took a bureaucratic post Reserve Infirmary of the Heidelberg Garrison District. Was entrusted with administrative duties and disciplinary control of the wounded, morning to night for over a year. Sought political work in 1915. Weber is a strong nationalist.
He was sober when the war broke out in the summer of 1914 seeing it as a failure of German diplomacy, fearing economic ruin. At the same time, he was amazed at the national mobilization of support because the Germany people had been an apolitical with a weak civil society thus far. In a letter to his mother, Weber says the ‘meaning’ of the war was an honourable test; the war was a proving ground for the struggle and survival of the Reich, hoping for an honourable peace on equal terms. Weber has a realist appraisal of German war aims. The war must end positively although Weber is not pleased that it is occurring.
Anti-Annexationism & Weber
Six Economic Associations memorandum (1914)
Erzberger Newspaper editors
Pan-German League (extremist) Anti-Pan-Germans
Annexationist Anti-Annexationist
Conservatives Liberal
Supreme Commanders Hollweg (moderate) Max Weber
Seeberg Address
Weber was siding with the SPD on annexation. SPD didn’t change their position: they were sheep lying next to the Lions: Between Two Laws…
New waves of annexationism emerged with victories in the East even among leftists.
XXX Annexation as a War Aim was a means for consolidating support. From the Schleifen Plan’s objectives to an emotional appeal, Annexation aims was an instrumental means of justifying the war. Weber believed it was silly to commodify a soldiers life to such an objective: annexation should not be the prize of victory because it contravenes his ultimate end.
Germany was strategically outnumbers diplomatic isolation BUT they fought harder and better than the Triple Entente: their number of casualities was much lower. Can we attribute this to that enthusiasm motivated by War Aims>
(GPM2) Weber was afraid that if those war aims were unfulfilled: it destroy morale. He did not want those soldier’s lives to be commodified and defined by speicifc outcomes. Did they die in vain? Weber’s position would be upsetting because those death’s would have been to mostly meaningless casualities. What was the point of war if not for annexation?
Weber’s underlying theory ‘Bismarck’s Foreign Policy and the Present’ (1915) is that the German nation should remain as Bismarck had made it except for the Alsatians.
Weber supports Polish nationalism: the Polish need an olive branch.
Austro-Marxists: Bauer: give communal institutions: harmonious nationalists <->
Economic questions: Weber’s formation of an Autonomous Poland in November 1916.
Polish must be given as much autonomy of prestige, culture, control of language.
Weber appears to want to go far down the autonomy road: if we treat the Prussian poles poorly it will look terrible in Poland.
Values Judgements Backed By Science:
As long as Weber is able to shift Polish: confronted Bauer: Weber don’t believe in objective truths: this is the best I can offer but with new evidence he will shift on Polish. Build up a scientific then use it to defend his means.
He knows that he is full of values he accepts and thinks its okay aslong as you are rational. Spent his whole career being value-laden then he says that science should strive to be objective BUT then if we do all this we should not be doing it in the lecture (Science, 1919). Science Vocation: instrinctive values and then you have choosen values. EH doesn’t like Christian pacifist but he respects them for rational. He respects induvudal sermon on the mount.
November 1916 Text only in German:
Argument against annexation.
State should only matter as an INSTRUMENT of the end to allow German culture
Protection of German interests is most nationalist.
Austria lacks national community
Prisoners of Russia: -> the state can do a lot but cannot control the individual.
Enthusiasm to war because Germany is his nation-state.
Weber says for the moment a positive light on the Poles (might seem pragmatic BUT it’s all about the Ethic of Responsibility for Weber:
Weber believe in the Nation Not So much the State.
THEREFORE his ultimate end of German nationalism is served.
Weber’s Annexation Positions Are Consistent:
Nationalism on the Western-Front: Holland are Germans in a hurry. They may have a political consciousness but he is primarily interested in peace with France & Britain.
Nationalism on the Eastern-Front: Russia can’t be allowed to advance westward. Weber has a principled argument for the protection of the German nation-state.
BUT SOME DEBATE HERE:
Weber never condemns the Brest-Litovsk (March 3rd, 1918) which extended German territorial occupation into large portions of where a Polish nation-state would exist. This caused a weakened relationship with the Polish people since it was a mockery of Polish autonomy.
Weber wanted a strong relationship between Polish and Germans in order to divide and rule against the Russian hegemony.
BUT Weber didn’t agree with the annexation: Second Suboridnate nationalisties: recapitulation of the nations with or without power…Between Two Laws.
Rosa Luxembourg: supports a Polish national program…she rejects nationalism: cosmopolitan social Marxist.
(Weber, 1895) German overseas empires are relatively small but he sees them as essential for Germany’s place on the world stage. German national resources are impressive: he has the second largest industry only US is better: Iron Ore. Raw industrial terms.
Weber’s indirect rule approach -> contain people manage them don’t involve.
Polish migrant: East Elbia 1919, Polish migrant workers new diminished ward of Germany: independent: resist Polish: how do we preserve the German nation-state.
1916: Weber economic and financial links customs union, movement of goods.
Ethic of Responsibility or Conviction?: Max Weber’s principled approach defended> Unrestricted Submarine Warfare
How did his views on German policy relate to his general theory of politics? Are his writings on military and foreign policy modeled by his “Ethic of Responsibility”?
Weber as an Intellectual Shifter: changing based on new information.
Breuilly thinks its an intellectual shift. Bauer, Dragamonov. BUT I can’t except that there is a pragmatic interest. Instrumentalist approach. 1905: Russian Liberalism: they were willing to give in autonomy to minorities and Weber. Dragamonov is something Weber did Read: (Pg 58) (Mommsen, 1984). Mommsen: Bauer (possibly)-> possibility that Weber engaged in Bauer:
Breuilly END is shaped by means that are rationally deduced within a limited framework (ie. principle) which explains why he didn’t support Social Democrats. Weber seems to not go into areas he won’t go: seems to offer the most rational course of action. Rationality is connected to structural constraints. Scientists can not ignore mathematics.
Social science is to get as close to the rational arguments and rational ends as possible
Weber’s General Theory of Politics: The Ethic of Responsibility versus the Ethic of Conviction>ER: the point is it is a rational instrument. Not that it is Un-German to commit unrestricted submarine warfare. Pragmaticism applies to USW. ER odds are against the use:
Weber wanted to negotiate from a position of strength: ie. Supports the Spring Offensive 1918.
Wilson might have inevitably entered the war: but it was more about timing.
Breuilly believes that Wilson was:
a) slowed by the German-American coalitions and
b) isolationist ideology was a powerful one in the US.
Does he use his Ethic of Responsibility when he states that the Treaty of Versaille 1919 is a horrible defeat of national honour? He later changes his views a month later to accept it.
ALSO:
Carl Schmitt/Max Weber relationship:
Weber believes that politics is not a moral sphere. Politics is simply about power. The politics of Max Weber: where as the social science are value-based.
The idea of Friend or Foe: the world of politics is dichotomized between friends and enemies. This is the adversarilist approach. This is the non-territorialized goal of Political Theory: socialist enemy nexus.
He does not mean to provide us with an “exhaustive description” laden with “substantive” normative content. (Schmitt: 2007, 26) Rather, this friend/enemy distinction is the criterion by which we can determine as to whether or not an action is properly political. It is a point of heuristic entry. The tendencies of identity-bearing agents to make these distinctions are themselves attestation to the existence of the political. (Schmitt: 2007, 29) What really matters is that we tend to define ourselves as being a part of one group or another. NO MORALITY IN POLITICS
(2) Weber’s Ethic of Responsibility (1919): all policy decisions are formulated through rational means to justify the ultimate end of the German Reich. As long as his means to achieve the irrational end are themselves rationally deduced then Weber is fulfilling the ER. Before he articulated Ethic of Responsibility in 1919, he implemented ER to justify:
a) his stance on Unrestricted Submarine Warfare (USW).
b) his stance on negotiating a peace with honour at any cost.
Weber view prestige as more important than gains (which is difficult for others to agree with because they would see the deaths on the front lines as being in vain. Weber is more rational than Tirpitz and the High Command because he disassociates emotional pain with achieving long-term outcomes that are beneficial to is ultimate end Germany’s place on the world stage.
Counterfactual test: If the High Command had listened to Weber, would Germany have ended the horrors of WWI with dignity and honour?
Unrestricted Submarine Warfare: (USW)
The Ethic of Conviction versus the Ethic of Responsibility.
Weber implements a ration choice model based on his subsequent Ethic of Responsibility to justify his position against USW.
Background:
Naval Admiral Tirpitz’s prosecution of the naval arms race with the Fleet Acts led to Germany’s political isolation. Tirpitz believed in what is effectively risk theory (really game theory) analysis where Germany should become a second naval power, the English would avoid direct conflict in the hope of maintaining naval protection of their colonies thus allow German naval empire to emerge. Unfortunately, history shows that the Britain felt threatened anyway given their geographic position. Leading to an arms race: Tirpitz’s policy further isolated Germany politically: Most importantly: The British blockade ended any hope of German naval power blocking American trade. Germany was already ISOLATED.
Basserman the National Liberal Party leader accused Weber of “tragic demagoguery”.
Conducting submarine warfare meant that prize rules of capturing contraband were abandoned. The Lusitania was sunk in May 7th, 1915 with 128 American passengers and another 1000 passengers died.
In February of 1916, Tirpitz escalated the U-Boat warfare. The High Command assumed that in using Unrestricted Submarine Warfare they could force English capitulation. German Admirality thought they could crush England in 6 months. In hindsight, British tonnage was too large: there were non-British ships to consider. The High Command was gambling that the US would enter the war too late this is clearly desperation.
The High Command was being desperate: hoping for the best: ultimately engaging in from Weber’s perspective in Ethic of Conviction. Everyone recognized that Germany would lose if Americans were involvement on the side of Britain this would further isolate Germany: Weber believed this would destroy any hope of equal peace negotiations. American entrance into the war would be a critical juncture.
The Memorandum March 10th, 1916: sent to the Foreign Secretary
Weber argued for the settlement of the crisis with the US in 1916 “at any cost.”
Weber has strong rational argument based on his subsequently theorized Ethic of Responsibility.
Weber believed that Britain would not capitulate. Tirpitz’s theory was wrong.
A) England’s early capitulation is unlikely; this was desperate thinking by the High Command.
B) America would enter the war giving complete support to the English before such capitulation.
C) In the longterm, Germany would lose economically despite even a military victory because the war would take longer to be resolved and drain the German people’s morale. Germany would forfeit its future as a world power if it did not negotiate an honourable peace.
Weber: End USW> US Neutrality> Speedy End To War> Honourable Peace Negotiations.
High Command: USW> English Capitulation > US Entrance > Speedy End to War > Victory.
Weber wanted to counteract public opinion by making the memorandum rather stern.
Weber was a Bethmann-Hollweg supporter….
By the end of 1916 Socialists in Germany were against unrestricted warfare. The chief of the admiral staff Admiral Holtzendorff said that if we resume unrestricted submarine warfare Britain will be on her knees in 5 weeks. Cappelle Chief of the Naval Office (succeeded Tirpitz). They wanted to force a decision on the war before the Americans became involved.
July 1917: The Submarine Warfare miscalculated on existing British tonnage. Everyone knew that the British had more than their own shipping capacity. German predictions were based on erroneous calculations. In the Reich>The Three Parties formed a government: Centre, Progressives and Socialists (large faction) the three together had a majority in the Reichstag. They discussed the peace issue. Which resulted in the Peace Resolution. Bethmann’s position becomes untenable: he agreed to submarine Warfare and now it was clear that it was not succeeding. It was based on fraudulent calculations.
Hindenburg and Ludendorff said if you keep Bethmann Hollweg we will resign. These two men were soldiers had turned against Bethmann. Kaiser didn’t say that Bethmann was fired for being wrong. Kaiser had lost all power and did whatever Hindenburg and Ludendorff wanted. 13th of July 1917 Bethmann was dismissed. Hindenburg and Ludendorff had destroyed Bismarck’s constitution where the Emperor should be able to control the chancellor.
(GPM3) German morale & political cohesion: U-Boat was the trumpcard, a significant advantage, if it didn’t achieve what it was supposed to then there was no other cards to play. The domestic crisis would be a revolution. Weber was right. The act of desperation of USW would have negative effects on the Morale of the German people
For Weber, the Dangers of US entrance was not as bad as the domestic response to USW’s failure. Weber opposed the Right’s agitation aimed at pressuring the chancellor to permit ruthless use of submarines. It was hysteria fuelled by alarmists. Weber believed American entrance was the least desirable outcome, the optimal outcome would be American neutrality and quick peace negotiations. Weber disapproved of USW because this idea of “the fear of peace”: creating high expectations: U-Boats was a trumpcard, a significant advantage, if it didn’t achieve what it was supposed to then there was no other cards to play. The domestic crisis would be a revolution. The act of desperation of USW would have negative effects on the Morale of the German people. So he is consistent in his position of maintaining a German morale and cohesion so as to achieve an honourable peace.
So he is consistent in his position of cohesion as long as you agree with his rational framework which is elucidated in (Politics as Vocation, 1919).
CRITIQUE OF WEBER’s Argument
1) TAUTOLOGY of His Argument:
(a) His war aims and foreign policy prescription are for a more realistic positive peace negotiations: he was wrong about closing off the borders to Polish workers and agricultural restructuring, what about his ER then? Was it that Weber took the side that won? HOWEVER this is all given the outcome of the war which no one knew at the time. Any rational systems employed could be confused in the fog of war given the level of uncertainty/limited information.
(b) I argue that, Weber took the side that won. Because Weber supported the rational ideas that seem to be correct: we cannot test their validity since the outcomes have occurred: ex post analysis.
(c) It ONLY seems that Weber is more rational than the High Command for assuming that the US might stay out of the war. Claiming Weber is a better nationalist is easy after the fact because not having US in the war would have allowed for honourable peace negotiations instead of one sided and unfair negotiations.
Weber assumes that Germany is already in a bad position: The key is that Weber accepts Germany can’t gain anything from the war before anyone else….
Weber’s position allowed him this claim while politicians have to manage the Blood Vengence of the people: Weber’s modest War AIMS: It is difficult to convince the military and public to not maximize the use of a strategic advantage. It is also difficult to convince the military and public that the deaths of countless soldiers is not for anything more than returning the borders to their original boundaries. In order for Weber to be taken seriously, one would have to ignore the emotional power of war on peoples decision-making.
Weber’s Position: there is a nuance here, however, the difference lies in the assumption of how other actors would react. Weber didn’t believe that America would inevitably enter the war: Weber was hoping for pacifist elements in America to succeed.
High Command’s Position: seems to assume that US would eventually enter on the side of the British NO MATTER WHAT….their assuming that the US would inevitabtly enter the war led to the Zimmerman Telegraph: this is what led to American entrance. The US was inevitably going enter on the side of the British.
3) COUNTERFACTURAL ARGUMENT: What if we did a counterfactual showing that America did not enter the war & England capitulated. Weber would have been wrong about this issue. Weber correct in believing any unrestricted submarine warfare would be have devastating effects on the domestic situation.
Must REMEMBER THAT many people believed that the US would enter the war: they assumed that in using Unrestricted Submarine Warfare.
Weber’s War Aims: peace with honour/principled policies.
Is Max Weber less of a nationalism than those in High Command? What is distinctive about Weber’s Nationalism in WWI?
HIGH COMMAND WAR AIMS:
According to Fischer 1961 thesis, The German War aims were annexation of A-L, French war armament prevention for 20 years, Iron ore areas of Brie and Lorie, Belgium and Poland as a Buffer against the Russian Empire. There is some dispute over Bethmann-Hollweg’s views: he was moderate on annexation according to Mommsen. The Supreme Command of the German Army is the government. They are who I compare Weber’s war aims against.
War Aims are never static for Weber (Breuilly, seminar)
Weber is better able to detach emotionality from his rational means than the High Command who must mobilize society to fight for a glorious cause.
Weber is consitent and rational throughout his argumentations regarding the war.
War Aims & Max Weber’s Nationalism in Question
There is a debate about what exactly were the High Command and Bethmann Hollweg’s war aims but according to F. Fischer’s 1960 thesis on The September Memorandum of War Aims, The German War aims were far reaching annexation of A-L, European economic union under Germany, Iron ore areas of Brie in France, Belgium and Poland as annexed buffers against the French and Russians respectively. This is what I compare Weber’s war aims against. The primary objective of any war for Germany was annexation.
The Administrations War Aims are unrealistic ends for Weber. I argue they are used to mobilize the masses, galvanize the soldiers. These War Aims justify Germany’s involvement in the war for a majority of Germans. Weber believes that such a position is detrimental to his conception of Germany’s future because those war aims are untenable and will destroy Germany’s economic future. He wants in essence simply the honourable survival of the German Reich once the war begins.
Weber’s German Future World Policy is focused on Long-term Objectives contradicting Administrations Short-term gains: Need for a honourable meaningful ‘negotiated peace’ thereby avoiding humiliation and the end to German world power.
Failure of Diplomacy: war would not produce real successes or acquisitions. Germany had failed to avoid war against a ‘world coalition’.
Anti-Annexation: for instrumental as well as nationalist purposes.for instrumental purposes of peace negotiations. Germany should not attempt to acquire new territorial acquisitions. Also annexationism would exacerbate the Alsace-Loraine problem which Weber believed should be resolve through German annexation of Alsatians <- seems to signify Weber’s ethnic nationalism based on language claims.
The preservation of military security in the East and West.
Importance of winning the peace by speedy conclusion of the hostilities: Germany must be economically strong in the long-term. Need for ‘negotiated peace’ and an honourable meaningful peace.
Fear of diplomatic isolation: wants flexibility to create further future alliances. Failure of Diplomacy: war would not produce real successes or acquisitions. Therefore Germany needs constitutional reform through democracy in order to cultivate proper political leadership.
Weber was no warmonger: he wanted a speedy end. The primary arguments focus on Weber’s concerns regarding Germany’s economic strength after war. Believing that even if Germany won the war they could still lose the peace economically.
According to Mommsen by 1916, Weber had ‘dissasociated himself from the ‘ideas of 1914’.
Weber’s Three Lessons:
economic interest didn’t cause the war, but they had produced new economics interests (war mongers industrialists), which pressed for continued prosecution.
Indispensability of industry and business for the war effort.
The State is the highest organization of power in the world; it has power over life and death. The error is that such discussions turn exclusively around the state and do not take the nation into account.
War Aims is Weber’s ultimate end NOT PROFIT>
Weber believed that “a correct relationship between state and nation, where the state = power and the nation = culture and language….It was therefore unwise to annex great peoples with strong national cultures.”(Mommsen, 1984)
Belgian Annexationism…. Bismarck’s Foreign Policy and the Present (1915), Weber opposed a boundless annexation program. Lack of realims in an annexation policy of the west. The Article outlines the long-term effects of annexation propaganda on public opinion: as soon as it was apparent that such unrealistic goals could never be achieved, disillusionment would become widespread and the fighting spirit would dissipate. “THE fear of peace” led to unlimited multiplication of war goals.
Weber opposed annexation of the West 4 Principled Reasons:
Turning England and France into long-standing enemies of the Reich. Instead, Weber viewed Belgium (along with Kurt Reizler) as a pawn in German negotiations with the Triple Entente. His policy was focused on security considerations. Weber’s proposals were unusually clear sighted according to Mommsen as the High Command wanted to annex Belgium into the Reich with resettlement plans for non-Germans…(209pp, Mommsen).
Anti-cultural Integrationist (erode the German state): it would not work for nationalist reasons; that underlies Weber’s arguments in German politics: He believed that an independent people could be integrated in the Reich successfully. The optimal objective for Weber was a permanent military occupation of Luxembourge and 20 year guarantee of active neutrality by the Belgian state toward France. I argue he’s interested in maintainin the integrity of the German Nation-State as a Central power with little subordinate cultures orbiting the pure German centre. Did not want to engage in culturally integrating Belgium.
Russia is the ultimate threat to Germany not the Anglo-Saxons: hence his position on Polish self-determination during the war. He is preoccupied with the situation of the Poles. Weber wants a Central European hegemon: Naumann’s Mitteleuropa is scrutinized by Weber as “stupid” because nation-states would not be able accommodate diverse policy objects. He did not believe in equality but in hierachical political sphere under Central Power dominations.
Annexationism of Belgium would exacerbate the Alsace-Loraine problem.
NOT IMPORTANT FOR Week 8 Questions….
Weber + Soveriegnty – Associations with Eastern States.
Germany should liberate all the small nations from the yoke of greater Russian despotism. Hoped for Polish, Lithuanian and Latvian and Ukrainian national state, far-reaching automony but association with the German Reich.
Reich would continue with its fortification as well as Austria-Hungary in the south. Weber wanted a tariff union with Lithuanian, Latvia, and Poland that would tie these state economically to the Reich.
Kurt Reizelr’s German imperialism is similar “ with a European appearance: hegemony through indirect means, especially through the establishment of amiddle European tarrif and economic union.
WEBER’s concept was distinct insofar as it emphasized a liberal approach and was oriented primarily to the east. Even if it was in the east it would have centralized power in Central Europe.
Weber’s Public Meeting in Nuremberg : Deutscher Natialn-Ausschuss.
A) attacked German war enemies.
B) against Belgium annexation detrimental to Germany’s future foreign policy requirements: need for Belgium neutrality guarantees that was genuine.
C) necessity of a free Poland preferably within the framework of an ‘indissoluble, permanent [central European] union of states with a common army, trade policy and tariffs”. !!! <- essential goals of a peaceful order for all of Europe. All nations arranged around the German empire as a central core of power.
March 3, 1918 Treaty of Brest-Litovsk: Germany took large tracts of Russian territory. Poland taken largely by German. Germany helped Finland fight off the Russians. Strong friendship with Finland. Russia had substantial losses of territory.
Both sides, Germany and Russia recognized the principle of national self-determination. Soviet interpretation 12 of May 1917 regarding the right of national self-determination: Resolution: “The right of nations to succeed freely must not be confused with the separation of this or that thing. The party of the proletariat of each nation should be soviet.”
Weber’s dislikes Matthias Erzberger:
(GPM4) Erzberger’s Peace Resolution: in July of 1917: revealed German weakness during his speeches to justify the peace. When Erzberger proposes Peace Resolution between Social Democrats and other parties, he highlights German weakness: Weber calls him an ass. Weber was against Tirpitz’s resignation despite his USW objectives. He argues that Reich should not be revealed to be weak by the politically influential. He is torn between being political cohesion & rational realistism of his academic mind. He IS NOT just being pragmatically incoherent: there is a method to the madness.
November 11th 1918: Erzberger signs the Armistice: it is the great stab in the back by the German SPD: he is assasinated in 1921 for signing the Arministice. Weber celebrated his death. Rathenau was assinated a year later.
THE REASON he rejects Erzberger: THE IMPACT upon the ALLIES. “Abroad, they suspect weakness to be the reason for the democratic confessions of faith and they hope for more: revolution. This will extend the war” (258pp, Mommsen).
(Mommsen, 1984) believes that Weber overestimated the prestige factor in the international power game. Domestically, Weber favoured democratization in order to strengthen the home front. But when a Reichstag majority united in a decisive declaration for peace, he judged it to be a sign of weakness to those outside of Germany. As a result, Weber ended up in SELF-CONTRADICTION.
Weber wanted 1) free economic development of Germany 2) preservation of national existence.
Weber shifts back to a focus on world religions.
Conclusion:
Why is Max Weber IMPORTANT; SO WHAT? WHAT DOES THIS SAY about Nationalism Studies?
Weber chooses his own end and serves that end (nationalism). We can only choose things that are culturally significant to us.
Therefore Weber is a better nationalist than the High Commanders. Weber is an instrumentalist because he is preoccupied with long-term cohesion of a strong German state. While the High Command is setting unrealistic goals that would only weaken Germany’s world policy in the longterm. Weber’s political goals appear to be more nationalist because they are superior in that they rationally deduced to achieve a moderate realistic end for Germany. The high command set expectation too high harming political cohesion and morale.
CONCLUSION Thesis:
Weber’s argues for his ultimate value: preservation of German world power.
Weber’s policy prescriptions are formulated to justify that ultimate value using the most rationally efficient means given available information.
Weber is better able to detach emotionality from his rational means than the High Command who must mobilize society to fight for a glorious cause.
[1] Joachim Radkau, Max Weber: Die Leidenschaft des Denkens, (München, 2005), pp. 699
[2] Wolfgang Mommsen, Max Weber and German Politics, 1890 – 1920, (Chicago, 1984), pp.191
[6] Weber considered Russia to be Germany’s eternal antagonist. See Mommsen, pp. 204.
[7] See David Stevenson, ‘The Failure of Peace by Negotiation in 1917’ Historical Journal Vol. 34:1 (1991), for more on the peace feelers which surfaced during the course of the war.
[8] Wolfgang Mommsen, Max Weber and German Politics, 1890 – 1920, (Chicago, 1984), pp. 257
[9] Joachim Radkau, Max Weber: Die Leidenschaft des Denkens, (München, 2005), pp. 75
[10] He states this most clearly in a speech given to Austrian officer in Vienna in June 1918.
The following is a synopsis of Factfulness by Hans Rosling. It’s a great read on the Ten Reasons We are Wrong About Everything and Why Things are Not as Bad as We Think
Introduction: Why I Love the Circus
Hans Rosling was a physician, academic and
public speaker. Together with his son, Ola Rosling and his daughter in law Anna
Rosling Ronnlund, he founded the Gap Minder Foundation in 2005 to fight
ignorance and encourage what he calls a more factful approach to life. Although
this book, like his TED Talks, was written in his voice it is a collaboration
between the three of them.
Although he pursued a career in medicine
and became a leading academic, Rosling’s true passion as a child was the
circus. He loved everything about it and was convinced he would one day live
his dream and run off to become a performer. His parents had other ideas; they
wanted him to enjoy the first-rate education they didn’t have and so he studied
medicine instead.
Hans Rosling actually swalllowing a sword
When studying medicine, he discovered he
could stick his hands down his throat further than anyone else. For a short time,
he dreamed once again of joining the circus as a sword swallower. Because
swords were in short supply, he decided to start with a fishing rod, but found
it impossible. It was only later, when treating an actual sword swallower, that
he learned the reason why he had failed.
The throat, he was told, is flat and can
only take flat objects. To his delight he discovered he could actually do it
and, later in life when he began giving talks, he often used it as a finale to
his act.
He talks about sword swallowing for a
reason. It’s one of those ideas which inspire people to think differently, to
question perceptions and, as such, to accomplish the seemingly impossible. This
is a key feature of the book.
Another is the continual need to test
yourself and question your assumptions. To illustrate he lists 13 questions:
How many girls finish primary
school in low income countries around the world?
Where does the majority of the
world’s population live: low income, middle income or high-income countries?
In the last 20 years, the number
of people living in extreme poverty has increased or halved?
What is the life expectancy of
the world today?
There are 2bn children aged 0
to 15 years old. How many will there be in the year 2100 according to the UN?
The UN predicts that, by 2100,
the world’s population will have increased by 2bn. Why is this: more younger
people or more older people?
How has the number of deaths
from natural disasters changed over the last 100 years?
There are 7bn people in the
world. Where do they live: mostly in Europe, Africa, Asia or America?
How many of the world’s
one-year old children today have been vaccinated?
30-year-old men have spent ten
years in school on average. How many years have women of the same age spent?
In the 1990s tigers, giant
pandas and black rhinos were all listed as endangered. How many are listed as
more critically endangered than they were then?
How many people in the world
have access to some electricity?
Over the next 100 years will
the average temperature get warmer, stay the same or get colder?
He sets these tests to people around the
world and the majority get them wrong. Our perception of the world is far
removed from the reality. His aim in the book is to give people the tools to
think in a factful manner, to challenge perceptions and understand the world
more completely.
Chapter 1: The Gap Instinct
Our world view is often distorted thanks to
the tendency to divide everything into two extremes with a space or a gap in
between. For example, we often view the world through the perspectives of
distinct groups such as ‘rich versus poor’, ‘us versus them’ or ‘developed and
developing countries’.
This is simple and makes it easy to develop
a view of the world, but he believes it’s wrong.
To demonstrate his point, he looks at our
tendency to divide the global population into developing and developed countries.
Those in developed worlds have better access to healthcare, live longer lives
and have better access to electricity, while those in the developing world do
not. However, the data shows that most people have access to all these things.
In reality, most countries fall into a gap
between the perceived developed and developing worlds, with many moving towards
the group of developed countries. As such, this divisive world view makes no
sense.
Instead, he introduces four categories
which can provide us with a better view of the world. These are:
Level 1: Earning less than $2 per day.
Level 2: Earning between $2 and $8 per day.
Level 3: Living off$8 to $32 per day.
Level 4: Bringing in more than $32 each day.
It doesn’t matter where you live in the
world; people in each group tend to have a similar quality of life. Those in
Level 1 suffer from poor nutrition, live hand to mouth and rely on walking to
get where they need to go. In Level 2 people are better off; they can feed
themselves have better access to electricity and education but they are not
secure. At any time, an emergency could see them slip back to Level 1. At the
top is Level 4 in which people can afford a car and an annual holiday.
This produces a more accurate view of the
world, one which divides people by quality of life rather than simply where
they are living. Even so, the traditional gap-based view of the world prevails.
To combat this, he cites a number of
warning signs which can encourage us to slip into the gap-based world view.
Comparing averages between
two situations. We forget about the overlap which
creates the illusion of a gap.
Comparing extremes: For example, thinking of the poorest versus the richest is wrong
because most people are in neither extreme.
View from above: People in higher income levels look down on lower levels without any
idea of the conditions in those levels. If you’re in Level 4, you might think
of people in levels 2 and 3 as being poor when in fact they have a much better
quality of life than you might think.
The reality of life is that there is no
gap. Most people exist in the middle where the gap is supposed to be. Thinking
about people in two groups distorts our view of the world. To form a fact-based
world view, we have to recognise that many of our perceptions are filtered
through mass media which loves to focus on examples which are extraordinary or
extreme.
“There is no gap between the West and the rest, between
developed and developing, between rich and poor,” Rosling writes. “And we
should all stop using the simple pairs of categories that suggest there is.”
Chapter 2: The Negativity Instinct
“The world is getting worse”. It’s a view
that we hear often and which, according to polls, most people share. However,
it is also wrong. In truth, the world is getting better. We simply don’t notice
when it does.
Most humans pay attention to the bad rather
than good. As such, they believe the world is only getting worse.
There is some truth in this. The
environment is deteriorating and terrorism is higher than it was 30 years ago.
Even so, the state of the world is generally improving. However, according to
Rosling, these improvements go unnoticed because they aren’t reported and we
look back at the past through rose tinted spectacles.
Instead, minor setbacks receive greater
coverage. If you look at the news, you’ll be forgiven for assuming that the
world is set on a downward trend. However, the facts tell another story.
In the 1800s most people in the world were
at income Level One. Extreme poverty was the norm for most people in the world.
Today, only 9% of the world is still at level one. Life expectancy has improved
from 31 years in the 1800s to over 70 years today. Slavery has been abolished,
child mortality is down; plane crashes, hunger and deaths in battles have
decreased. Access to electricity, water and health have improved.
Even so, the negative world view persists.
This view is caused by three things: mis
remembering the past, selective reporting and the feeling that it would be insensitive
to say things are getting better when they are still bad for many people.
When people start living better lives, they
can forget how bad things were. They romanticise their youth.
Most reporting is negative. Good news is
not news and neither are gradual improvements. A successful flight receives no
coverage, but a crash will be splashed across all media outlets.
Rosling suggests three ways to control this
negativity instinct.
Remember that ‘bad’ and ‘better’
are not mutually exclusive. Things can be bad but
they can also be better than they were before. Saying things are better should not
be confused with believing everything is fine.
Expect bad news. If we recognise that news is likely to disproportionately highlight
negatives, we can be better prepared for it. Factfulness is remembering that
most of the news which reaches us is bad news and there are plenty of positive
developments in the world which do not make headlines. More news does not
necessarily mean things are getting worse. It could equally mean that we are
getting better at monitoring this suffering, which in turn will make it easier
to alleviate it.
Avoid romanticising the
past. Life was not as good as we think it was, if
we present history as it was, we can realise that life, in general, is getting
better.
Chapter 3: The Straight-Line Theory
Life does not always work in a straight
line, but our thinking does. In this chapter Rosling examines our tendency to
assume a certain trend will continue along a straight line in perpetuity.
Reality is very different but our straight-line instinct stops us seeing life
as it truly is.
He talks about an Ebola outbreak in
Liberia. Like most people, he assumed the number of cases would continue in a
straight line with each person infecting, on average, another person. As such
it would be relatively easy to predict and control as most other outbreaks of
disease are. However, he came across a WHO report which said the number of
infections was doubling with each case. Every person infected two more people
on average before dying.
This spurred him into action. He discusses
an old Indian legend. Krishna is challenged by the King to a game of Chess and
asked to name his prize if he wins. Krishna asks for one grain of rice to be
placed on the first square with the number doubling with each square.
The King agrees assuming it will increase
in a straight line. However, it takes him a little while to realise that, by
the time it gets to the 60th square, he would have to find more rice
than the entire country could produce.
Many people assume the world’s population
is increasing. If nothing is done it will reach unsustainable levels meaning
something drastic must happen to stop this tend getting any worse. However, UN
data shows the rate of population increase is slowing. As living conditions
improve, the number of children per family is falling. Instead, growth can be
controlled by combatting extreme poverty.
Rosling uses the example of a child. In their
first few years, babies and toddlers grow rapidly. If you were to extrapolate
that growth for the future, ten-year olds would be much taller than they are.
Of course, we know that doesn’t happen because we are all familiar with how the
rate of growth slows over time.
When faced with unfamiliar situations, we
assume a pattern will continue in a straight line. Instead, he suggests we
should remember that graphs move in many strange shapes, but straight lines are
rare. For example, the relationship between primary education and vaccination
is an S curve; between income levels in a country and traffic deaths is a hump
and the relation between income levels and number of babies per women is a
slide.
We can only understand the progression of a
phenomenon by understanding the shape of its curve. Assuming we know what will
happen leads to erroneous assumptions and false conclusions which will in turn
lead to ineffective solutions.
To control the straight-line instinct, we
must remember that curves come in many forms and we will only be able to
predict it when we understand the shape of its curve.
Chapter 4: The Fear Instinct
“Critical thinking is always difficult,” writes Rosling, “but
it’s almost impossible when we are scared. There’s no room for facts when our
minds are occupied by fear.”
This is why the ‘fear instinct’ can be so destructive. When
people are afraid, their ability to tell fact from fiction falls off
dramatically. Factfulness demands that we control our fear.
Never before has the image of a dangerous world been
broadcast more widely and more effectively than it is today. We are frightened
of almost everything, but the truth of the matter is that the world has never
been safer or less violent.
Rosling starts the chapter by looking back
to an old story from his days as a junior doctor. It was 1975 and news came in
of a plane crash. The survivors were being rushed to his hospital; senior staff
were at lunch which would leave just him and a nurse to handle the situation.
It would be his first emergency and, in his
panic, he confused one of the survivors for a Russian pilot and became
convinced Russia was attacking Sweden. He mistook a colour cartridge for blood
and was narrowly stopped from shredding through a G suit worth thousands of
dollars.
Fear stopped him from seeing the situation
for what it was. Our minds have an attention filter which decides what reaches
it. This is the useful. The word contains vast amounts of information and we
have to filter it to avoid overload. However, what gets through tends to be the
unusual or scary.
This is why newspapers are full of events
which are frightening. However, the more of the unusual we see, the more we
become convinced the unusual is actually the norm. Our fear instinct has been
baked into our minds by millennia of evolution. Fear kept our ancestors alive,
but even though many of these dangers have gone, the perception remains.
The dangers are more real for people in
Level 1 and 2 income categories because they are more likely to suffer threats.
For example, they might be more likely to be bitten by a snake which might make
them jump if they see a funny shaped stick. However, for people in higher
income levels, being bitten by a snake is much less likely. Even if they were
to be bitten, they have access to good healthcare.
For them, the fear of the snake does more
harm than good. Newspapers know these fears are hardwired into our brains so
they use it to grab our attention. The same fears which kept our ancestors
alive are keeping journalists employed today.
This GOES East satellite image taken Tuesday, Sept. 11, 2018, at 10:30 a.m. EDT, and provided by NOAA shows Hurricane Florence in the Atlantic Ocean as it threatens the U.S. East Coast, including Florida, Georgia, South and North Carolina. Millions of Americans are preparing for what could be one of the most catastrophic hurricanes to hit the Eastern Seaboard in decades. Mandatory evacuations begin at noon Tuesday, for parts of the Carolinas and Virginia (NOAA via AP)
The number of deaths from natural disasters
has fallen as countries develop better healthcare and infrastructure. Organisations,
such as the WHO and UN, help victims in these situations but people in Level 4
aren’t aware of their success because the media reports it as the most serious
disaster in history.
It is important to look at things with a fact-based
approach to make better use of resources. For example, the 2015 earthquake in
Nepal which killed 9,000 people attracted global attention, but diarrhoea from
contaminated water kills 9,000 children each year but receives very little
attention in comparison.
2015 was the safest year in aviation
history but this fact was not reported. The number of deaths from battle has
fallen and so has the threat of nuclear war. All these good pieces of news slip
under the radar.
Following the Tsunami in 2011, 1,600 people
died escaping Fukushima while nobody died from what they were running away
from. Fear of chemicals such as DDT leads to deaths which could have been
treated by DDT. The fear of an invisible substance leads to more harm than the
substances itself.
Terrorism causes fewer deaths than alcohol
but receives far more publicity.
Fear is a terrible guide for understanding
the world. We pay attention to things we are afraid of but ignore things which
can do us harm. Factfulness is knowing how to tell the difference between
actual risks and perceived risks.
Chapter 5: The Size Instinct
From immigration to the number of deaths in
hospitals, we consistently overestimate size. In this chapter, Rosling shows
how this leads to a distorted view of reality and warps decision making.
He starts by going back to his time as a
young doctor in Mozambique in the 80s when it was the world’s poorest country.
One in 20 children died. He argued with a friend about the standard of
treatment at the hospital. He felt they needed to provide better care outside
of the hospital, but his friend believed he should concentrate on improving
care within the hospital.
He decided to look at the number of
children who died in the hospital compared to those who died outside. To his
surprise he found that, while deaths were comparatively low inside the
hospital, over 3,900 people died in the community. He therefore decided to go out
into the community to provide better care to people who couldn’t get to the
hospital.
When looking at a single number in isolation,
it is easy to give it too much importance. For example, when he saw he was
saving 95% of the children who came to the hospital it was easy to assume he
was doing a great job. However, when he compared it to those who were outside
the hospital, he realised he had to do more.
Journalists always give us numbers and
exaggerate their importance. It leads to solutions which do not help. At the
hospital, people would have assumed increasing the number of beds would reduce
deaths but, with more information at their disposal, they realised the best
path was to improve the levels of care and education within the community.
To avoid the trap of the size instinct, he
recommends using the tools of comparison and division.
For example, two million children died
before the age of one in 2016. This seems high until you compare it with 1950s
number when 14.4 million children died before their first birthday. Infant
deaths are falling, but you wouldn’t know this if you only looked at the first
figure.
A Swedish hunter killed by a bear received
more coverage than a woman killed by her husband. The first incident was a
freak event; but it received far more coverage than the second which is a far
more common and serious risk. Rather than being concerned by domestic violence,
the media became obsessed with an event which is unlikely to happen again for many
years.
Another example comes from the Swine flu
epidemic which killed 31 people in 2 weeks. However, 63,000 people died from TB
in the same period, but it received no coverage.
The lesson is that we tend to over state
the unusual and ignore issues which are far more common. It distorts our world
view and leads us to make poor decisions. Factfulness is understanding that
just because something is more widely reported, doesn’t make it more common.
Chapter 6: The Generalisation Rule
As humans, we love to categorise and
generalise everything. While this can help us to simplify our view of the world,
it can also lead to distortions. Attributing one characteristic to an entire
group based on one unusual example leads to serious misconceptions and can have
quite serious consequences.
As he writes, the generalisation instinct “can make us
mistakenly group together things, or people, or countries that are actually
very different. It can make us assume everything or everyone in one category is
similar. And, maybe most unfortunate of all, it can make us jump to conclusions
about a whole category based on a few, or even just one, unusual example.”
For example, he begins the chapter by
talking about his experiences working in the Congo when he was presented with a
less than appetising dessert made from lava. To avoid eating it, he tried to
convince them that it was against Swedish custom to eat lava.
Generalisations, he says, are mind
blockers. They create a distorted view of reality and often lead people to miss
important opportunities. For example, after polling financial experts, he says,
he found that they assumed most children in the world were not vaccinated
before the age of one. In fact, the vast majority are. For that to happen,
countries need a lot of infrastructure, which is also the same kind of
infrastructure which is required for factories and other forms of enterprise.
Statistically Valid Things
The belief persisted because these
financial experts believed the images of extreme poverty presented about some
countries in the media. As such, these experts were potentially missing out on
investment and business opportunities because they believed these countries
were more deprived than they were.
To combat the generalisation instinct, he
suggests travelling. This helps you to get out into the world and gain first-hand
experience of cultures as they actually exist, rather than the way they are
portrayed in the press.
As with other chapters, questioning is
vital. You should always question the different categories you are given. Look
for similarities across and within groups; remember to be suspicious of
generalisations and to be aware when you are generalising one particular group
from another.
Many people generalise African countries
but they are not all at the same level of development. This has enormous
consequences. The Ebola epidemic in Liberia affected tourism in Kenya even
though the two countries are thousands of miles apart.
Majority is an extremely blunt concept. It
can be anything between 51% and 99%; which does not produce a realistic picture
of any situation.
Examples give a poor picture. Many people
around the world suffer from chemophobia, the fear of chemicals, when in
reality most are beneficial.
Folders Icon with variations of colors
Assuming you are normal can lead to you
generalising others and failing to understand the reasons behind their actions.
What is normal to you is not necessarily normal to other people.
Factfulness is recognising what categories
are used and keeping in mind that these categories can be misleading. While
humans categorise and generalise everything, this can lead to stereotypes which
can lead to poor solutions. By travelling and questioning assumptions, you can
combat the problems caused by the generalisation instinct.
He also focuses on what he calls the 80/20
rule. We should always look at items which take up more than 80% of the total.
Looking at the world’s energy sources, for example, you might feel they seem
equally important, but only three generate more than 80% of the world’s energy.
Divide it by a total to get a clearer idea
of the situation. If you look at the total emissions produced by each country,
it might seem that China and India produce more Co2 emissions than Germany and
the USA, but if you divide it by the population, you’ll see that USA and
Germany produce more emissions per head than either China or India. A single
number does not provide a clear picture of any situation.
Chapter 7: The Destiny Instinct
When Rosling gave a presentation to a group
of capitalists and wealthy individuals about the opportunities of emerging
markets in Asia and Africa he was surprised by their reaction.
At the end of the talk he was approached by
what he describes as a ‘grey haired’ man who told him, in no uncertain terms,
that there was no chance that African countries would ever make it. Despite all
the positive data about economic progress he’d seen in the presentation, this
man believed there was something about African society which meant they were
destined to be poor.
This is an example of the destiny instinct
and its roots go back to the earliest history of man. As humans, we often
assume that a nation, group or culture’s destiny is determined by general
characteristic which we believe it shares. For example, white Europeans are
destined to be developed and wealthy while black Africans will always be poor.
This attitude persists even in the face of
contradictory data. Not only do people believe it to be true, but they assume
there is nothing that individuals in this culture can do to change things.
Destiny, as they say, is all.
The instinct stems from evolution when
people lived in small groups and didn’t travel very far. It was safer to assume
things would stay the same as they wouldn’t need to constantly evaluate the
surroundings. It’s also a great way to unite a group.
However, today’s societies are constantly
changing. These changes occur gradually which gives the perception that things
are staying the same. As such, gender equality is perceived to have remained unchanged
around the world, but in reality, things have largely improved.
There is also an idea that Africa is
destined to remain poor. However, most African countries have reduced their
infant mortality rates faster than Sweden did. Asian countries have moved into
the category of developed nations and many countries have escaped extreme
poverty.
It was also assumed that the number of
babies a woman has would depend on her religion. Religious women were more
likely to have babies than those with no religion. However, careful analysis of
data shows that the number of babies depends not on religion but income levels.
Other examples include the rise of support
for women’s rights and liberal ideas in Sweden. Concepts which might have been
far from the mainstream in the past are now commonly accepted.
To control the destiny instinct, you should
recognise that:
Slow change does not mean no
change at all.
Be ready to update your
knowledge. Knowledge is never constant in the social sciences.
Collect examples of cultural
change.
Factfulness is the art of recognising that
many things appear to be static just because change is happening more
gradually. Groups are not defined by their innate characteristics and, just
because something has been true once, it doesn’t mean it is set in stone for
the future. Like many of the other attitudes discussed in this book, the
destiny instinct is hard coded into our evolution, but while it might once have
been helpful for our ancestors, it is holding us back today.
Chapter 8: The Single Perspective Instinct
We live in a world in which many people
have strong opinions. However, when these opinions are set into a single world
view, we can become blind to any information which contradicts us. This is the
problem of the single perspective instinct and it can make it very difficult to
understand reality.
“Being always in favour of or always against any particular
idea makes you blind to information that doesn’t fit your perspective,” writes
Rosling. “This is usually a bad approach if you like to understand
reality.”
The single perspective instinct can be
alluring. It is the preference for simple explanations and simple solutions to
the world’s problems, but life is somewhat more complicated. This single cause
and solution view creates a completely warped view of the world.
There are two main reasons why we do this:
professional and political bias. Professionals will always see the world from
the perspective of their own expertise. A hammer will see everything as a nail
and will probably adopt the same approach. Even experts in their field can be
wrong.
A poll of women’s rights activists found
that only 8% realised that 30-year-old women have spent only one year less in
school on average than men. They were so intent on seeing the situation as bad
that they ignored the progress their own efforts have brought about.
He warns against relying the media to form
a world view. It’s like forming an impression of a person just from his or her
feet. The foot is far from the most attractive part of the body, so it doesn’t
give you a fair representation of the rest of the person.
In the same way, the media tends to present
the worst of the world; the disasters, the catastrophes and the crime. If you
form your world view based on media reports, you’ll imagine the situation is
much worse than it actually is.
Campaigners often paint the world as
getting worse, but they are not aware that progress happening. If they ditched
the attitude that things are only getting worse, they could garner more support
for their cause.
People love the idea of being able to point
to a single cause and single solution. For example, many use numbers to
illustrate all sorts of issues, but they do not always represent the best
solution. They do not help you to understand the reality behind them.
He recalls a conversation with the Prime
Minister of Mozambique who said he believed the economy was making progress. Rosling
argued that the data did not show this, but the Prime Minister replied that he
did not solely rely on numbers to measure progress. He’d look at the shoes
people wore and construction projects taking place. If the shoes were old, it
meant that people didn’t have money to replace them. If construction projects
were overgrown with grass, it suggested there wasn’t enough money being
invested.
There is never a single explanation to any
situation. It limits your imagination. Factfulness is realising the limitations
of this perspective and finding ways to view situations from a wider range of viewpoints.
This will help people to develop a more accurate understanding of the world
they live in and to challenge their own world views.
Chapter 9: The Blame Instinct
We live in a culture which loves to
apportion blame. This instinct assigns a clear cause to an event and finds
someone who was at fault.
It’s a comforting approach. When things go
wrong it is nice to think it’s because of bad people with bad intentions, but
that seldom tells the entire story. We attach a lot of importance to individual
groups or people, but it also stops us from understanding the world.
Once we find someone to blame, we stop
looking for the actual cause of the problem and focus on punishing the person
we think is at fault. The result is that we’re unable to prevent it from
happening again.
For example, we might want to blame a plane
crash on a pilot who falls asleep, but this does not stop another pilot from
falling asleep in the future. Instead we should be looking at why the pilot
fell asleep in order to stop it from happening again.
Hand in hand with the blame instinct comes
the tendency to credit someone for an achievement even if the reality is more
complicated. Someone has to take the blame or be given the credit. We love to
point fingers if it confirms our belief
Even Rosling himself is not immune. When
UNICEF hired him to investigate a company given a contract for malaria drugs,
he became convinced that the company was acting improperly. Even before he
finished his investigation, he started pointing fingers. In reality, the
company was honest but simply had an innovative business model.
The same principle is at work when looking
at the number of immigrants killed trying to cross the sea into Europe. It is
common to blame the smugglers who traffic these people across the sea in small
craft which are routinely dangerously overloaded. In reality, though, the
problem is Europe’s immigration policies which state that an airline which
brings illegal immigrants into the country will have to pay for their
repatriation.
Airlines will not be able to tell if
someone is truly an illegal immigrant in the few minutes they have before they
board a flight, so they will ban anyone who doesn’t have a Visa. This means
that refugees who have a right to enter Europe under the Geneva Convention
cannot do so by any legitimate means. They are forced into the hands of the
smugglers thanks to official European policy.
Any boats which bring refugees by sea are
confiscated by the authorities which is why smugglers turn to cheap dinghies
because they cannot afford to lose a larger boat.
On the other hand, we can also be in a rush
to give credit to a single person or law. China’s low birth rate is accredited
to Mao’s single child policy, but rates had started to fall before the law came
into force. Instead the decline was down to institutions and technology that
were in place.
Factfulness is the ability to recognise
when someone is being scapegoated and to understand that this stops people creating
viable solutions for the future. It is easy to look for a clear solution when
something bad happens, but it stops us developing a fact-based view of the
world and coming up with a solution which actually works.
Chapter 10: The Urgency Instinct
Rosling’s tenth and final instinct is one
which can bring all the others to the fore: the tendency to take urgent action
to solve a problem. While this might have served us well in the past, it can
cause us to make rash decisions based on incomplete information.
Doctors running for the surgery
The urgency instinct is embedded in our
evolution, and in times gone by, it has served us very well. For example, if
you think there is a lion in the grass you don’t want to spend time analysing
your options; you simply need to start running. It’s always the safest option.
It can also be useful today. If you’re
driving and someone slams on the brakes, you’ll have to take drastic action to
avoid a crash. However, in today’s modern world, it can often create problems.
While Rosling was a doctor in Mozambique, a
disease broke out that paralysed patients within minutes and sometimes caused
blindness. He wasn’t certain that it was infectious, but the Mayor didn’t wait
to find out. He ordered the military to set up roadblocks to prevent busses
reaching the city. To get around these roadblocks, women asked fishermen to
take them to the city by sea. It was a dangerous journey and many of these
boats were overloaded. They capsized and causes the deaths of women and
children.
After some research they discovered the
root cause was eating processed Cassava. So, while the Mayor believed his
prompt action was the safest approach, it actually caused a number of deaths
which should have been avoided.
Alarm clock on laptop concept for business deadline, schedule and urgency
The principal of ‘now or never’, causes
people to conjure a worst-case scenario. It kills the ability to think things
through and encourages bad decision making. This is why salespeople come up
with limited time offers. They are giving you a deadline and introducing a
sense of urgency into your decision making in the hope you’ll be rushed into
making a purchase.
To compel people to taking action, activists
will often try to trigger the urgency instinct. They will stress how urgent a problem
is and paint a worst-case scenario of what will happen if you don’t do
something now. However, Rosling believes this is counterproductive.
Fear and exaggerated data can numb people
to the risks campaigners are warning about which can lead to complacency and inaction.
For example, most countries say they are
committed to fighting a climate change but aren’t tracking their progress. It
begs the question: how can they truly fight climate change if they are not
tracking their progress?
Rosling tells us that the world faces five
serious risks: global pandemic, financial collapse, world war, climate change
and extreme poverty. The first two have happened before while the second two
are happening now.
They need to be approached with cool heads
and data analysis rather than sparking fear and urgency. It’s about crying
wolf. It can lead to these risks being ignored despite the dreadful
consequences. We must worry about the right thing.
The idea of factfulness is to remember that
things might not be as urgent as they seem. If you’re afraid and under pressure
to act quickly, you are likely to make bad decisions. We must take a breath,
take action based on data and be very wary of fortune tellers who insist they
know what’s going to happen. Although the world’s problems need to be solved it
is not always a good idea to take urgent or drastic measures.
Chapter 11: Factfulness in Practice
The final chapter brings everything
together and demonstrates how all the lessons explained so far can be put to
practical use. We see each of the ten instincts on show and how factfulness can
lead to truly positive real-world solutions.
To demonstrate, Rosling takes us to a
remote village in the DRC. He had travelled there to investigate a disease which
was caused by eating unprocessed Cassava. The villagers believed he was
collecting their blood to sell it and they were angry.
All the instincts discussed in this book
were on display. The sharp needles and blood had triggered the fear instinct. The
generalisation instinct made them categorise him as a plundering white man.
Blame instinct caused them to assume he had malicious intent and the urgency
instinct convinced them they had to act immediately, in this case by
threatening him with machetes.
Things might have worked out very badly for
both him and his translator if it hadn’t been for an old woman who successfully
calmed the crowd down and explained that he was trying to help them. Although
she was illiterate, she was bringing all the core principles of factfulness to
bear in a very dangerous situation. As such, she managed to save both their
lives.
In the same way we can bring it to our
daily lives, in business, education and journalism and communities. Children
should be taught to adopt a fact-based approach to life which will help them to
develop a better view of the world and create better solutions. Children should
be taught to be curious, to hold two different ideas at the same time. They
should be willing to alter their opinions with new facts. This will protect
them from ignorance.
Having a typo in your CV can keep you from
getting a top job. However, people who make policies are placing a billion
people in the wrong continent. Businesses have distorted world views and fail
to understand that markets are growing in Africa and Asia. Being an American company
is no longer a privilege which will automatically attract employees and
customers. If investors relinquish their preconceptions about Africa, they may
realise that it contains some of the best business opportunities in the world.
With a more factful attitude, journalists
may become aware of their dramatic world views and present something more
accurate and useful. However, it is a bit of a stretch to expect them to truly
embrace all the principles of factfulness and start reporting the mundane
alongside the unusual. The onus is on people to learn how to consume news in a
more factful manner.
If you are ignorant at the global level
there’s a good chance you’ll also be ignorant at the local level within your
own community, company or organisation. They are all using erroneous data to
manage their businesses and prepare for disasters.
Leaders in companies, cities, countries and organisations should carry out fact-based surveys to uncover ignorance within their organisations. Only by doing so can they develop a more accurate and realistic world view. Factfulness can be put into practice in all our daily lives, at home at work and in our communities.
This publication is dedicated to finance, politics and history